 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDE-regularized Dynamics-informed Diffusion with Uncertainty-aware Filtering for Long-Horizon Dynamics
Apr 10, 2026Long-horizon spatiotemporal prediction remains a challenging problem due to cumulative errors, noise amplification, and the lack of physical consistency in existing models. While diffusion models provide a probabilistic framework for modeling uncertainty, conventional approaches often rely on mean squared error objectives and fail to capture the underlying dynamics governed by physical laws. In this work, we propose PDYffusion, a dynamics-informed diffusion framework that integrates PDE-based regularization and uncertainty-aware forecasting for stable long-term prediction. The proposed method consists of two key components: a PDE-regularized interpolator and a UKF-based forecaster. The interpolator incorporates a differential operator to enforce physically consistent intermediate states, while the forecaster leverages the Unscented Kalman Filter to explicitly model uncertainty and mitigate error accumulation during iterative prediction. We provide theoretical analyses showing that the proposed interpolator satisfies PDE-constrained smoothness properties, and that the forecaster converges under the proposed loss formulation. Extensive experiments on multiple dynamical datasets demonstrate that PDYffusion achieves superior performance in terms of CRPS and MSE, while maintaining stable uncertainty behavior measured by SSR. We further analyze the inherent trade-off between prediction accuracy and uncertainty, showing that our method provides a balanced and robust solution for long-horizon forecasting.
ARES: Auxiliary Range Expansion for Outlier Synthesis
Jan 11, 2025Recent successes of artificial intelligence and deep learning often depend on the well-collected training dataset which is assumed to have an identical distribution with the test dataset. However, this assumption, which is called closed-set learning, is hard to meet in realistic scenarios for deploying deep learning models. As one of the solutions to mitigate this assumption, research on out-of-distribution (OOD) detection has been actively explored in various domains. In OOD detection, we assume that we are given the data of a new class that was not seen in the training phase, i.e., outlier, at the evaluation phase. The ultimate goal of OOD detection is to detect and classify such unseen outlier data as a novel "unknown" class. Among various research branches for OOD detection, generating a virtual outlier during the training phase has been proposed. However, conventional generation-based methodologies utilize in-distribution training dataset to imitate outlier instances, which limits the quality of the synthesized virtual outlier instance itself. In this paper, we propose a novel methodology for OOD detection named Auxiliary Range Expansion for Outlier Synthesis, or ARES. ARES models the region for generating out-of-distribution instances by escaping from the given in-distribution region; instead of remaining near the boundary of in-distribution region. Various stages consists ARES to ultimately generate valuable OOD-like virtual instances. The energy score-based discriminator is then trained to effectively separate in-distribution data and outlier data. Quantitative experiments on broad settings show the improvement of performance by our method, and qualitative results provide logical explanations of the mechanism behind it.
Unknown Domain Inconsistency Minimization for Domain Generalization
Mar 12, 2024The objective of domain generalization (DG) is to enhance the transferability of the model learned from a source domain to unobserved domains. To prevent overfitting to a specific domain, Sharpness-Aware Minimization (SAM) reduces source domain's loss sharpness. Although SAM variants have delivered significant improvements in DG, we highlight that there's still potential for improvement in generalizing to unknown domains through the exploration on data space. This paper introduces an objective rooted in both parameter and data perturbed regions for domain generalization, coined Unknown Domain Inconsistency Minimization (UDIM). UDIM reduces the loss landscape inconsistency between source domain and unknown domains. As unknown domains are inaccessible, these domains are empirically crafted by perturbing instances from the source domain dataset. In particular, by aligning the loss landscape acquired in the source domain to the loss landscape of perturbed domains, we expect to achieve generalization grounded on these flat minima for the unknown domains. Theoretically, we validate that merging SAM optimization with the UDIM objective establishes an upper bound for the true objective of the DG task. In an empirical aspect, UDIM consistently outperforms SAM variants across multiple DG benchmark datasets. Notably, UDIM shows statistically significant improvements in scenarios with more restrictive domain information, underscoring UDIM's generalization capability in unseen domains. Our code is available at \url{https://github.com/SJShin-AI/UDIM}.
