 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative Meta-Learning with Gradient Augmentation
Jun 07, 2024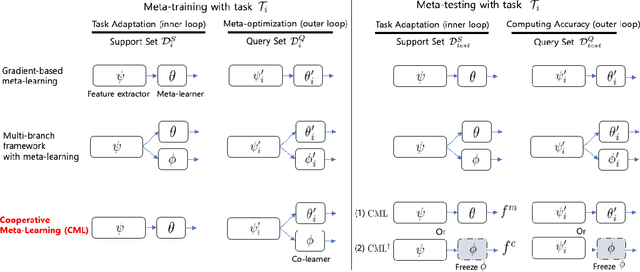
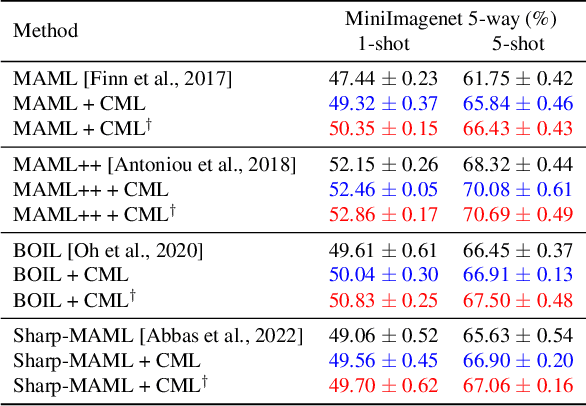
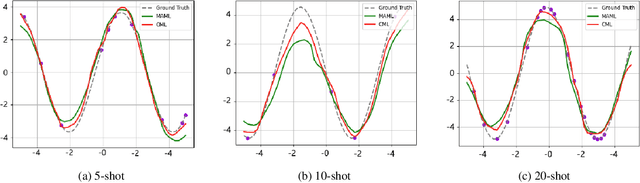

Model agnostic meta-learning (MAML) is one of the most widely used gradient-based meta-learning, consisting of two optimization loops: an inner loop and outer loop. MAML learns the new task from meta-initialization parameters with an inner update and finds the meta-initialization parameters in the outer loop. In general, the injection of noise into the gradient of the model for augmenting the gradient is one of the widely used regularization methods. In this work, we propose a novel cooperative meta-learning framework dubbed CML which leverages gradient-level regularization with gradient augmentation. We inject learnable noise into the gradient of the model for the model generalization. The key idea of CML is introducing the co-learner which has no inner update but the outer loop update to augment gradients for finding better meta-initialization parameters. Since the co-learner does not update in the inner loop, it can be easily deleted after meta-training. Therefore, CML infers with only meta-learner without additional cost and performance degradation. We demonstrate that CML is easily applicable to gradient-based meta-learning methods and CML leads to increased performance in few-shot regression, few-shot image classification and few-shot node classification tasks. Our codes are at https://github.com/JJongyn/CML.
Magnitude Attention-based Dynamic Pruning
Jun 08, 2023



Existing pruning methods utilize the importance of each weight based on specified criteria only when searching for a sparse structure but do not utilize it during training. In this work, we propose a novel approach - \textbf{M}agnitude \textbf{A}ttention-based Dynamic \textbf{P}runing (MAP) method, which applies the importance of weights throughout both the forward and backward paths to explore sparse model structures dynamically. Magnitude attention is defined based on the magnitude of weights as continuous real-valued numbers enabling a seamless transition from a redundant to an effective sparse network by promoting efficient exploration. Additionally, the attention mechanism ensures more effective updates for important layers within the sparse network. In later stages of training, our approach shifts from exploration to exploitation, exclusively updating the sparse model composed of crucial weights based on the explored structure, resulting in pruned models that not only achieve performance comparable to dense models but also outperform previous pruning methods on CIFAR-10/100 and ImageNet.
