 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Block-wise PTQ and Distillation-based QAT for Progressive Quantization toward 2-bit Instruction-Tuned LLMs
Jun 10, 2025As the rapid scaling of large language models (LLMs) poses significant challenges for deployment on resource-constrained devices, there is growing interest in extremely low-bit quantization, such as 2-bit. Although prior works have shown that 2-bit large models are pareto-optimal over their 4-bit smaller counterparts in both accuracy and latency, these advancements have been limited to pre-trained LLMs and have not yet been extended to instruction-tuned models. To bridge this gap, we propose Unified Progressive Quantization (UPQ)$-$a novel progressive quantization framework (FP16$\rightarrow$INT4$\rightarrow$INT2) that unifies block-wise post-training quantization (PTQ) with distillation-based quantization-aware training (Distill-QAT) for INT2 instruction-tuned LLM quantization. UPQ first quantizes FP16 instruction-tuned models to INT4 using block-wise PTQ to significantly reduce the quantization error introduced by subsequent INT2 quantization. Next, UPQ applies Distill-QAT to enable INT2 instruction-tuned LLMs to generate responses consistent with their original FP16 counterparts by minimizing the generalized Jensen-Shannon divergence (JSD) between the two. To the best of our knowledge, we are the first to demonstrate that UPQ can quantize open-source instruction-tuned LLMs to INT2 without relying on proprietary post-training data, while achieving state-of-the-art performances on MMLU and IFEval$-$two of the most representative benchmarks for evaluating instruction-tuned LLMs.
How to Parameterize Asymmetric Quantization Ranges for Quantization-Aware Training
Apr 25, 2024



This paper investigates three different parameterizations of asymmetric uniform quantization for quantization-aware training: (1) scale and offset, (2) minimum and maximum, and (3) beta and gamma. We perform a comprehensive comparative analysis of these parameterizations' influence on quantization-aware training, using both controlled experiments and real-world large language models. Our particular focus is on their changing behavior in response to critical training hyperparameters, bit width and learning rate. Based on our investigation, we propose best practices to stabilize and accelerate quantization-aware training with learnable asymmetric quantization ranges.
Quadapter: Adapter for GPT-2 Quantization
Nov 30, 2022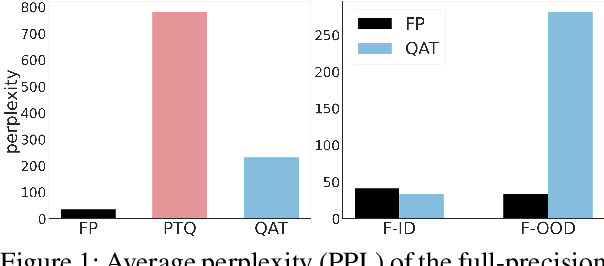
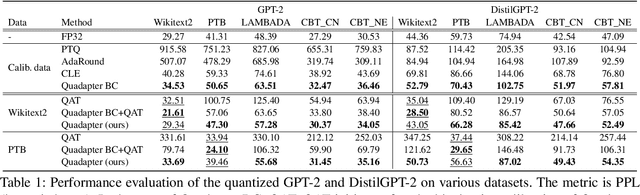


Transformer language models such as GPT-2 are difficult to quantize because of outliers in activations leading to a large quantization error. To adapt to the error, one must use quantization-aware training, which entails a fine-tuning process based on the dataset and the training pipeline identical to those for the original model. Pretrained language models, however, often do not grant access to their datasets and training pipelines, forcing us to rely on arbitrary ones for fine-tuning. In that case, it is observed that quantization-aware training overfits the model to the fine-tuning data. For quantization without overfitting, we introduce a quantization adapter (Quadapter), a small set of parameters that are learned to make activations quantization-friendly by scaling them channel-wise. It keeps the model parameters unchanged. By applying our method to the challenging task of quantizing GPT-2, we demonstrate that it effectively prevents the overfitting and improves the quantization performance.
