 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Parameterize Asymmetric Quantization Ranges for Quantization-Aware Training
Apr 25, 2024



This paper investigates three different parameterizations of asymmetric uniform quantization for quantization-aware training: (1) scale and offset, (2) minimum and maximum, and (3) beta and gamma. We perform a comprehensive comparative analysis of these parameterizations' influence on quantization-aware training, using both controlled experiments and real-world large language models. Our particular focus is on their changing behavior in response to critical training hyperparameters, bit width and learning rate. Based on our investigation, we propose best practices to stabilize and accelerate quantization-aware training with learnable asymmetric quantization ranges.
Quadapter: Adapter for GPT-2 Quantization
Nov 30, 2022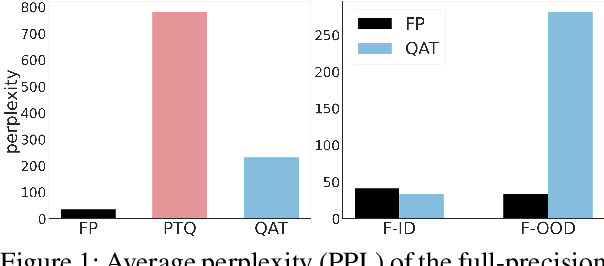
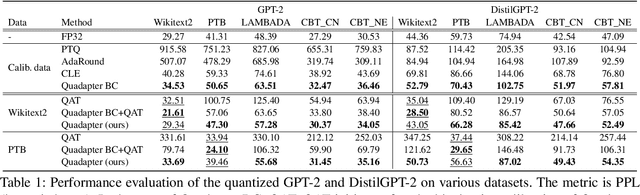


Transformer language models such as GPT-2 are difficult to quantize because of outliers in activations leading to a large quantization error. To adapt to the error, one must use quantization-aware training, which entails a fine-tuning process based on the dataset and the training pipeline identical to those for the original model. Pretrained language models, however, often do not grant access to their datasets and training pipelines, forcing us to rely on arbitrary ones for fine-tuning. In that case, it is observed that quantization-aware training overfits the model to the fine-tuning data. For quantization without overfitting, we introduce a quantization adapter (Quadapter), a small set of parameters that are learned to make activations quantization-friendly by scaling them channel-wise. It keeps the model parameters unchanged. By applying our method to the challenging task of quantizing GPT-2, we demonstrate that it effectively prevents the overfitting and improves the quantization performance.
Learning to Balance: Bayesian Meta-Learning for Imbalanced and Out-of-distribution Tasks
May 30, 2019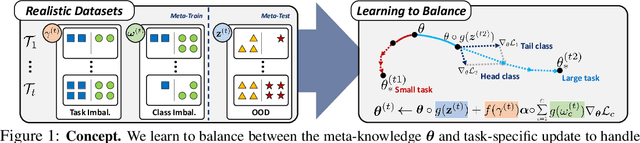
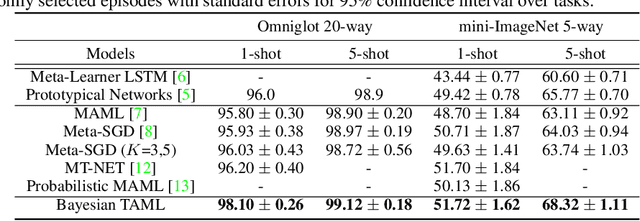
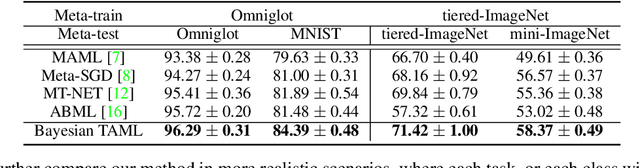
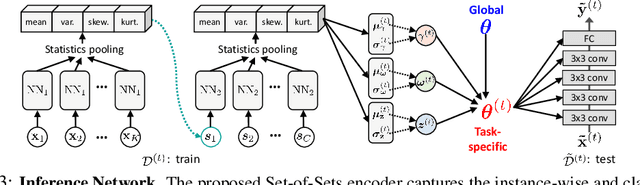
While tasks could come with varying number of instances in realistic settings, the existing meta-learning approaches for few-shot classfication assume even task distributions where the number of instances for each task and class are fixed. Due to such restriction, they learn to equally utilize the meta-knowledge across all the tasks, even when the number of instances per task and class largely varies. Moreover, they do not consider distributional difference in unseen tasks at the meta-test time, on which the meta-knowledge may have varying degree of usefulness depending on the task relatedness. To overcome these limitations, we propose a novel meta-learning model that adaptively balances the effect of the meta-learning and task-specific learning, and also class-specific learning within each task. Through the learning of the balancing variables, we can decide whether to obtain a solution close to the initial parameter or far from it. We formulate this objective into a Bayesian inference framework and solve it using variational inference. Our Bayesian Task-Adaptive Meta-Learning (Bayesian-TAML) significantly outperforms existing meta-learning approaches on benchmark datasets for both few-shot and realistic class- and task-imbalanced datasets, with especially higher gains on the latter.
