 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Block-wise PTQ and Distillation-based QAT for Progressive Quantization toward 2-bit Instruction-Tuned LLMs
Jun 10, 2025As the rapid scaling of large language models (LLMs) poses significant challenges for deployment on resource-constrained devices, there is growing interest in extremely low-bit quantization, such as 2-bit. Although prior works have shown that 2-bit large models are pareto-optimal over their 4-bit smaller counterparts in both accuracy and latency, these advancements have been limited to pre-trained LLMs and have not yet been extended to instruction-tuned models. To bridge this gap, we propose Unified Progressive Quantization (UPQ)$-$a novel progressive quantization framework (FP16$\rightarrow$INT4$\rightarrow$INT2) that unifies block-wise post-training quantization (PTQ) with distillation-based quantization-aware training (Distill-QAT) for INT2 instruction-tuned LLM quantization. UPQ first quantizes FP16 instruction-tuned models to INT4 using block-wise PTQ to significantly reduce the quantization error introduced by subsequent INT2 quantization. Next, UPQ applies Distill-QAT to enable INT2 instruction-tuned LLMs to generate responses consistent with their original FP16 counterparts by minimizing the generalized Jensen-Shannon divergence (JSD) between the two. To the best of our knowledge, we are the first to demonstrate that UPQ can quantize open-source instruction-tuned LLMs to INT2 without relying on proprietary post-training data, while achieving state-of-the-art performances on MMLU and IFEval$-$two of the most representative benchmarks for evaluating instruction-tuned LLMs.
Unknown Domain Inconsistency Minimization for Domain Generalization
Mar 12, 2024The objective of domain generalization (DG) is to enhance the transferability of the model learned from a source domain to unobserved domains. To prevent overfitting to a specific domain, Sharpness-Aware Minimization (SAM) reduces source domain's loss sharpness. Although SAM variants have delivered significant improvements in DG, we highlight that there's still potential for improvement in generalizing to unknown domains through the exploration on data space. This paper introduces an objective rooted in both parameter and data perturbed regions for domain generalization, coined Unknown Domain Inconsistency Minimization (UDIM). UDIM reduces the loss landscape inconsistency between source domain and unknown domains. As unknown domains are inaccessible, these domains are empirically crafted by perturbing instances from the source domain dataset. In particular, by aligning the loss landscape acquired in the source domain to the loss landscape of perturbed domains, we expect to achieve generalization grounded on these flat minima for the unknown domains. Theoretically, we validate that merging SAM optimization with the UDIM objective establishes an upper bound for the true objective of the DG task. In an empirical aspect, UDIM consistently outperforms SAM variants across multiple DG benchmark datasets. Notably, UDIM shows statistically significant improvements in scenarios with more restrictive domain information, underscoring UDIM's generalization capability in unseen domains. Our code is available at \url{https://github.com/SJShin-AI/UDIM}.
Dirichlet-based Per-Sample Weighting by Transition Matrix for Noisy Label Learning
Mar 05, 2024For learning with noisy labels, the transition matrix, which explicitly models the relation between noisy label distribution and clean label distribution, has been utilized to achieve the statistical consistency of either the classifier or the risk. Previous researches have focused more on how to estimate this transition matrix well, rather than how to utilize it. We propose good utilization of the transition matrix is crucial and suggest a new utilization method based on resampling, coined RENT. Specifically, we first demonstrate current utilizations can have potential limitations for implementation. As an extension to Reweighting, we suggest the Dirichlet distribution-based per-sample Weight Sampling (DWS) framework, and compare reweighting and resampling under DWS framework. With the analyses from DWS, we propose RENT, a REsampling method with Noise Transition matrix. Empirically, RENT consistently outperforms existing transition matrix utilization methods, which includes reweighting, on various benchmark datasets. Our code is available at \url{https://github.com/BaeHeeSun/RENT}.
