 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Unbiased Diffusion Models From Biased Dataset
Mar 02, 2024With significant advancements in diffusion models, addressing the potential risks of dataset bias becomes increasingly important. Since generated outputs directly suffer from dataset bias, mitigating latent bias becomes a key factor in improving sample quality and proportion. This paper proposes time-dependent importance reweighting to mitigate the bias for the diffusion models. We demonstrate that the time-dependent density ratio becomes more precise than previous approaches, thereby minimizing error propagation in generative learning. While directly applying it to score-matching is intractable, we discover that using the time-dependent density ratio both for reweighting and score correction can lead to a tractable form of the objective function to regenerate the unbiased data density. Furthermore, we theoretically establish a connection with traditional score-matching, and we demonstrate its convergence to an unbiased distribution. The experimental evidence supports the usefulness of the proposed method, which outperforms baselines including time-independent importance reweighting on CIFAR-10, CIFAR-100, FFHQ, and CelebA with various bias settings. Our code is available at https://github.com/alsdudrla10/TIW-DSM.
Unknown-Aware Domain Adversarial Learning for Open-Set Domain Adaptation
Jun 15, 2022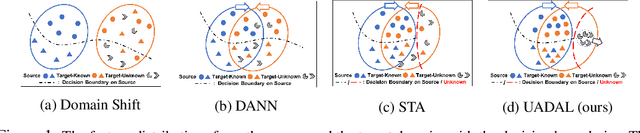
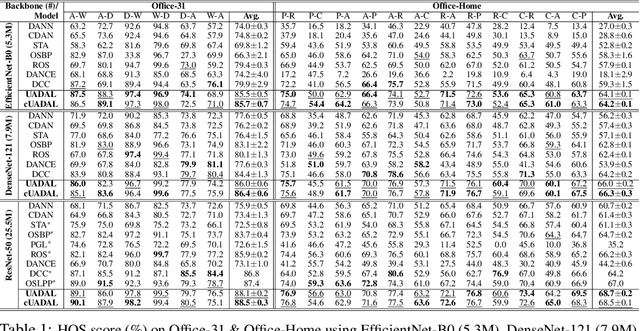
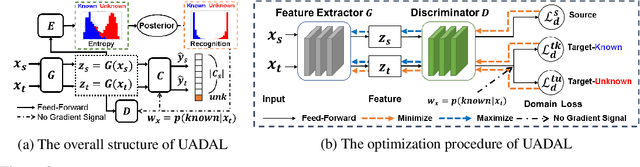
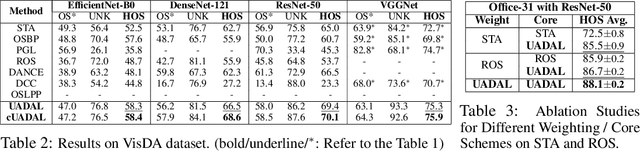
Open-Set Domain Adaptation (OSDA) assumes that a target domain contains unknown classes, which are not discovered in a source domain. Existing domain adversarial learning methods are not suitable for OSDA because distribution matching with \textit{unknown} classes leads to the negative transfer. Previous OSDA methods have focused on matching the source and the target distribution by only utilizing \textit{known} classes. However, this \textit{known}-only matching may fail to learn the target-\textit{unknown} feature space. Therefore, we propose Unknown-Aware Domain Adversarial Learning (UADAL), which \textit{aligns} the source and the targe-\textit{known} distribution while simultaneously \textit{segregating} the target-\textit{unknown} distribution in the feature alignment procedure. We provide theoretical analyses on the optimized state of the proposed \textit{unknown-aware} feature alignment, so we can guarantee both \textit{alignment} and \textit{segregation} theoretically. Empirically, we evaluate UADAL on the benchmark datasets, which shows that UADAL outperforms other methods with better feature alignments by reporting the state-of-the-art performances.