KoDF: A Large-scale Korean DeepFake Detection Dataset
Mar 18, 2021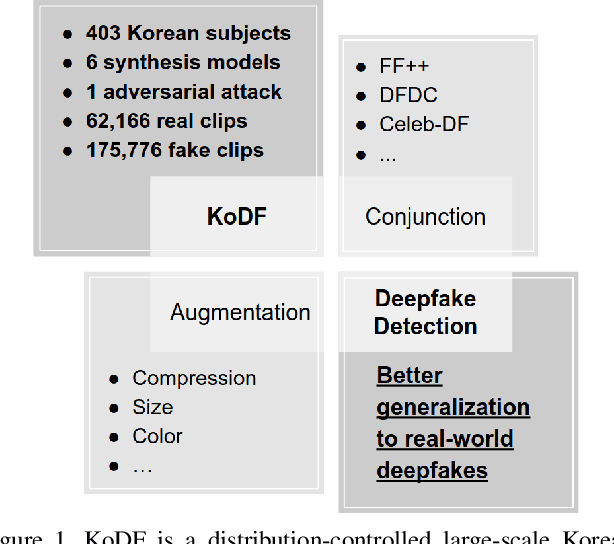
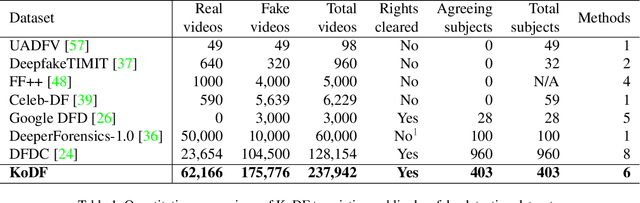
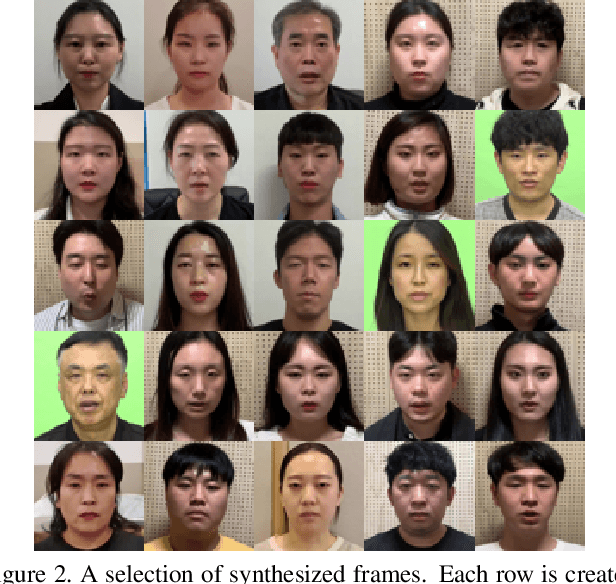
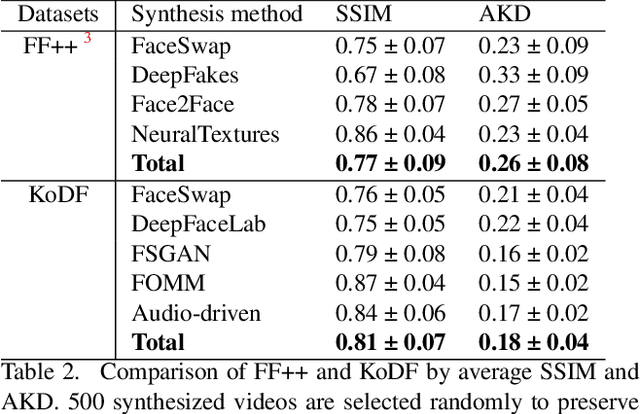
A variety of effective face-swap and face-reenactment methods have been publicized in recent years, democratizing the face synthesis technology to a great extent. Videos generated as such have come to be collectively called deepfakes with a negative connotation, for various social problems they have caused. Facing the emerging threat of deepfakes, we have built the Korean DeepFake Detection Dataset (KoDF), a large-scale collection of synthesized and real videos focused on Korean subjects. In this paper, we provide a detailed description of methods used to construct the dataset, experimentally show the discrepancy between the distributions of KoDF and existing deepfake detection datasets, and underline the importance of using multiple datasets for real-world generalization. KoDF is publicly available at https://moneybrain-research.github.io/kodf in its entirety (i.e. real clips, synthesized clips, clips with additive noise, and their corresponding metadata).
GAN Vocoder: Multi-Resolution Discriminator Is All You Need
Mar 09, 2021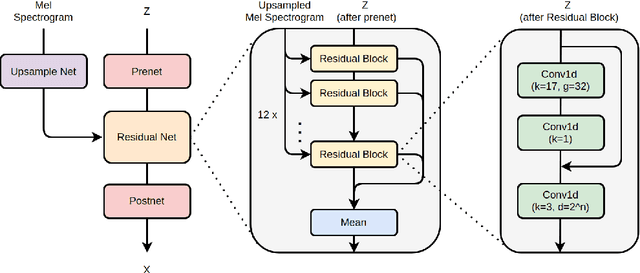
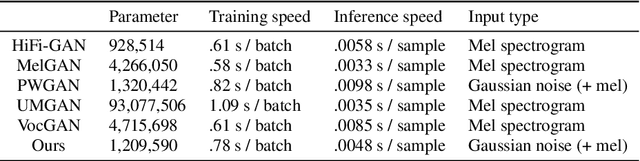
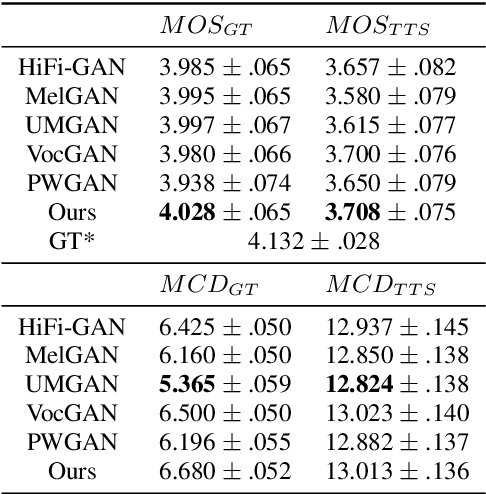
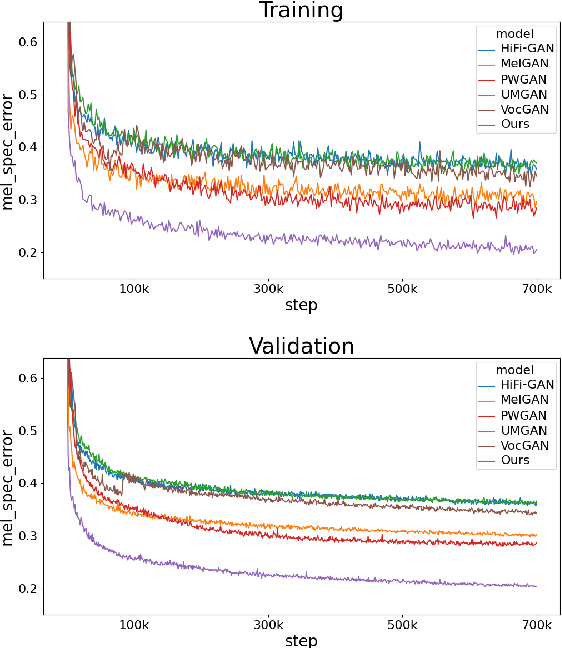