Make Prompts Adaptable: Bayesian Modeling for Vision-Language Prompt Learning with Data-Dependent Prior
Jan 09, 2024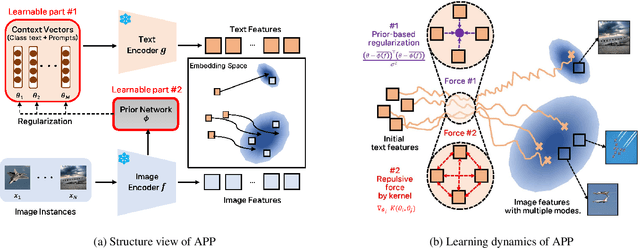

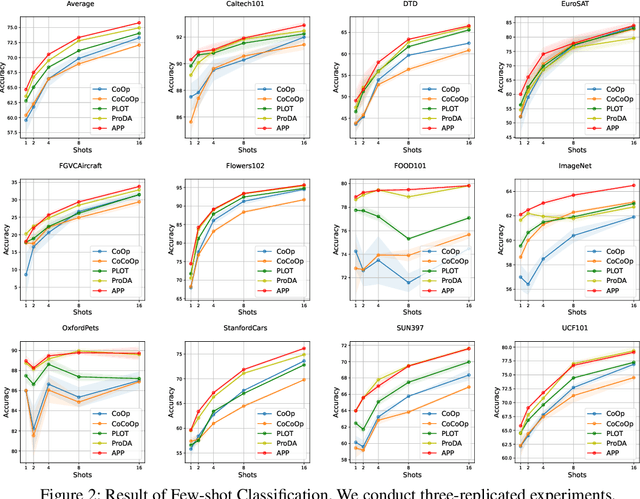

Recent Vision-Language Pretrained (VLP) models have become the backbone for many downstream tasks, but they are utilized as frozen model without learning. Prompt learning is a method to improve the pre-trained VLP model by adding a learnable context vector to the inputs of the text encoder. In a few-shot learning scenario of the downstream task, MLE training can lead the context vector to over-fit dominant image features in the training data. This overfitting can potentially harm the generalization ability, especially in the presence of a distribution shift between the training and test dataset. This paper presents a Bayesian-based framework of prompt learning, which could alleviate the overfitting issues on few-shot learning application and increase the adaptability of prompts on unseen instances. Specifically, modeling data-dependent prior enhances the adaptability of text features for both seen and unseen image features without the trade-off of performance between them. Based on the Bayesian framework, we utilize the Wasserstein Gradient Flow in the estimation of our target posterior distribution, which enables our prompt to be flexible in capturing the complex modes of image features. We demonstrate the effectiveness of our method on benchmark datasets for several experiments by showing statistically significant improvements on performance compared to existing methods. The code is available at https://github.com/youngjae-cho/APP.