From Noisy Prediction to True Label: Noisy Prediction Calibration via Generative Model
May 02, 2022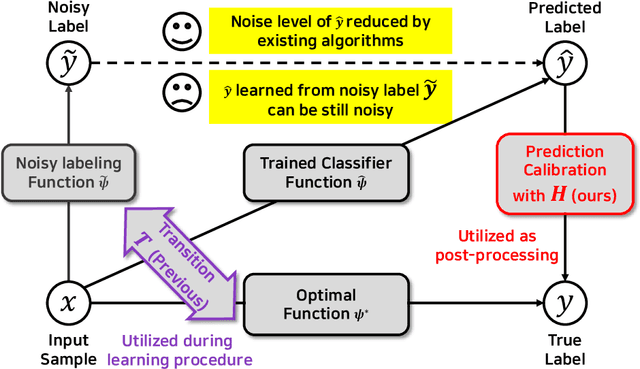
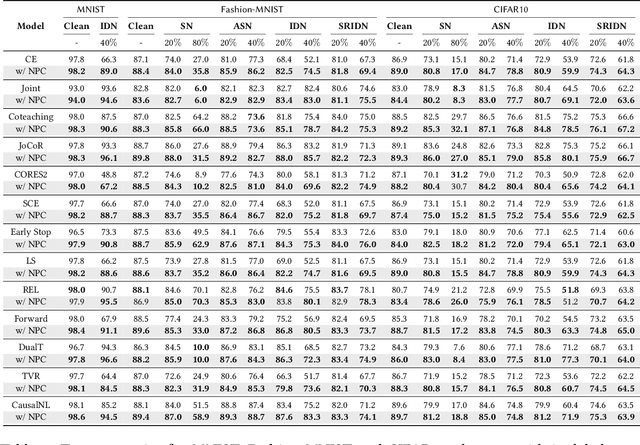
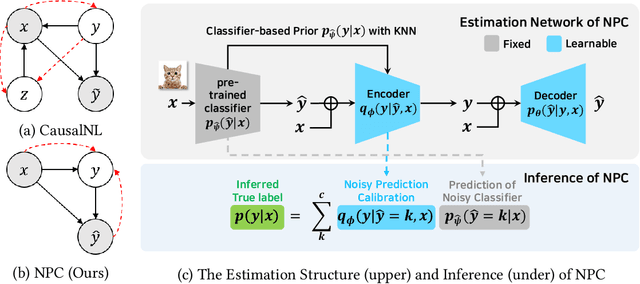
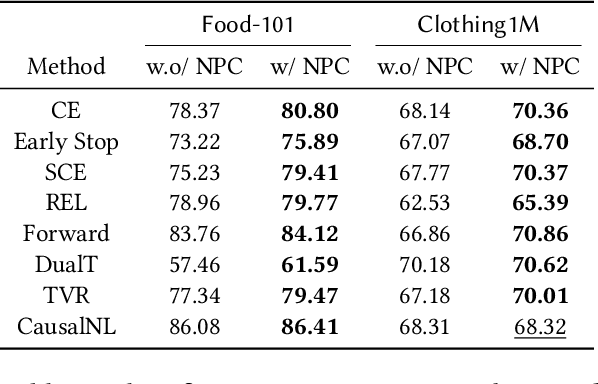
Noisy labels are inevitable yet problematic in machine learning society. It ruins the generalization power of a classifier by making the classifier be trained to be overfitted to wrong labels. Existing methods on noisy label have focused on modifying classifier training procedure. It results in two possible problems. First, these methods are not applicable to a pre-trained classifier without further access into training. Second, it is not easy to train a classifier and remove all of negative effects from noisy labels simultaneously. From these problems, we suggests a new branch of approach, Noisy Prediction Calibration (NPC) in learning with noisy labels. Through the introduction and estimation of a new type of transition matrix via generative model, NPC corrects the noisy prediction from the pre-trained classifier to the true label as a post-processing scheme. We prove that NPC theoretically aligns with the transition matrix based methods. Yet, NPC provides more accurate pathway to estimate true label, even without involvement in classifier learning. Also, NPC is applicable to any classifier trained with noisy label methods, if training instances and its predictions are available. Our method, NPC, boosts the classification performances of all baseline models on both synthetic and real-world datasets.
