 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularized Calibration with Successive Rounding for Post-Training Quantization
Feb 05, 2026Large language models (LLMs) deliver robust performance across diverse applications, yet their deployment often faces challenges due to the memory and latency costs of storing and accessing billions of parameters. Post-training quantization (PTQ) enables efficient inference by mapping pretrained weights to low-bit formats without retraining, but its effectiveness depends critically on both the quantization objective and the rounding procedure used to obtain low-bit weight representations. In this work, we show that interpolating between symmetric and asymmetric calibration acts as a form of regularization that preserves the standard quadratic structure used in PTQ while providing robustness to activation mismatch. Building on this perspective, we derive a simple successive rounding procedure that naturally incorporates asymmetric calibration, as well as a bounded-search extension that allows for an explicit trade-off between quantization quality and the compute cost. Experiments across multiple LLM families, quantization bit-widths, and benchmarks demonstrate that the proposed bounded search based on a regularized asymmetric calibration objective consistently improves perplexity and accuracy over PTQ baselines, while incurring only modest and controllable additional computational cost.
LANGSAE EDITING: Improving Multilingual Information Retrieval via Post-hoc Language Identity Removal
Jan 08, 2026Dense retrieval in multilingual settings often searches over mixed-language collections, yet multilingual embeddings encode language identity alongside semantics. This language signal can inflate similarity for same-language pairs and crowd out relevant evidence written in other languages. We propose LANGSAE EDITING, a post-hoc sparse autoencoder trained on pooled embeddings that enables controllable removal of language-identity signal directly in vector space. The method identifies language-associated latent units using cross-language activation statistics, suppresses these units at inference time, and reconstructs embeddings in the original dimensionality, making it compatible with existing vector databases without retraining the base encoder or re-encoding raw text. Experiments across multiple languages show consistent improvements in ranking quality and cross-language coverage, with especially strong gains for script-distinct languages.
Exploring Diffusion Transformer Designs via Grafting
Jun 06, 2025Designing model architectures requires decisions such as selecting operators (e.g., attention, convolution) and configurations (e.g., depth, width). However, evaluating the impact of these decisions on model quality requires costly pretraining, limiting architectural investigation. Inspired by how new software is built on existing code, we ask: can new architecture designs be studied using pretrained models? To this end, we present grafting, a simple approach for editing pretrained diffusion transformers (DiTs) to materialize new architectures under small compute budgets. Informed by our analysis of activation behavior and attention locality, we construct a testbed based on the DiT-XL/2 design to study the impact of grafting on model quality. Using this testbed, we develop a family of hybrid designs via grafting: replacing softmax attention with gated convolution, local attention, and linear attention, and replacing MLPs with variable expansion ratio and convolutional variants. Notably, many hybrid designs achieve good quality (FID: 2.38-2.64 vs. 2.27 for DiT-XL/2) using <2% pretraining compute. We then graft a text-to-image model (PixArt-Sigma), achieving a 1.43x speedup with less than a 2% drop in GenEval score. Finally, we present a case study that restructures DiT-XL/2 by converting every pair of sequential transformer blocks into parallel blocks via grafting. This reduces model depth by 2x and yields better quality (FID: 2.77) than other models of comparable depth. Together, we show that new diffusion model designs can be explored by grafting pretrained DiTs, with edits ranging from operator replacement to architecture restructuring. Code and grafted models: https://grafting.stanford.edu
GLOVA: Global and Local Variation-Aware Analog Circuit Design with Risk-Sensitive Reinforcement Learning
May 16, 2025Analog/mixed-signal circuit design encounters significant challenges due to performance degradation from process, voltage, and temperature (PVT) variations. To achieve commercial-grade reliability, iterative manual design revisions and extensive statistical simulations are required. While several studies have aimed to automate variation aware analog design to reduce time-to-market, the substantial mismatches in real-world wafers have not been thoroughly addressed. In this paper, we present GLOVA, an analog circuit sizing framework that effectively manages the impact of diverse random mismatches to improve robustness against PVT variations. In the proposed approach, risk-sensitive reinforcement learning is leveraged to account for the reliability bound affected by PVT variations, and ensemble-based critic is introduced to achieve sample-efficient learning. For design verification, we also propose $\mu$-$\sigma$ evaluation and simulation reordering method to reduce simulation costs of identifying failed designs. GLOVA supports verification through industrial-level PVT variation evaluation methods, including corner simulation as well as global and local Monte Carlo (MC) simulations. Compared to previous state-of-the-art variation-aware analog sizing frameworks, GLOVA achieves up to 80.5$\times$ improvement in sample efficiency and 76.0$\times$ reduction in time.
