 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Pansharpening Foundation Model
Mar 04, 2026Pansharpening generates the high-resolution multi-spectral (MS) image by integrating spatial details from a texture-rich panchromatic (PAN) image and spectral attributes from a low-resolution MS image. Existing methods are predominantly satellite-specific and scene-dependent, which severely limits their generalization across heterogeneous sensors and varied scenes, thereby reducing their real-world practicality. To address these challenges, we present FoundPS, a universal pansharpening foundation model for satellite-agnostic and scene-robust fusion. Specifically, we introduce a modality-interleaved transformer that learns band-wise modal specializations to form reversible spectral affine bases, mapping arbitrary-band MS into a unified latent space via tensor multiplication. Building upon this, we construct a latent diffusion bridge model to progressively evolve latent representations, and incorporate bridge posterior sampling to couple latent diffusion with pixel-space observations, enabling stable and controllable fusion. Furthermore, we devise infinite-dimensional pixel-to-latent interaction mechanisms to comprehensively capture the cross-domain dependencies between PAN observations and MS representations, thereby facilitating complementary information fusion. In addition, to support large-scale training and evaluation, we construct a comprehensive pansharpening benchmark, termed PSBench, consisting of worldwide MS and PAN image pairs from multiple satellites across diverse scenes. Extensive experiments demonstrate that FoundPS consistently outperforms state-of-the-art methods, exhibiting superior generalization and robustness across a wide range of pansharpening tasks.
EarthVL: A Progressive Earth Vision-Language Understanding and Generation Framework
Jan 06, 2026Earth vision has achieved milestones in geospatial object recognition but lacks exploration in object-relational reasoning, limiting comprehensive scene understanding. To address this, a progressive Earth vision-language understanding and generation framework is proposed, including a multi-task dataset (EarthVLSet) and a semantic-guided network (EarthVLNet). Focusing on city planning applications, EarthVLSet includes 10.9k sub-meter resolution remote sensing images, land-cover masks, and 761.5k textual pairs involving both multiple-choice and open-ended visual question answering (VQA) tasks. In an object-centric way, EarthVLNet is proposed to progressively achieve semantic segmentation, relational reasoning, and comprehensive understanding. The first stage involves land-cover segmentation to generate object semantics for VQA guidance. Guided by pixel-wise semantics, the object awareness based large language model (LLM) performs relational reasoning and knowledge summarization to generate the required answers. As for optimization, the numerical difference loss is proposed to dynamically add difference penalties, addressing the various objects' statistics. Three benchmarks, including semantic segmentation, multiple-choice, and open-ended VQA demonstrated the superiorities of EarthVLNet, yielding three future directions: 1) segmentation features consistently enhance VQA performance even in cross-dataset scenarios; 2) multiple-choice tasks show greater sensitivity to the vision encoder than to the language decoder; and 3) open-ended tasks necessitate advanced vision encoders and language decoders for an optimal performance. We believe this dataset and method will provide a beneficial benchmark that connects ''image-mask-text'', advancing geographical applications for Earth vision.