QTI Submission to DCASE 2021: residual normalization for device-imbalanced acoustic scene classification with efficient design
Jun 28, 2022
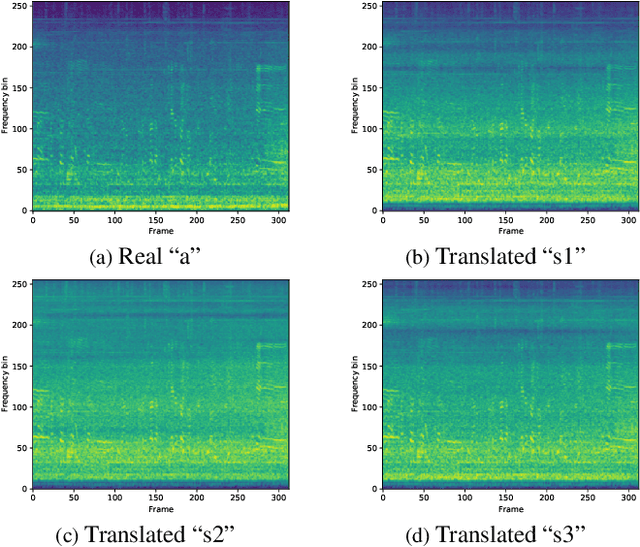
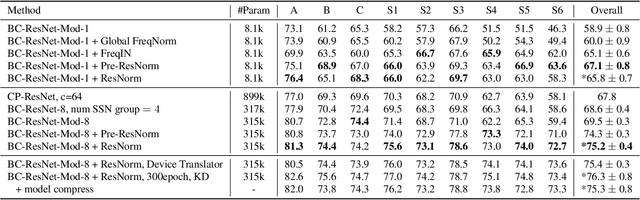
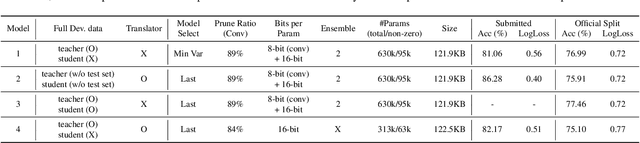
This technical report describes the details of our TASK1A submission of the DCASE2021 challenge. The goal of the task is to design an audio scene classification system for device-imbalanced datasets under the constraints of model complexity. This report introduces four methods to achieve the goal. First, we propose Residual Normalization, a novel feature normalization method that uses instance normalization with a shortcut path to discard unnecessary device-specific information without losing useful information for classification. Second, we design an efficient architecture, BC-ResNet-Mod, a modified version of the baseline architecture with a limited receptive field. Third, we exploit spectrogram-to-spectrogram translation from one to multiple devices to augment training data. Finally, we utilize three model compression schemes: pruning, quantization, and knowledge distillation to reduce model complexity. The proposed system achieves an average test accuracy of 76.3% in TAU Urban Acoustic Scenes 2020 Mobile, development dataset with 315k parameters, and average test accuracy of 75.3% after compression to 61.0KB of non-zero parameters.
Domain Generalization with Relaxed Instance Frequency-wise Normalization for Multi-device Acoustic Scene Classification
Jun 24, 2022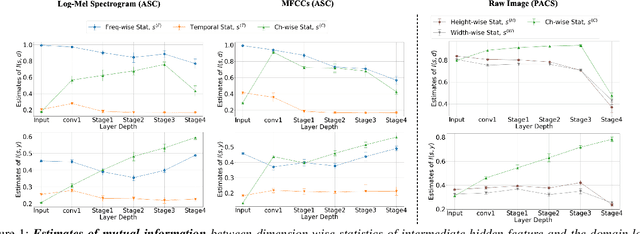
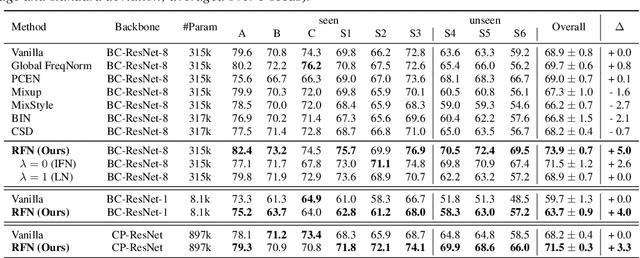
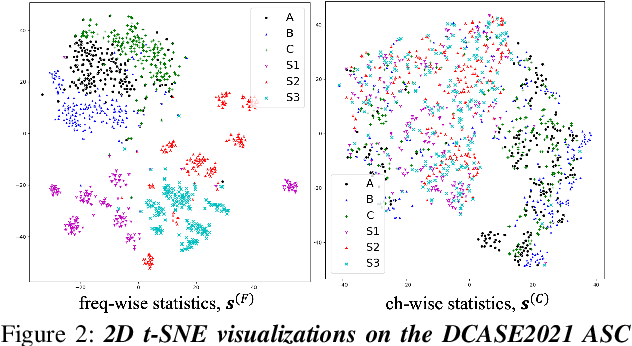
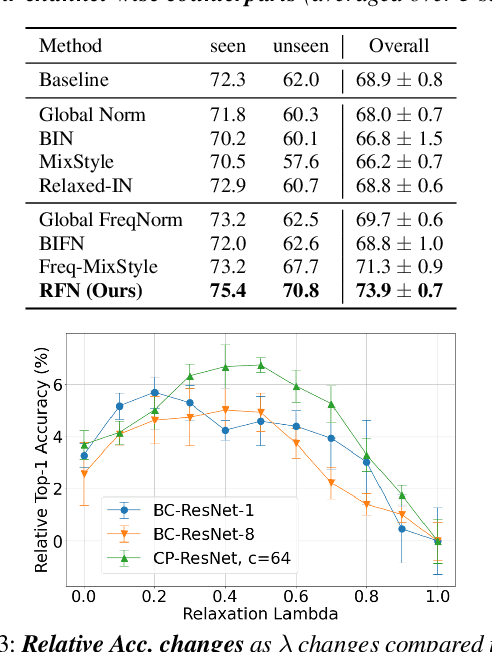