Training-Free Safe Denoisers for Safe Use of Diffusion Models
Feb 11, 2025There is growing concern over the safety of powerful diffusion models (DMs), as they are often misused to produce inappropriate, not-safe-for-work (NSFW) content or generate copyrighted material or data of individuals who wish to be forgotten. Many existing methods tackle these issues by heavily relying on text-based negative prompts or extensively retraining DMs to eliminate certain features or samples. In this paper, we take a radically different approach, directly modifying the sampling trajectory by leveraging a negation set (e.g., unsafe images, copyrighted data, or datapoints needed to be excluded) to avoid specific regions of data distribution, without needing to retrain or fine-tune DMs. We formally derive the relationship between the expected denoised samples that are safe and those that are not safe, leading to our $\textit{safe}$ denoiser which ensures its final samples are away from the area to be negated. Inspired by the derivation, we develop a practical algorithm that successfully produces high-quality samples while avoiding negation areas of the data distribution in text-conditional, class-conditional, and unconditional image generation scenarios. These results hint at the great potential of our training-free safe denoiser for using DMs more safely.
Exploring Coding Spot: Understanding Parametric Contributions to LLM Coding Performance
Dec 10, 2024Large Language Models (LLMs) have demonstrated notable proficiency in both code generation and comprehension across multiple programming languages. However, the mechanisms underlying this proficiency remain underexplored, particularly with respect to whether distinct programming languages are processed independently or within a shared parametric region. Drawing an analogy to the specialized regions of the brain responsible for distinct cognitive functions, we introduce the concept of Coding Spot, a specialized parametric region within LLMs that facilitates coding capabilities. Our findings identify this Coding Spot and show that targeted modifications to this subset significantly affect performance on coding tasks, while largely preserving non-coding functionalities. This compartmentalization mirrors the functional specialization observed in cognitive neuroscience, where specific brain regions are dedicated to distinct tasks, suggesting that LLMs may similarly employ specialized parameter regions for different knowledge domains.
Human-Feedback Efficient Reinforcement Learning for Online Diffusion Model Finetuning
Oct 07, 2024Controllable generation through Stable Diffusion (SD) fine-tuning aims to improve fidelity, safety, and alignment with human guidance. Existing reinforcement learning from human feedback methods usually rely on predefined heuristic reward functions or pretrained reward models built on large-scale datasets, limiting their applicability to scenarios where collecting such data is costly or difficult. To effectively and efficiently utilize human feedback, we develop a framework, HERO, which leverages online human feedback collected on the fly during model learning. Specifically, HERO features two key mechanisms: (1) Feedback-Aligned Representation Learning, an online training method that captures human feedback and provides informative learning signals for fine-tuning, and (2) Feedback-Guided Image Generation, which involves generating images from SD's refined initialization samples, enabling faster convergence towards the evaluator's intent. We demonstrate that HERO is 4x more efficient in online feedback for body part anomaly correction compared to the best existing method. Additionally, experiments show that HERO can effectively handle tasks like reasoning, counting, personalization, and reducing NSFW content with only 0.5K online feedback.
Changen2: Multi-Temporal Remote Sensing Generative Change Foundation Model
Jun 26, 2024

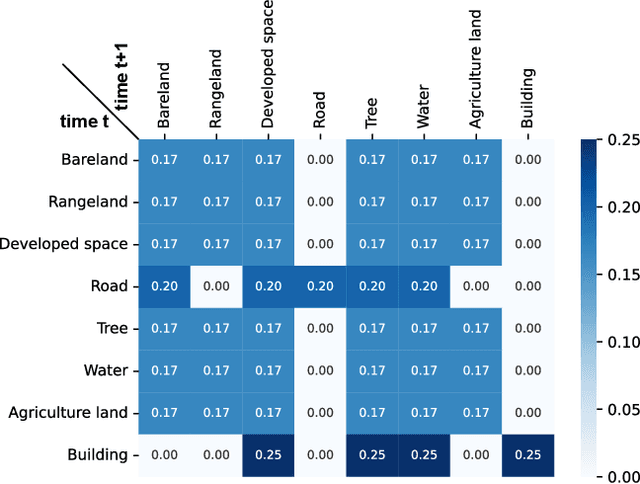
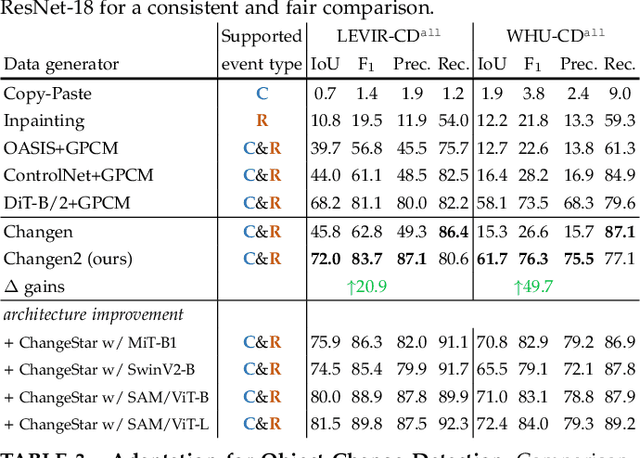