MxML: Mixture of Meta-Learners for Few-Shot Classification
Apr 11, 2019
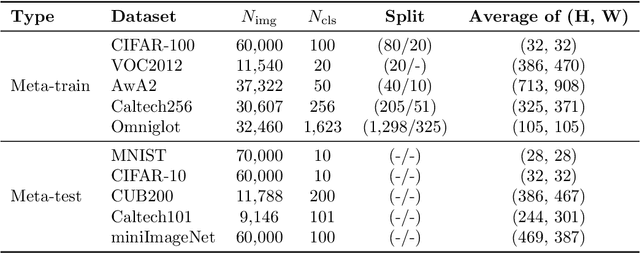
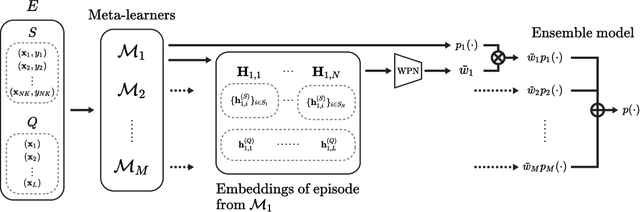
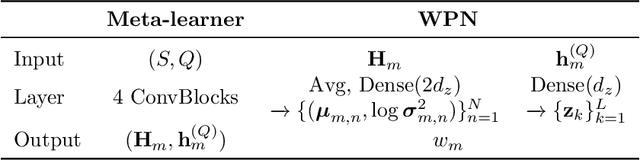
A meta-model is trained on a distribution of similar tasks such that it learns an algorithm that can quickly adapt to a novel task with only a handful of labeled examples. Most of current meta-learning methods assume that the meta-training set consists of relevant tasks sampled from a single distribution. In practice, however, a new task is often out of the task distribution, yielding a performance degradation. One way to tackle this problem is to construct an ensemble of meta-learners such that each meta-learner is trained on different task distribution. In this paper we present a method for constructing a mixture of meta-learners (MxML), where mixing parameters are determined by the weight prediction network (WPN) optimized to improve the few-shot classification performance. Experiments on various datasets demonstrate that MxML significantly outperforms state-of-the-art meta-learners, or their naive ensemble in the case of out-of-distribution as well as in-distribution tasks.
Learning to Propagate Labels: Transductive Propagation Network for Few-shot Learning
Oct 02, 2018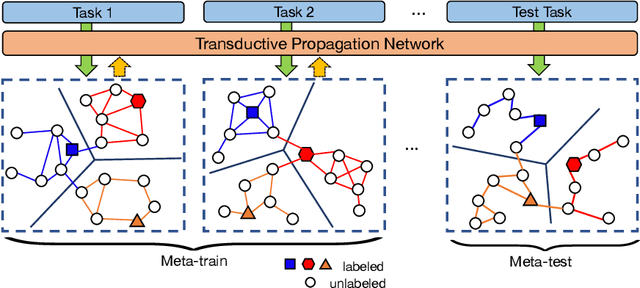
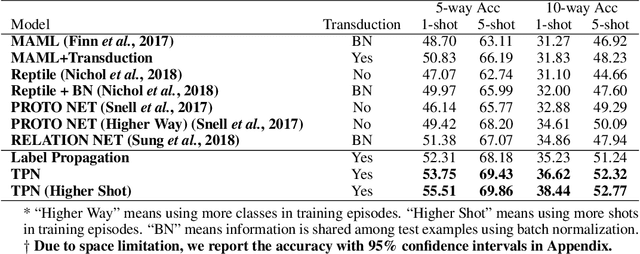
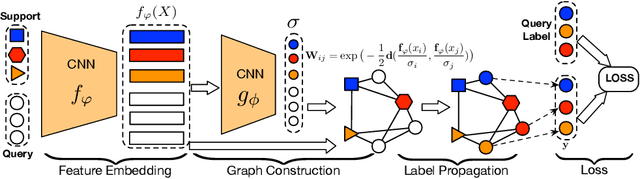
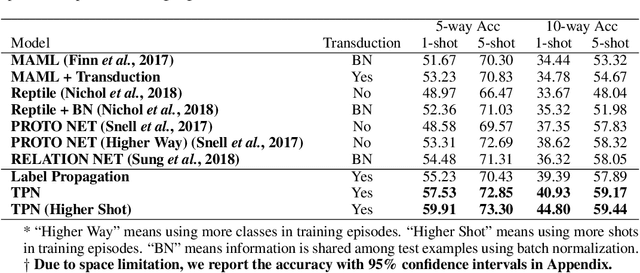
The goal of few-shot learning is to learn a classifier that generalizes well even when trained with a limited number of training instances per class. The recently introduced meta-learning approaches tackle this problem by learning a generic classifier across a large number of multiclass classification tasks and generalizing the model to a new task. Yet, even with such meta-learning, the low-data problem in the novel classification task still remains. In this paper, we propose Transductive Propagation Network (TPN), a novel meta-learning framework for transductive inference that classifies the entire test set at once to alleviate the low-data problem. Specifically, we propose to learn to propagate labels from labeled instances to unlabeled test instances, by learning a graph construction module that exploits the manifold structure in the data. TPN jointly learns both the parameters of feature embedding and the graph construction in an end-to-end manner. We validate TPN on multiple benchmark datasets, on which it largely outperforms existing few-shot learning approaches and achieves the state-of-the-art results.