Frequency Domain-based Dataset Distillation
Nov 15, 2023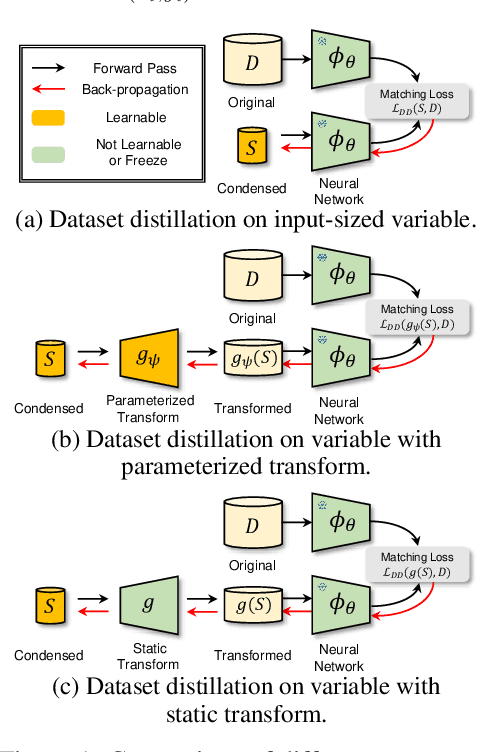
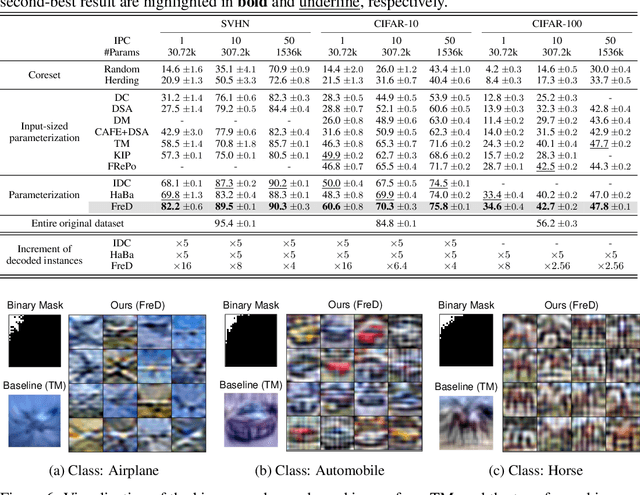
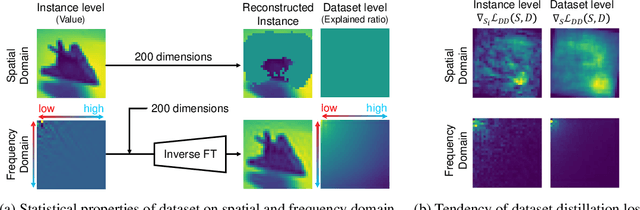
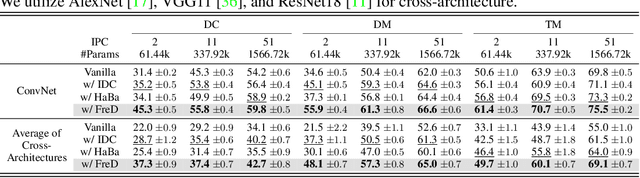
This paper presents FreD, a novel parameterization method for dataset distillation, which utilizes the frequency domain to distill a small-sized synthetic dataset from a large-sized original dataset. Unlike conventional approaches that focus on the spatial domain, FreD employs frequency-based transforms to optimize the frequency representations of each data instance. By leveraging the concentration of spatial domain information on specific frequency components, FreD intelligently selects a subset of frequency dimensions for optimization, leading to a significant reduction in the required budget for synthesizing an instance. Through the selection of frequency dimensions based on the explained variance, FreD demonstrates both theoretical and empirical evidence of its ability to operate efficiently within a limited budget, while better preserving the information of the original dataset compared to conventional parameterization methods. Furthermore, based on the orthogonal compatibility of FreD with existing methods, we confirm that FreD consistently improves the performances of existing distillation methods over the evaluation scenarios with different benchmark datasets. We release the code at https://github.com/sdh0818/FreD.