While using two-dimensional convolutional neural networks (2D-CNNs) in image processing, it is possible to manipulate domain information using channel statistics, and instance normalization has been a promising way to get domain-invariant features. However, unlike image processing, we analyze that domain-relevant information in an audio feature is dominant in frequency statistics rather than channel statistics. Motivated by our analysis, we introduce Relaxed Instance Frequency-wise Normalization (RFN): a plug-and-play, explicit normalization module along the frequency axis which can eliminate instance-specific domain discrepancy in an audio feature while relaxing undesirable loss of useful discriminative information. Empirically, simply adding RFN to networks shows clear margins compared to previous domain generalization approaches on acoustic scene classification and yields improved robustness for multiple audio devices. Especially, the proposed RFN won the DCASE2021 challenge TASK1A, low-complexity acoustic scene classification with multiple devices, with a clear margin, and RFN is an extended work of our technical report.
Detection of Word Adversarial Examples in Text Classification: Benchmark and Baseline via Robust Density Estimation
Mar 03, 2022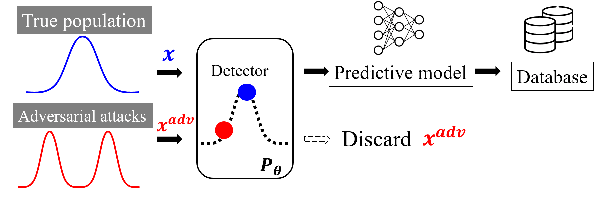
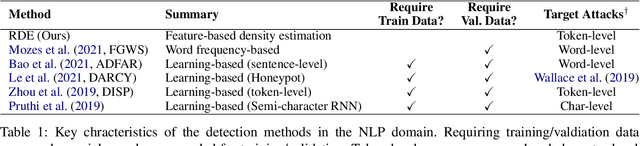
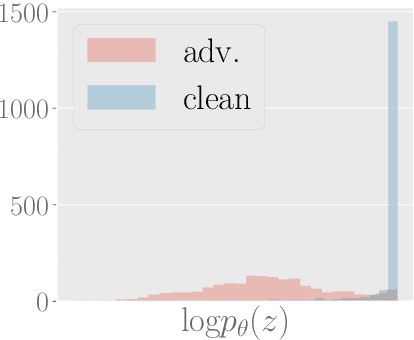

Word-level adversarial attacks have shown success in NLP models, drastically decreasing the performance of transformer-based models in recent years. As a countermeasure, adversarial defense has been explored, but relatively few efforts have been made to detect adversarial examples. However, detecting adversarial examples may be crucial for automated tasks (e.g. review sentiment analysis) that wish to amass information about a certain population and additionally be a step towards a robust defense system. To this end, we release a dataset for four popular attack methods on four datasets and four models to encourage further research in this field. Along with it, we propose a competitive baseline based on density estimation that has the highest AUC on 29 out of 30 dataset-attack-model combinations. Source code is available in https://github.com/anoymous92874838/text-adv-detection.