Counterfactual Fairness with Disentangled Causal Effect Variational Autoencoder
Dec 09, 2020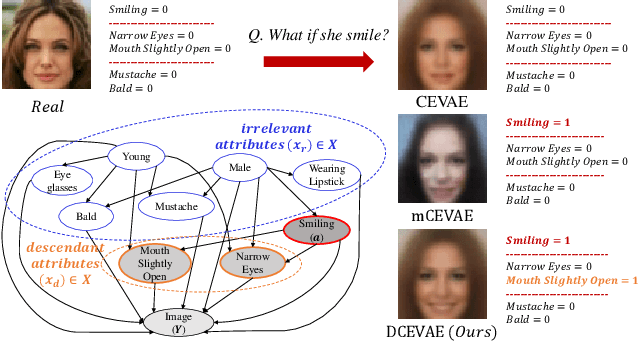
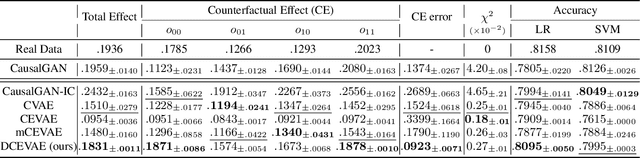
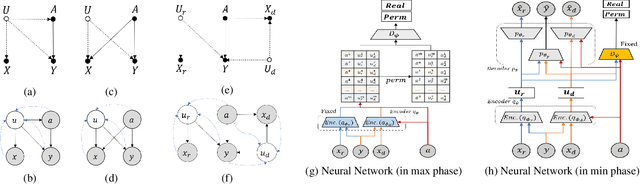
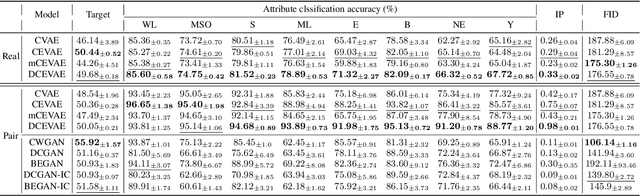
The problem of fair classification can be mollified if we develop a method to remove the embedded sensitive information from the classification features. This line of separating the sensitive information is developed through the causal inference, and the causal inference enables the counterfactual generations to contrast the what-if case of the opposite sensitive attribute. Along with this separation with the causality, a frequent assumption in the deep latent causal model defines a single latent variable to absorb the entire exogenous uncertainty of the causal graph. However, we claim that such structure cannot distinguish the 1) information caused by the intervention (i.e., sensitive variable) and 2) information correlated with the intervention from the data. Therefore, this paper proposes Disentangled Causal Effect Variational Autoencoder (DCEVAE) to resolve this limitation by disentangling the exogenous uncertainty into two latent variables: either 1) independent to interventions or 2) correlated to interventions without causality. Particularly, our disentangling approach preserves the latent variable correlated to interventions in generating counterfactual examples. We show that our method estimates the total effect and the counterfactual effect without a complete causal graph. By adding a fairness regularization, DCEVAE generates a counterfactual fair dataset while losing less original information. Also, DCEVAE generates natural counterfactual images by only flipping sensitive information. Additionally, we theoretically show the differences in the covariance structures of DCEVAE and prior works from the perspective of the latent disentanglement.