Advancing Weakly-Supervised Change Detection in Satellite Images via Adversarial Class Prompting
Aug 24, 2025


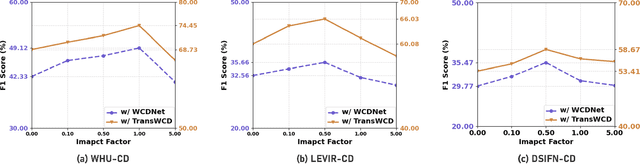
Weakly-Supervised Change Detection (WSCD) aims to distinguish specific object changes (e.g., objects appearing or disappearing) from background variations (e.g., environmental changes due to light, weather, or seasonal shifts) in paired satellite images, relying only on paired image (i.e., image-level) classification labels. This technique significantly reduces the need for dense annotations required in fully-supervised change detection. However, as image-level supervision only indicates whether objects have changed in a scene, WSCD methods often misclassify background variations as object changes, especially in complex remote-sensing scenarios. In this work, we propose an Adversarial Class Prompting (AdvCP) method to address this co-occurring noise problem, including two phases: a) Adversarial Prompt Mining: After each training iteration, we introduce adversarial prompting perturbations, using incorrect one-hot image-level labels to activate erroneous feature mappings. This process reveals co-occurring adversarial samples under weak supervision, namely background variation features that are likely to be misclassified as object changes. b) Adversarial Sample Rectification: We integrate these adversarially prompt-activated pixel samples into training by constructing an online global prototype. This prototype is built from an exponentially weighted moving average of the current batch and all historical training data. Our AdvCP can be seamlessly integrated into current WSCD methods without adding additional inference cost. Experiments on ConvNet, Transformer, and Segment Anything Model (SAM)-based baselines demonstrate significant performance enhancements. Furthermore, we demonstrate the generalizability of AdvCP to other multi-class weakly-supervised dense prediction scenarios. Code is available at https://github.com/zhenghuizhao/AdvCP
SPEX: A Vision-Language Model for Land Cover Extraction on Spectral Remote Sensing Images
Aug 07, 2025Spectral information has long been recognized as a critical cue in remote sensing observations. Although numerous vision-language models have been developed for pixel-level interpretation, spectral information remains underutilized, resulting in suboptimal performance, particularly in multispectral scenarios. To address this limitation, we construct a vision-language instruction-following dataset named SPIE, which encodes spectral priors of land-cover objects into textual attributes recognizable by large language models (LLMs), based on classical spectral index computations. Leveraging this dataset, we propose SPEX, a multimodal LLM designed for instruction-driven land cover extraction. To this end, we introduce several carefully designed components and training strategies, including multiscale feature aggregation, token context condensation, and multispectral visual pre-training, to achieve precise and flexible pixel-level interpretation. To the best of our knowledge, SPEX is the first multimodal vision-language model dedicated to land cover extraction in spectral remote sensing imagery. Extensive experiments on five public multispectral datasets demonstrate that SPEX consistently outperforms existing state-of-the-art methods in extracting typical land cover categories such as vegetation, buildings, and water bodies. Moreover, SPEX is capable of generating textual explanations for its predictions, thereby enhancing interpretability and user-friendliness. Code will be released at: https://github.com/MiliLab/SPEX.
TiMo: Spatiotemporal Foundation Model for Satellite Image Time Series
May 13, 2025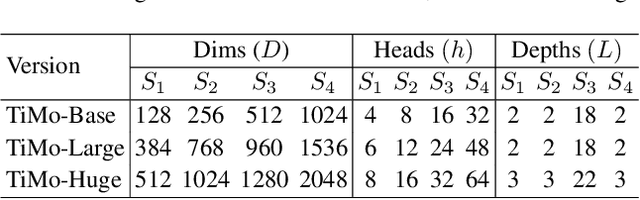
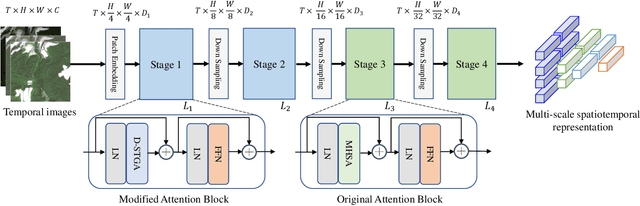
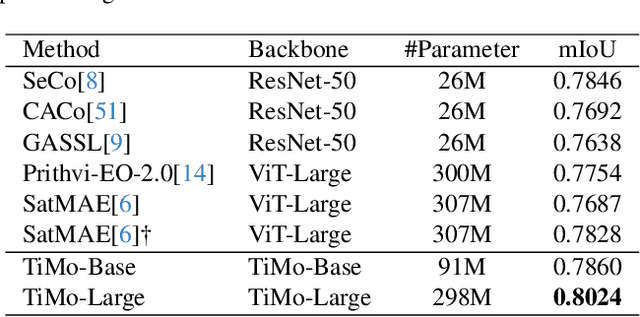
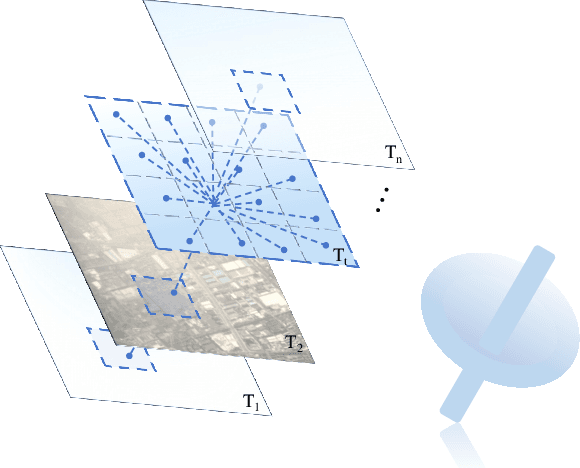