Our understanding of the temporal dynamics of the Earth's surface has been advanced by deep vision models, which often require lots of labeled multi-temporal images for training. However, collecting, preprocessing, and annotating multi-temporal remote sensing images at scale is non-trivial since it is expensive and knowledge-intensive. In this paper, we present change data generators based on generative models, which are cheap and automatic, alleviating these data problems. Our main idea is to simulate a stochastic change process over time. We describe the stochastic change process as a probabilistic graphical model (GPCM), which factorizes the complex simulation problem into two more tractable sub-problems, i.e., change event simulation and semantic change synthesis. To solve these two problems, we present Changen2, a GPCM with a resolution-scalable diffusion transformer which can generate time series of images and their semantic and change labels from labeled or unlabeled single-temporal images. Changen2 is a generative change foundation model that can be trained at scale via self-supervision, and can produce change supervisory signals from unlabeled single-temporal images. Unlike existing foundation models, Changen2 synthesizes change data to train task-specific foundation models for change detection. The resulting model possesses inherent zero-shot change detection capabilities and excellent transferability. Experiments suggest Changen2 has superior spatiotemporal scalability, e.g., Changen2 model trained on 256$^2$ pixel single-temporal images can yield time series of any length and resolutions of 1,024$^2$ pixels. Changen2 pre-trained models exhibit superior zero-shot performance (narrowing the performance gap to 3% on LEVIR-CD and approximately 10% on both S2Looking and SECOND, compared to fully supervised counterparts) and transferability across multiple types of change tasks.
Mean-field Chaos Diffusion Models
Jun 08, 2024


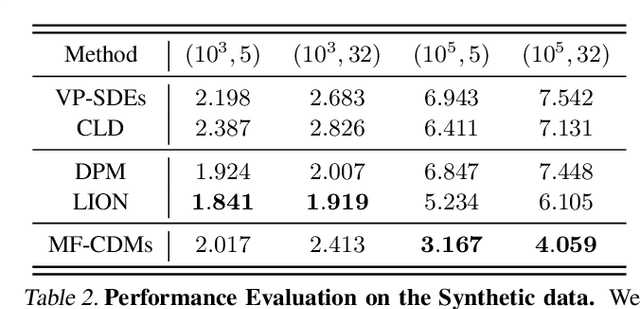
In this paper, we introduce a new class of score-based generative models (SGMs) designed to handle high-cardinality data distributions by leveraging concepts from mean-field theory. We present mean-field chaos diffusion models (MF-CDMs), which address the curse of dimensionality inherent in high-cardinality data by utilizing the propagation of chaos property of interacting particles. By treating high-cardinality data as a large stochastic system of interacting particles, we develop a novel score-matching method for infinite-dimensional chaotic particle systems and propose an approximation scheme that employs a subdivision strategy for efficient training. Our theoretical and empirical results demonstrate the scalability and effectiveness of MF-CDMs for managing large high-cardinality data structures, such as 3D point clouds.
SoundCTM: Uniting Score-based and Consistency Models for Text-to-Sound Generation
May 28, 2024



Sound content is an indispensable element for multimedia works such as video games, music, and films. Recent high-quality diffusion-based sound generation models can serve as valuable tools for the creators. However, despite producing high-quality sounds, these models often suffer from slow inference speeds. This drawback burdens creators, who typically refine their sounds through trial and error to align them with their artistic intentions. To address this issue, we introduce Sound Consistency Trajectory Models (SoundCTM). Our model enables flexible transitioning between high-quality 1-step sound generation and superior sound quality through multi-step generation. This allows creators to initially control sounds with 1-step samples before refining them through multi-step generation. While CTM fundamentally achieves flexible 1-step and multi-step generation, its impressive performance heavily depends on an additional pretrained feature extractor and an adversarial loss, which are expensive to train and not always available in other domains. Thus, we reframe CTM's training framework and introduce a novel feature distance by utilizing the teacher's network for a distillation loss. Additionally, while distilling classifier-free guided trajectories, we train conditional and unconditional student models simultaneously and interpolate between these models during inference. We also propose training-free controllable frameworks for SoundCTM, leveraging its flexible sampling capability. SoundCTM achieves both promising 1-step and multi-step real-time sound generation without using any extra off-the-shelf networks. Furthermore, we demonstrate SoundCTM's capability of controllable sound generation in a training-free manner.