LADA: Look-Ahead Data Acquisition via Augmentation for Active Learning
Nov 16, 2020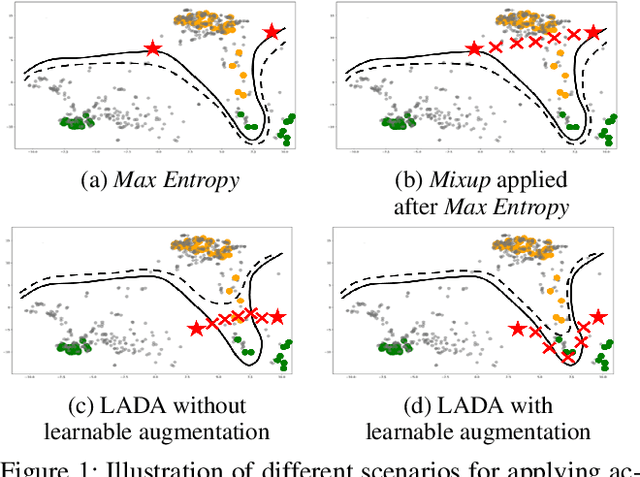
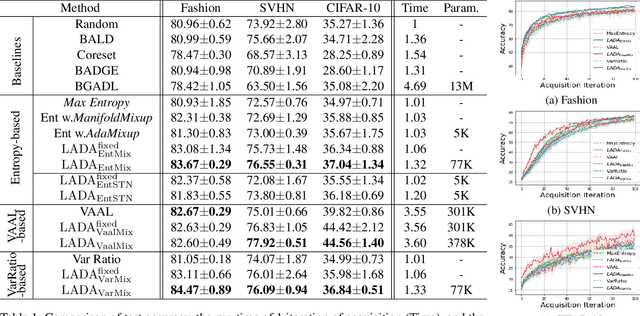
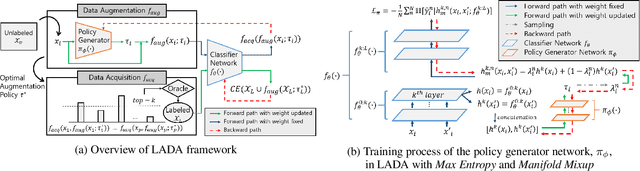

Active learning effectively collects data instances for training deep learning models when the labeled dataset is limited and the annotation cost is high. Besides active learning, data augmentation is also an effective technique to enlarge the limited amount of labeled instances. However, the potential gain from virtual instances generated by data augmentation has not been considered in the acquisition process of active learning yet. Looking ahead the effect of data augmentation in the process of acquisition would select and generate the data instances that are informative for training the model. Hence, this paper proposes Look-Ahead Data Acquisition via augmentation, or LADA, to integrate data acquisition and data augmentation. LADA considers both 1) unlabeled data instance to be selected and 2) virtual data instance to be generated by data augmentation, in advance of the acquisition process. Moreover, to enhance the informativeness of the virtual data instances, LADA optimizes the data augmentation policy to maximize the predictive acquisition score, resulting in the proposal of InfoMixup and InfoSTN. As LADA is a generalizable framework, we experiment with the various combinations of acquisition and augmentation methods. The performance of LADA shows a significant improvement over the recent augmentation and acquisition baselines which were independently applied to the benchmark datasets.
Sequential Recommendation with Relation-Aware Kernelized Self-Attention
Nov 15, 2019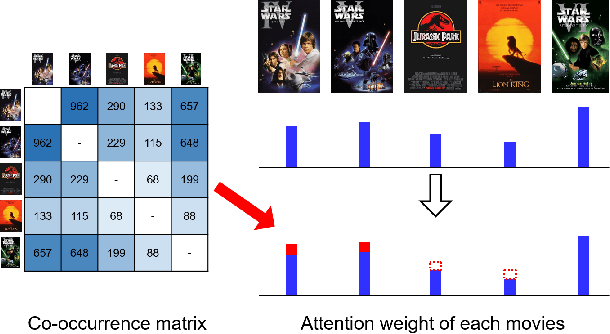

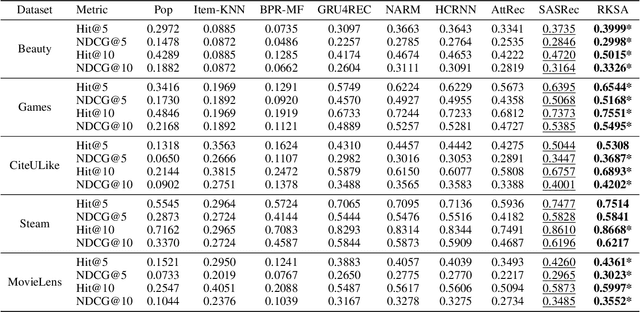
Recent studies identified that sequential Recommendation is improved by the attention mechanism. By following this development, we propose Relation-Aware Kernelized Self-Attention (RKSA) adopting a self-attention mechanism of the Transformer with augmentation of a probabilistic model. The original self-attention of Transformer is a deterministic measure without relation-awareness. Therefore, we introduce a latent space to the self-attention, and the latent space models the recommendation context from relation as a multivariate skew-normal distribution with a kernelized covariance matrix from co-occurrences, item characteristics, and user information. This work merges the self-attention of the Transformer and the sequential recommendation by adding a probabilistic model of the recommendation task specifics. We experimented RKSA over the benchmark datasets, and RKSA shows significant improvements compared to the recent baseline models. Also, RKSA were able to produce a latent space model that answers the reasons for recommendation.
* 8 pages, 5 figures, AAAI