Loss-Curvature Matching for Dataset Selection and Condensation
Mar 08, 2023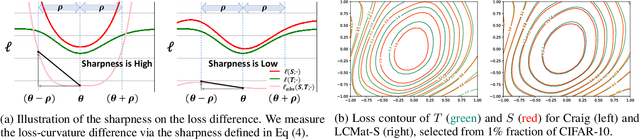
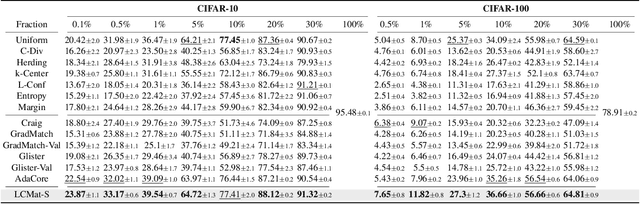
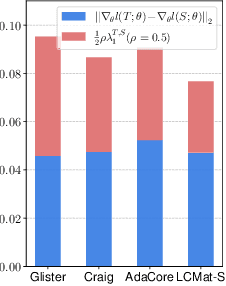
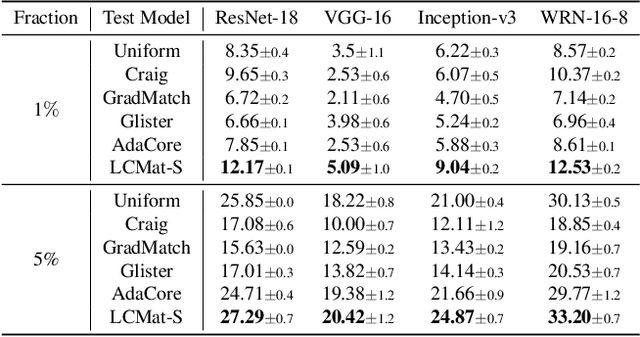
Training neural networks on a large dataset requires substantial computational costs. Dataset reduction selects or synthesizes data instances based on the large dataset, while minimizing the degradation in generalization performance from the full dataset. Existing methods utilize the neural network during the dataset reduction procedure, so the model parameter becomes important factor in preserving the performance after reduction. By depending upon the importance of parameters, this paper introduces a new reduction objective, coined LCMat, which Matches the Loss Curvatures of the original dataset and reduced dataset over the model parameter space, more than the parameter point. This new objective induces a better adaptation of the reduced dataset on the perturbed parameter region than the exact point matching. Particularly, we identify the worst case of the loss curvature gap from the local parameter region, and we derive the implementable upper bound of such worst-case with theoretical analyses. Our experiments on both coreset selection and condensation benchmarks illustrate that LCMat shows better generalization performances than existing baselines.
From Noisy Prediction to True Label: Noisy Prediction Calibration via Generative Model
May 02, 2022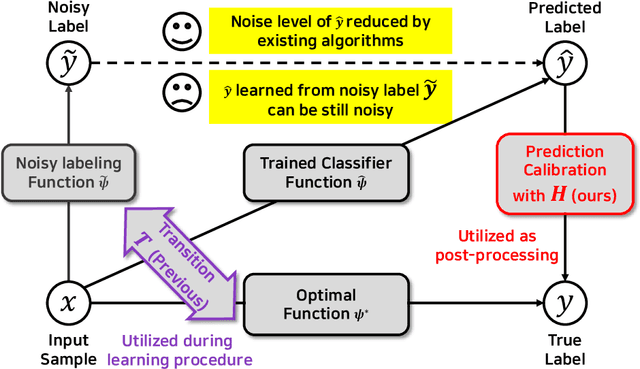
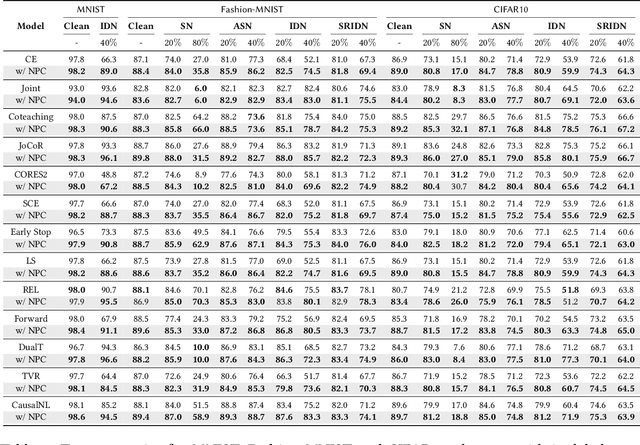
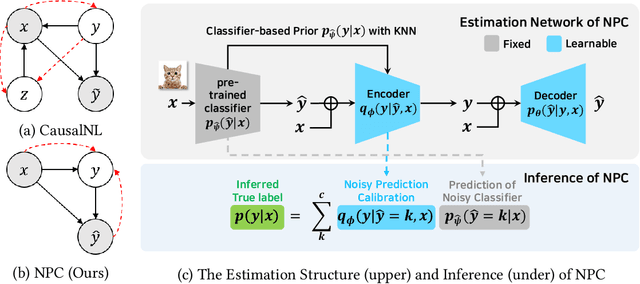
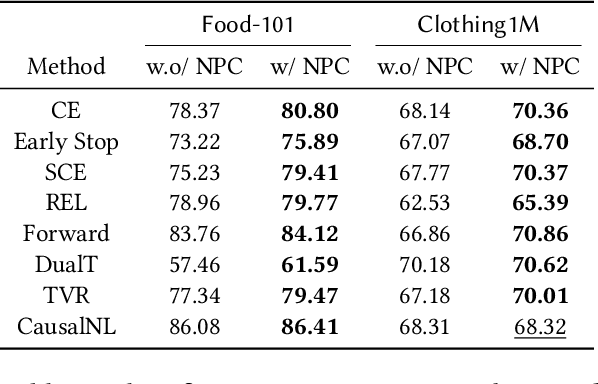
Noisy labels are inevitable yet problematic in machine learning society. It ruins the generalization power of a classifier by making the classifier be trained to be overfitted to wrong labels. Existing methods on noisy label have focused on modifying classifier training procedure. It results in