Satellite image time series (SITS) provide continuous observations of the Earth's surface, making them essential for applications such as environmental management and disaster assessment. However, existing spatiotemporal foundation models rely on plain vision transformers, which encode entire temporal sequences without explicitly capturing multiscale spatiotemporal relationships between land objects. This limitation hinders their effectiveness in downstream tasks. To overcome this challenge, we propose TiMo, a novel hierarchical vision transformer foundation model tailored for SITS analysis. At its core, we introduce a spatiotemporal gyroscope attention mechanism that dynamically captures evolving multiscale patterns across both time and space. For pre-training, we curate MillionST, a large-scale dataset of one million images from 100,000 geographic locations, each captured across 10 temporal phases over five years, encompassing diverse geospatial changes and seasonal variations. Leveraging this dataset, we adapt masked image modeling to pre-train TiMo, enabling it to effectively learn and encode generalizable spatiotemporal representations.Extensive experiments across multiple spatiotemporal tasks-including deforestation monitoring, land cover segmentation, crop type classification, and flood detection-demonstrate TiMo's superiority over state-of-the-art methods. Code, model, and dataset will be released at https://github.com/MiliLab/TiMo.
MambaMoE: Mixture-of-Spectral-Spatial-Experts State Space Model for Hyperspectral Image Classification
Apr 29, 2025The Mamba model has recently demonstrated strong potential in hyperspectral image (HSI) classification, owing to its ability to perform context modeling with linear computational complexity. However, existing Mamba-based methods usually neglect the spectral and spatial directional characteristics related to heterogeneous objects in hyperspectral scenes, leading to limited classification performance. To address these issues, we propose MambaMoE, a novel spectral-spatial mixture-of-experts framework, representing the first MoE-based approach in the HSI classification community. Specifically, we design a Mixture of Mamba Expert Block (MoMEB) that leverages sparse expert activation to enable adaptive spectral-spatial modeling. Furthermore, we introduce an uncertainty-guided corrective learning (UGCL) strategy to encourage the model's attention toward complex regions prone to prediction ambiguity. Extensive experiments on multiple public HSI benchmarks demonstrate that MambaMoE achieves state-of-the-art performance in both accuracy and efficiency compared to existing advanced approaches, especially for Mamba-based methods. Code will be released.
A Mechanism-Learning Deeply Coupled Model for Remote Sensing Retrieval of Global Land Surface Temperature
Apr 10, 2025Land surface temperature (LST) retrieval from remote sensing data is pivotal for analyzing climate processes and surface energy budgets. However, LST retrieval is an ill-posed inverse problem, which becomes particularly severe when only a single band is available. In this paper, we propose a deeply coupled framework integrating mechanistic modeling and machine learning to enhance the accuracy and generalizability of single-channel LST retrieval. Training samples are generated using a physically-based radiative transfer model and a global collection of 5810 atmospheric profiles. A physics-informed machine learning framework is proposed to systematically incorporate the first principles from classical physical inversion models into the learning workflow, with optimization constrained by radiative transfer equations. Global validation demonstrated a 30% reduction in root-mean-square error versus standalone methods. Under extreme humidity, the mean absolute error decreased from 4.87 K to 2.29 K (53% improvement). Continental-scale tests across five continents confirmed the superior generalizability of this model.