LADA: Look-Ahead Data Acquisition via Augmentation for Active Learning
Nov 16, 2020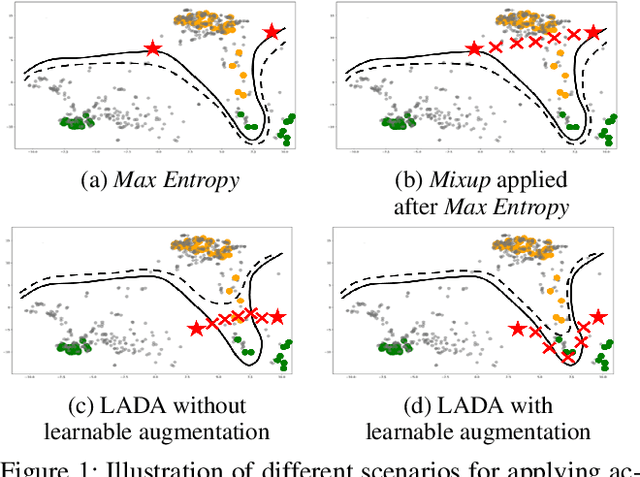
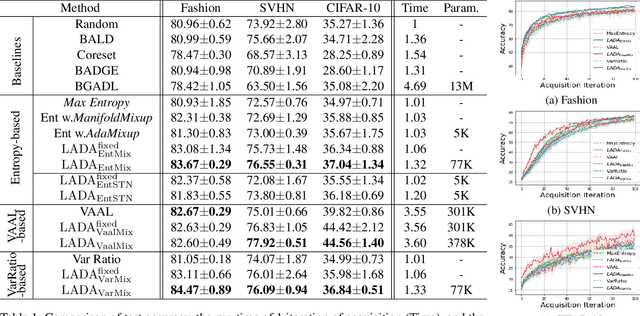
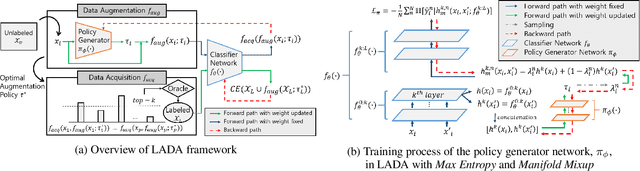

Active learning effectively collects data instances for training deep learning models when the labeled dataset is limited and the annotation cost is high. Besides active learning, data augmentation is also an effective technique to enlarge the limited amount of labeled instances. However, the potential gain from virtual instances generated by data augmentation has not been considered in the acquisition process of active learning yet. Looking ahead the effect of data augmentation in the process of acquisition would select and generate the data instances that are informative for training the model. Hence, this paper proposes Look-Ahead Data Acquisition via augmentation, or LADA, to integrate data acquisition and data augmentation. LADA considers both 1) unlabeled data instance to be selected and 2) virtual data instance to be generated by data augmentation, in advance of the acquisition process. Moreover, to enhance the informativeness of the virtual data instances, LADA optimizes the data augmentation policy to maximize the predictive acquisition score, resulting in the proposal of InfoMixup and InfoSTN. As LADA is a generalizable framework, we experiment with the various combinations of acquisition and augmentation methods. The performance of LADA shows a significant improvement over the recent augmentation and acquisition baselines which were independently applied to the benchmark datasets.
Neutralizing Gender Bias in Word Embedding with Latent Disentanglement and Counterfactual Generation
Apr 07, 2020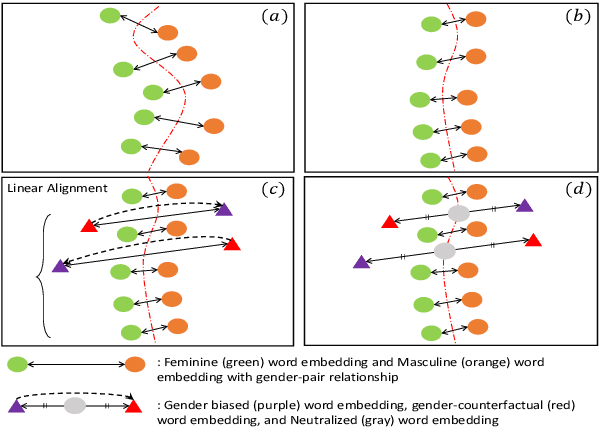
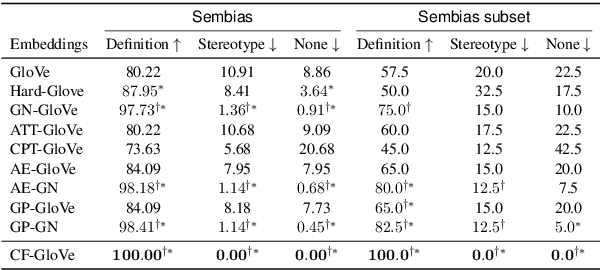
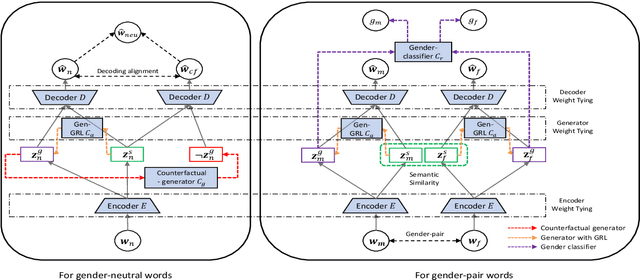
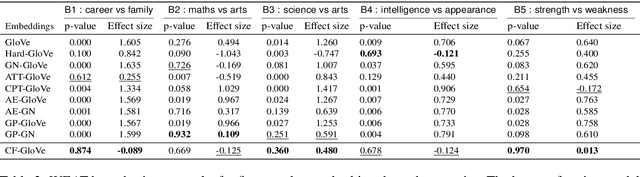