two possible problems. First, these methods are not applicable to a pre-trained classifier without further access into training. Second, it is not easy to train a classifier and remove all of negative effects from noisy labels simultaneously. From these problems, we suggests a new branch of approach, Noisy Prediction Calibration (NPC) in learning with noisy labels. Through the introduction and estimation of a new type of transition matrix via generative model, NPC corrects the noisy prediction from the pre-trained classifier to the true label as a post-processing scheme. We prove that NPC theoretically aligns with the transition matrix based methods. Yet, NPC provides more accurate pathway to estimate true label, even without involvement in classifier learning. Also, NPC is applicable to any classifier trained with noisy label methods, if training instances and its predictions are available. Our method, NPC, boosts the classification performances of all baseline models on both synthetic and real-world datasets.
ABC: Auxiliary Balanced Classifier for Class-imbalanced Semi-supervised Learning
Oct 20, 2021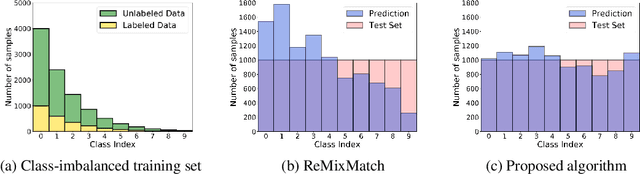
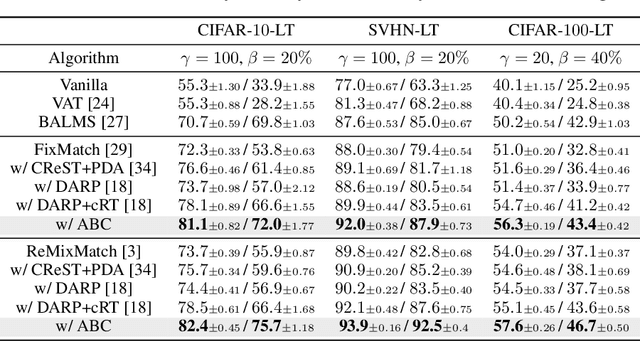
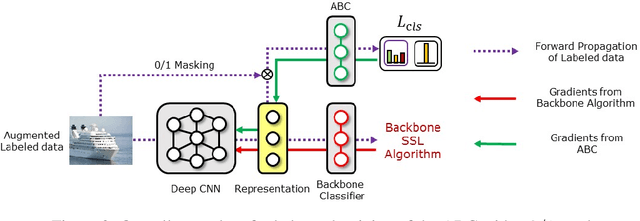
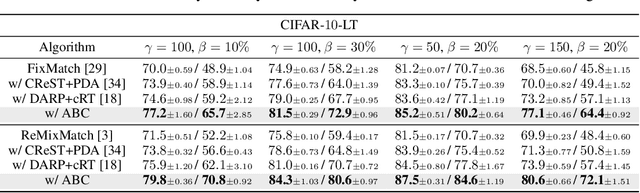
Existing semi-supervised learning (SSL) algorithms typically assume class-balanced datasets, although the class distributions of many real-world datasets are imbalanced. In general, classifiers trained on a class-imbalanced dataset are biased toward the majority classes. This issue becomes more problematic for SSL algorithms because they utilize the biased prediction of unlabeled data for training. However, traditional class-imbalanced learning techniques, which are designed for labeled data, cannot be readily combined with SSL algorithms. We propose a scalable class-imbalanced SSL algorithm that can effectively use unlabeled data, while mitigating class imbalance by introducing