Self-Distilled Self-Supervised Representation Learning
Nov 25, 2021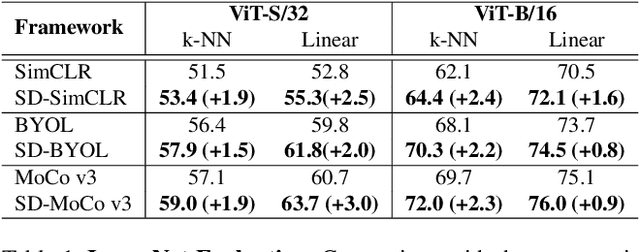
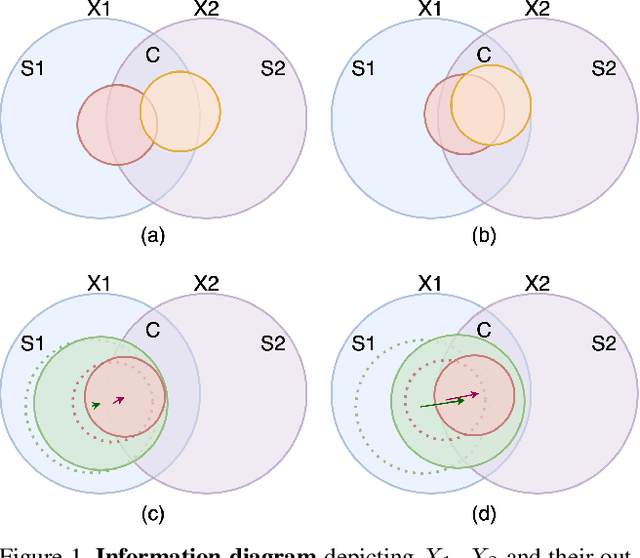
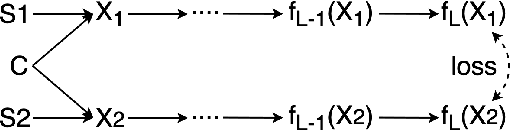
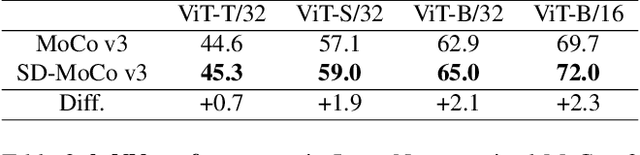
State-of-the-art frameworks in self-supervised learning have recently shown that fully utilizing transformer-based models can lead to performance boost compared to conventional CNN models. Thriving to maximize the mutual information of two views of an image, existing works apply a contrastive loss to the final representations. In our work, we further exploit this by allowing the intermediate representations to learn from the final layers via the contrastive loss, which is maximizing the upper bound of the original goal and the mutual information between two layers. Our method, Self-Distilled Self-Supervised Learning (SDSSL), outperforms competitive baselines (SimCLR, BYOL and MoCo v3) using ViT on various tasks and datasets. In the linear evaluation and k-NN protocol, SDSSL not only leads to superior performance in the final layers, but also in most of the lower layers. Furthermore, positive and negative alignments are used to explain how representations are formed more effectively. Code will be available.