Recent researches demonstrate that word embeddings, trained on the human-generated corpus, have strong gender biases in embedding spaces, and these biases can result in the prejudiced results from the downstream tasks, i.e. sentiment analysis. Whereas the previous debiasing models project word embeddings into a linear subspace, we introduce a Latent Disentangling model with a siamese auto-encoder structure and a gradient reversal layer. Our siamese auto-encoder utilizes gender word pairs to disentangle semantics and gender information of given word, and the associated gradient reversal layer provides the negative gradient to distinguish the semantics from the gender. Afterwards, we introduce a Counterfactual Generation model to modify the gender information of words, so the original and the modified embeddings can produce a gender-neutralized word embedding after geometric alignment without loss of semantic information. Experimental results quantitatively and qualitatively indicate that the introduced method is better in debiasing word embeddings, and in minimizing the semantic information losses for NLP downstream tasks.
Bivariate Beta LSTM
May 25, 2019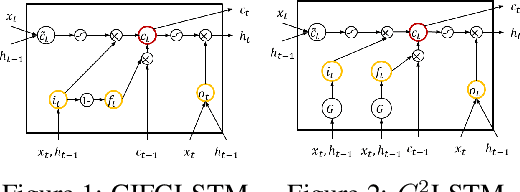
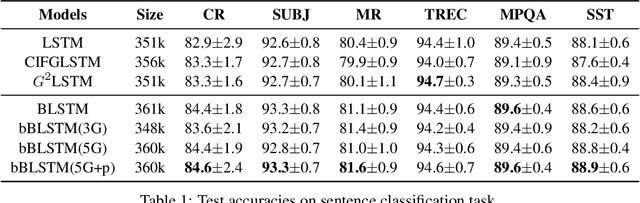


Long Short-Term Memory (LSTM) infers the long term dependency through a cell state maintained by the input and the forget gate structures, which models a gate output as a value in [0,1] through a sigmoid function. However, due to the graduality of the sigmoid function, the sigmoid gate is not flexible in representing multi-modality or skewness. Besides, the previous models lack correlation modeling between the gates, which would be a new method to adopt domain knowledge. This paper proposes a new gate structure with the bivariate Beta distribution. The proposed gate structure enables hierarchical probabilistic modeling on the gates within the LSTM cell, so the modelers can customize the cell state flow. Also, we observed that our structured flexible gate modeling is enabled by the probability density estimation. Moreover, we theoretically show and empirically experiment that the bivariate Beta distribution gate structure alleviates the gradient vanishing problem. We demonstrate the effectiveness of bivariate Beta gate structure on the sentence classification, image classification, polyphonic music modeling, and image caption generation.