Model Hemorrhage and the Robustness Limits of Large Language Models
Mar 31, 2025



Large language models (LLMs) demonstrate strong performance across natural language processing tasks, yet undergo significant performance degradation when modified for deployment through quantization, pruning, or decoding strategy adjustments. We define this phenomenon as model hemorrhage - performance decline caused by parameter alterations and architectural changes. Through systematic analysis of various LLM frameworks, we identify key vulnerability patterns: layer expansion frequently disrupts attention mechanisms, compression techniques induce information loss cascades, and decoding adjustments amplify prediction divergences. Our investigation reveals transformer architectures exhibit inherent robustness thresholds that determine hemorrhage severity across modification types. We propose three mitigation strategies: gradient-aware pruning preserves critical weight pathways, dynamic quantization scaling maintains activation integrity, and decoding calibration aligns generation trajectories with original model distributions. This work establishes foundational metrics for evaluating model stability during adaptation, providing practical guidelines for maintaining performance while enabling efficient LLM deployment. Our findings advance understanding of neural network resilience under architectural transformations, particularly for large-scale language models.
Spiking Meets Attention: Efficient Remote Sensing Image Super-Resolution with Attention Spiking Neural Networks
Mar 06, 2025Spiking neural networks (SNNs) are emerging as a promising alternative to traditional artificial neural networks (ANNs), offering biological plausibility and energy efficiency. Despite these merits, SNNs are frequently hampered by limited capacity and insufficient representation power, yet remain underexplored in remote sensing super-resolution (SR) tasks. In this paper, we first observe that spiking signals exhibit drastic intensity variations across diverse textures, highlighting an active learning state of the neurons. This observation motivates us to apply SNNs for efficient SR of RSIs. Inspired by the success of attention mechanisms in representing salient information, we devise the spiking attention block (SAB), a concise yet effective component that optimizes membrane potentials through inferred attention weights, which, in turn, regulates spiking activity for superior feature representation. Our key contributions include: 1) we bridge the independent modulation between temporal and channel dimensions, facilitating joint feature correlation learning, and 2) we access the global self-similar patterns in large-scale remote sensing imagery to infer spatial attention weights, incorporating effective priors for realistic and faithful reconstruction. Building upon SAB, we proposed SpikeSR, which achieves state-of-the-art performance across various remote sensing benchmarks such as AID, DOTA, and DIOR, while maintaining high computational efficiency. The code of SpikeSR will be available upon paper acceptance.
HSRMamba: Contextual Spatial-Spectral State Space Model for Single Hyperspectral Super-Resolution
Jan 30, 2025



Mamba has demonstrated exceptional performance in visual tasks due to its powerful global modeling capabilities and linear computational complexity, offering considerable potential in hyperspectral image super-resolution (HSISR). However, in HSISR, Mamba faces challenges as transforming images into 1D sequences neglects the spatial-spectral structural relationships between locally adjacent pixels, and its performance is highly sensitive to input order, which affects the restoration of both spatial and spectral details. In this paper, we propose HSRMamba, a contextual spatial-spectral modeling state space model for HSISR, to address these issues both locally and globally. Specifically, a local spatial-spectral partitioning mechanism is designed to establish patch-wise causal relationships among adjacent pixels in 3D features, mitigating the local forgetting issue. Furthermore, a global spectral reordering strategy based on spectral similarity is employed to enhance the causal representation of similar pixels across both spatial and spectral dimensions. Finally, experimental results demonstrate our HSRMamba outperforms the state-of-the-art methods in quantitative quality and visual results. Code will be available soon.