an auxiliary balanced classifier (ABC) of a single layer, which is attached to a representation layer of an existing SSL algorithm. The ABC is trained with a class-balanced loss of a minibatch, while using high-quality representations learned from all data points in the minibatch using the backbone SSL algorithm to avoid overfitting and information loss.Moreover, we use consistency regularization, a recent SSL technique for utilizing unlabeled data in a modified way, to train the ABC to be balanced among the classes by selecting unlabeled data with the same probability for each class. The proposed algorithm achieves state-of-the-art performance in various class-imbalanced SSL experiments using four benchmark datasets.
Score Matching Model for Unbounded Data Score
Jun 10, 2021
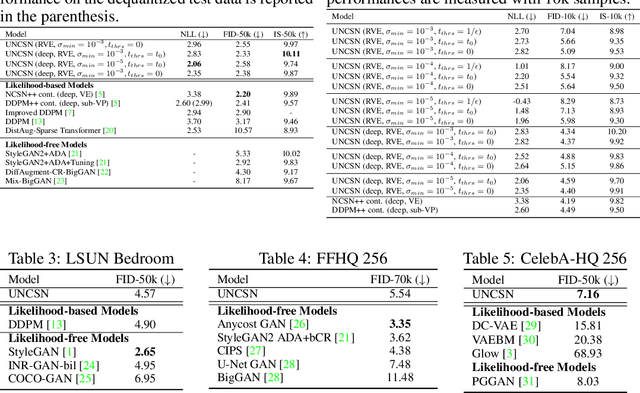
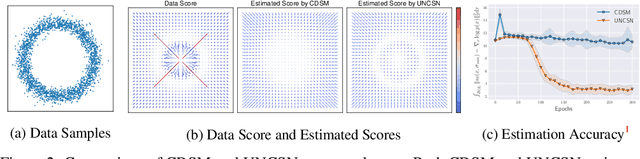
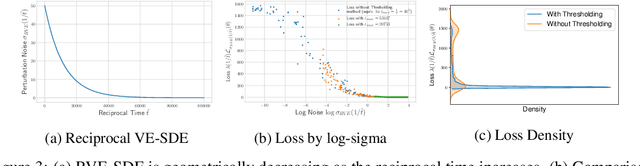
Recent advance in score-based models incorporates the stochastic differential equation (SDE), which brings the state-of-the art performance on image generation tasks. This paper improves such score-based models by analyzing the model at the zero perturbation noise. In real datasets, the score function diverges as the perturbation noise ($\sigma$) decreases to zero, and this observation leads an argument that the score estimation fails at $\sigma=0$ with any neural network structure. Subsequently, we introduce Unbounded Noise Conditional Score Network (UNCSN) that resolves the score diverging problem with an easily applicable modification to any noise conditional score-based models. Additionally, we introduce a new type of SDE, so the exact log likelihood can be calculated from the newly suggested SDE. On top of that, the associated loss function mitigates the loss imbalance issue in a mini-batch, and we present a theoretic analysis on the proposed loss to uncover the behind mechanism of the data distribution modeling by the score-based models.