Domain Generalization on Efficient Acoustic Scene Classification using Residual Normalization
Nov 12, 2021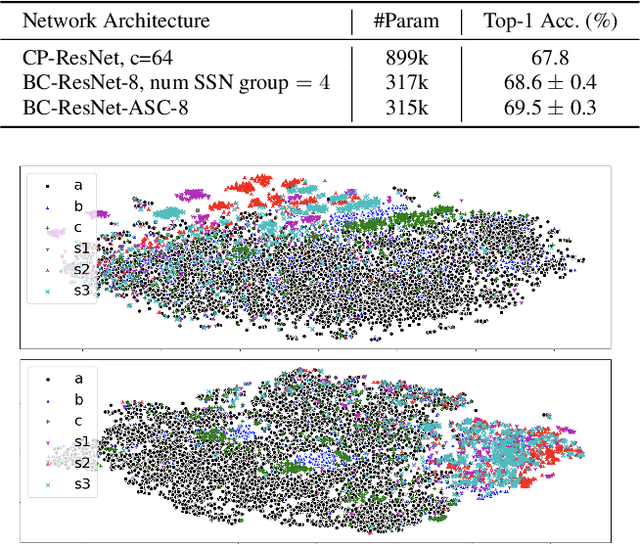
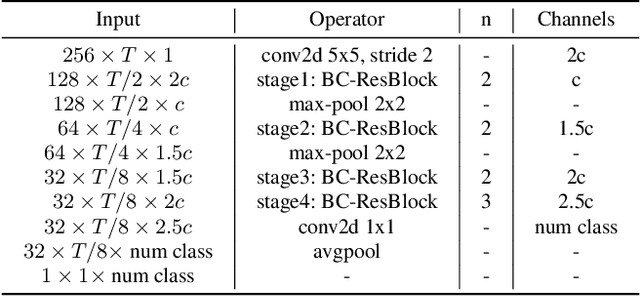
It is a practical research topic how to deal with multi-device audio inputs by a single acoustic scene classification system with efficient design. In this work, we propose Residual Normalization, a novel feature normalization method that uses frequency-wise normalization % instance normalization with a shortcut path to discard unnecessary device-specific information without losing useful information for classification. Moreover, we introduce an efficient architecture, BC-ResNet-ASC, a modified version of the baseline architecture with a limited receptive field. BC-ResNet-ASC outperforms the baseline architecture even though it contains the small number of parameters. Through three model compression schemes: pruning, quantization, and knowledge distillation, we can reduce model complexity further while mitigating the performance degradation. The proposed system achieves an average test accuracy of 76.3% in TAU Urban Acoustic Scenes 2020 Mobile, development dataset with 315k parameters, and average test accuracy of 75.3% after compression to 61.0KB of non-zero parameters. The proposed method won the 1st place in DCASE 2021 challenge, TASK1A.
Dynamic Collective Intelligence Learning: Finding Efficient Sparse Model via Refined Gradients for Pruned Weights
Sep 10, 2021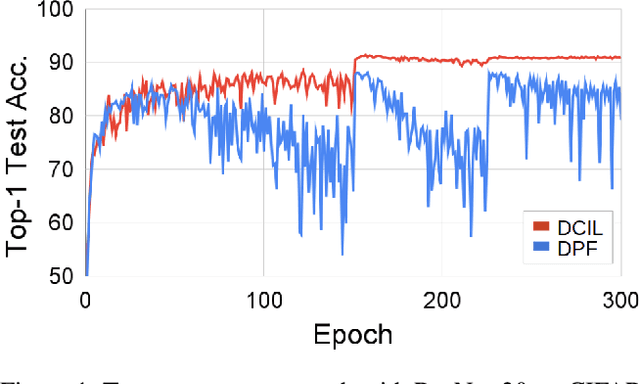
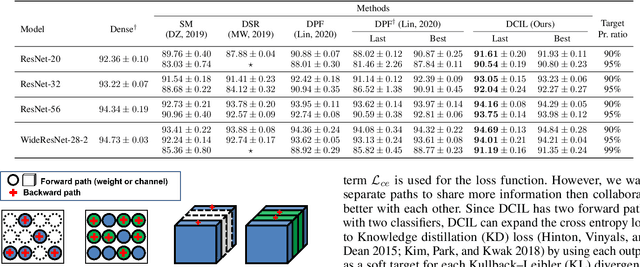
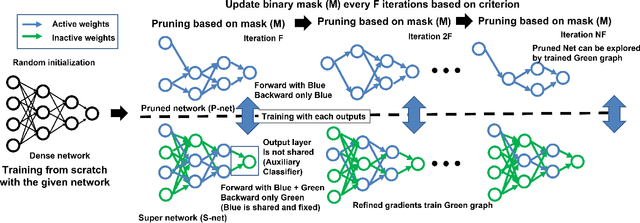
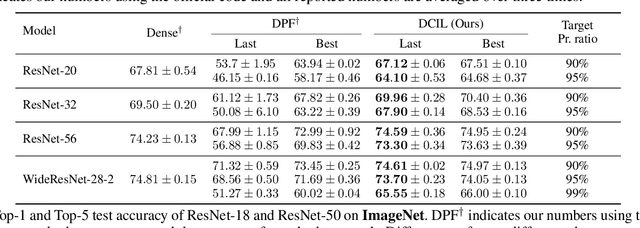
With the growth of deep neural networks (DNN), the number of DNN parameters has drastically increased. This makes DNN models hard to be deployed on resource-limited embedded systems. To alleviate this problem, dynamic pruning methods have emerged, which try to find diverse sparsity patterns during training by utilizing Straight-Through-Estimator (STE) to approximate gradients of pruned weights. STE can help the pruned weights revive in the process of finding dynamic sparsity patterns. However, using these coarse gradients causes training instability