Several of the latest GAN-based vocoders show remarkable achievements, outperforming autoregressive and flow-based competitors in both qualitative and quantitative measures while synthesizing orders of magnitude faster. In this work, we hypothesize that the common factor underlying their success is the multi-resolution discriminating framework, not the minute details in architecture, loss function, or training strategy. We experimentally test the hypothesis by evaluating six different generators paired with one shared multi-resolution discriminating framework. For all evaluative measures with respect to text-to-speech syntheses and for all perceptual metrics, their performances are not distinguishable from one another, which supports our hypothesis.
Axial Residual Networks for CycleGAN-based Voice Conversion
Mar 08, 2021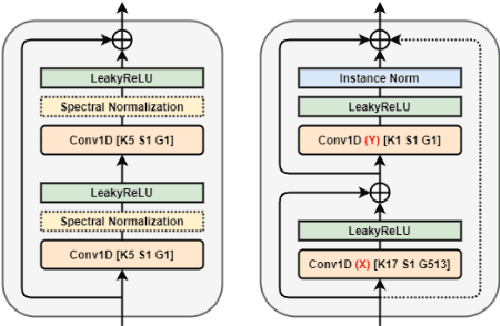
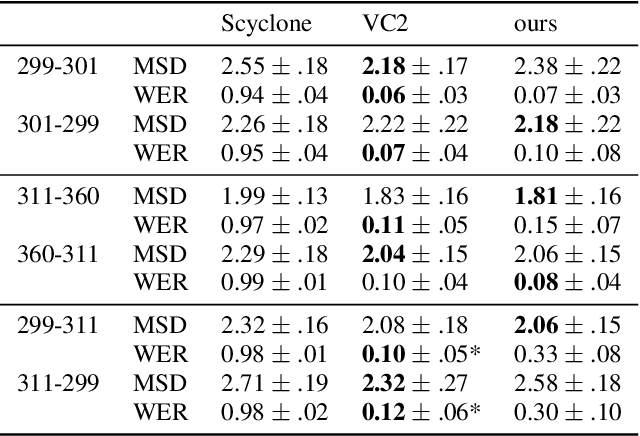
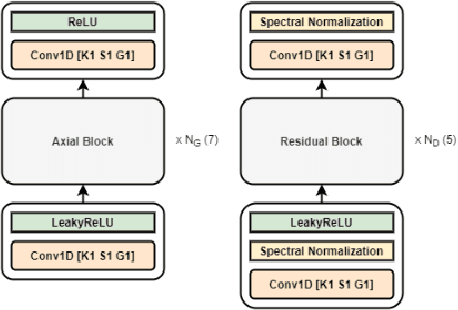
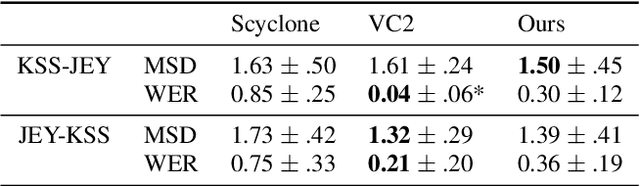
We propose a novel architecture and improved training objectives for non-parallel voice conversion. Our proposed CycleGAN-based model performs a shape-preserving transformation directly on a high frequency-resolution magnitude spectrogram, converting its style (i.e. speaker identity) while preserving the speech content. Throughout the entire conversion process, the model does not resort to compressed intermediate representations of any sort (e.g. mel spectrogram, low resolution spectrogram, decomposed network feature). We propose an efficient axial residual block architecture to support this expensive procedure and various modifications to the CycleGAN losses to stabilize the training process. We demonstrate via experiments that our proposed model outperforms Scyclone and shows a comparable or better performance to that of CycleGAN-VC2 even without employing a neural vocoder.