Refine Myself by Teaching Myself: Feature Refinement via Self-Knowledge Distillation
Mar 15, 2021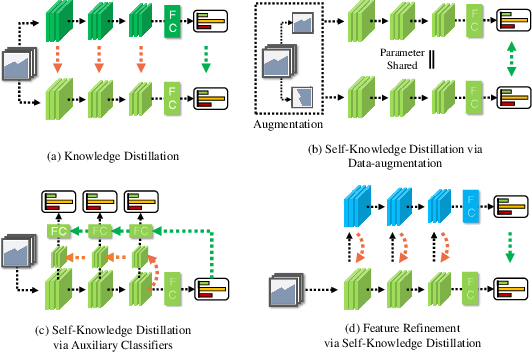
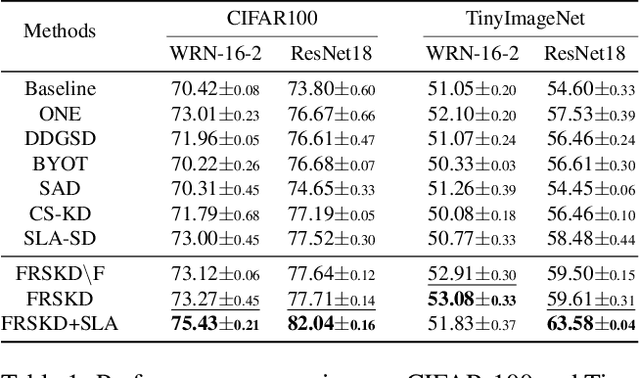
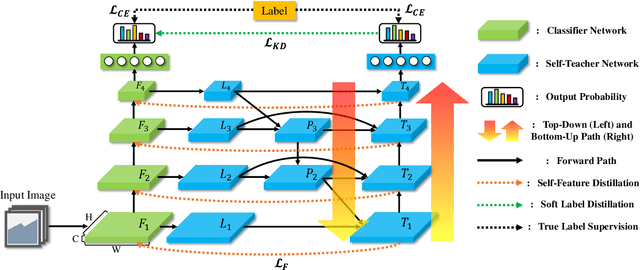
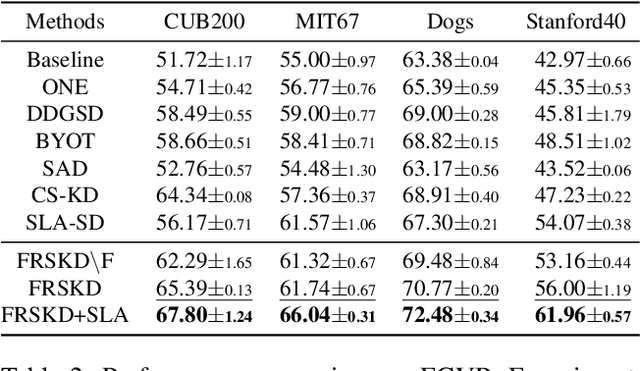
Knowledge distillation is a method of transferring the knowledge from a pretrained complex teacher model to a student model, so a smaller network can replace a large teacher network at the deployment stage. To reduce the necessity of training a large teacher model, the recent literatures introduced a self-knowledge distillation, which trains a student network progressively to distill its own knowledge without a pretrained teacher network. While Self-knowledge distillation is largely divided into a data augmentation based approach and an auxiliary network based approach, the data augmentation approach looses its local information in the augmentation process, which hinders its applicability to diverse vision tasks, such as semantic segmentation. Moreover, these knowledge distillation approaches do not receive the refined feature maps, which are prevalent in the object detection and semantic segmentation community. This paper proposes a novel self-knowledge distillation method, Feature Refinement via Self-Knowledge Distillation (FRSKD), which utilizes an auxiliary self-teacher network to transfer a refined knowledge for the classifier network. Our proposed method, FRSKD, can utilize both soft label and feature-map distillations for the self-knowledge distillation. Therefore, FRSKD can be applied to classification, and semantic segmentation, which emphasize preserving the local information. We demonstrate the effectiveness of FRSKD by enumerating its performance improvements in diverse tasks and benchmark datasets. The implemented code is available at https://github.com/MingiJi/FRSKD.