and performance degradation owing to the unreliable gradient signal of the STE approximation. In this work, to tackle this issue, we introduce refined gradients to update the pruned weights by forming dual forwarding paths from two sets (pruned and unpruned) of weights. We propose a novel Dynamic Collective Intelligence Learning (DCIL) which makes use of the learning synergy between the collective intelligence of both weight sets. We verify the usefulness of the refined gradients by showing enhancements in the training stability and the model performance on the CIFAR and ImageNet datasets. DCIL outperforms various previously proposed pruning schemes including other dynamic pruning methods with enhanced stability during training.
PQK: Model Compression via Pruning, Quantization, and Knowledge Distillation
Jun 25, 2021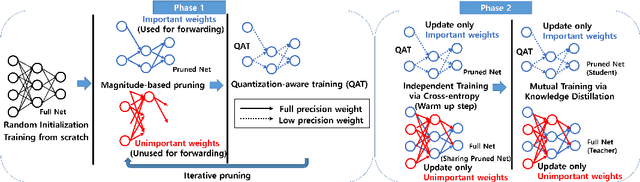
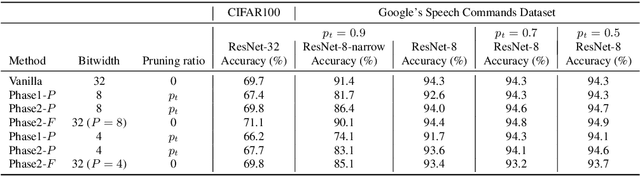
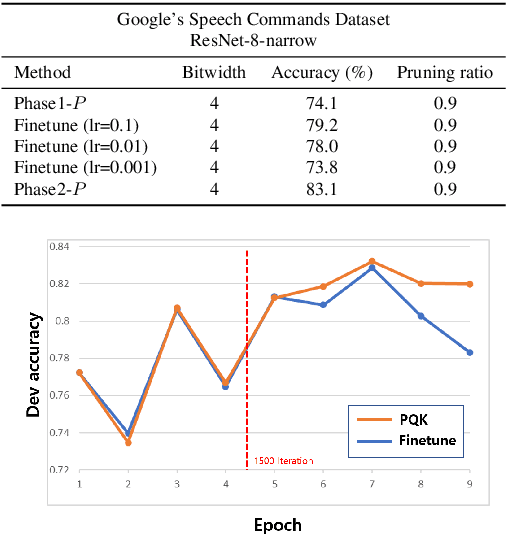
As edge devices become prevalent, deploying Deep Neural Networks (DNN) on edge devices has become a critical issue. However, DNN requires a high computational resource which is rarely available for edge devices. To handle this, we propose a novel model compression method for the devices with limited computational resources, called PQK consisting of pruning, quantization, and knowledge distillation (KD) processes. Unlike traditional pruning and KD, PQK makes use of unimportant weights pruned in the pruning process to make a teacher network for training a better student network without pre-training the teacher model. PQK has two phases. Phase 1 exploits iterative pruning and quantization-aware training to make a lightweight and power-efficient model. In phase 2, we make a teacher network by adding unimportant weights unused in phase 1 to a pruned network. By using this teacher network, we train the pruned network as a student network. In doing so, we do not need a pre-trained teacher network for the KD framework because the teacher and the student networks coexist within the same network. We apply our method to the recognition model and verify the effectiveness of PQK on keyword spotting (KWS) and image recognition.
Prototype-based Personalized Pruning
Mar 25, 2021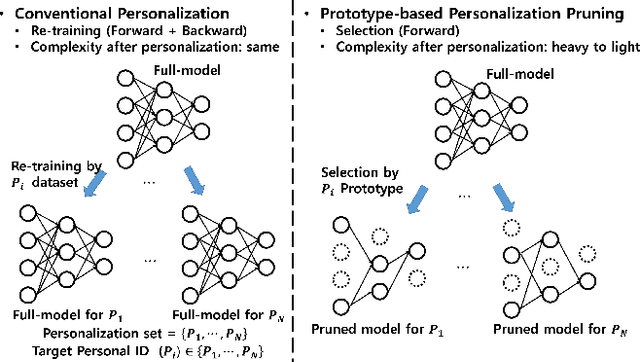
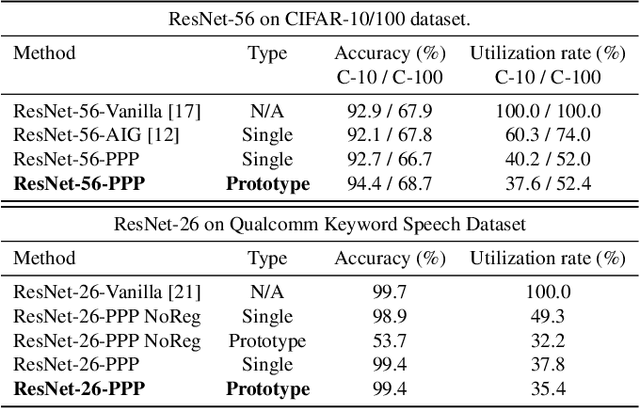
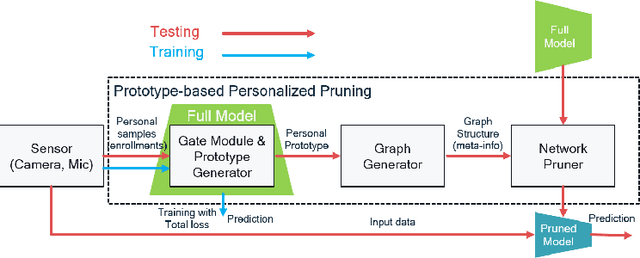
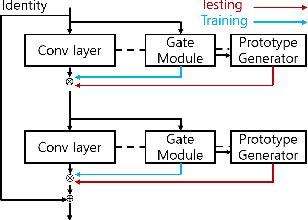
Nowadays, as edge devices such as smartphones become prevalent, there are increasing demands for personalized services. However, traditional personalization methods are not suitable for edge devices because retraining or finetuning is needed with limited personal data. Also, a full model might be too heavy for edge devices with limited resources. Unfortunately, model compression methods which can handle the model complexity issue also require the retraining phase. These multiple training phases generally need huge computational cost during on-device learning which can be a burden to edge devices. In this work, we propose a dynamic personalization method called prototype-based personalized pruning (PPP). PPP considers both ends of personalization and model efficiency. After training a network, PPP can easily prune the network with a prototype representing the characteristics of personal data and it performs well without retraining or finetuning. We verify the usefulness of PPP on a couple of tasks in computer vision and Keyword spotting.