 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPEX: A Vision-Language Model for Land Cover Extraction on Spectral Remote Sensing Images
Aug 07, 2025Spectral information has long been recognized as a critical cue in remote sensing observations. Although numerous vision-language models have been developed for pixel-level interpretation, spectral information remains underutilized, resulting in suboptimal performance, particularly in multispectral scenarios. To address this limitation, we construct a vision-language instruction-following dataset named SPIE, which encodes spectral priors of land-cover objects into textual attributes recognizable by large language models (LLMs), based on classical spectral index computations. Leveraging this dataset, we propose SPEX, a multimodal LLM designed for instruction-driven land cover extraction. To this end, we introduce several carefully designed components and training strategies, including multiscale feature aggregation, token context condensation, and multispectral visual pre-training, to achieve precise and flexible pixel-level interpretation. To the best of our knowledge, SPEX is the first multimodal vision-language model dedicated to land cover extraction in spectral remote sensing imagery. Extensive experiments on five public multispectral datasets demonstrate that SPEX consistently outperforms existing state-of-the-art methods in extracting typical land cover categories such as vegetation, buildings, and water bodies. Moreover, SPEX is capable of generating textual explanations for its predictions, thereby enhancing interpretability and user-friendliness. Code will be released at: https://github.com/MiliLab/SPEX.
TiMo: Spatiotemporal Foundation Model for Satellite Image Time Series
May 13, 2025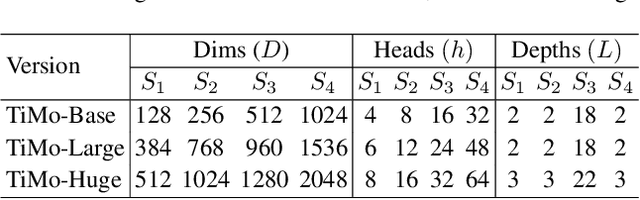
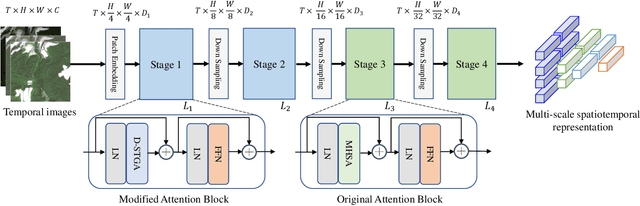
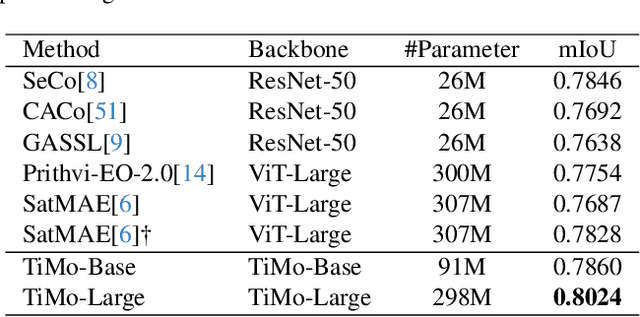
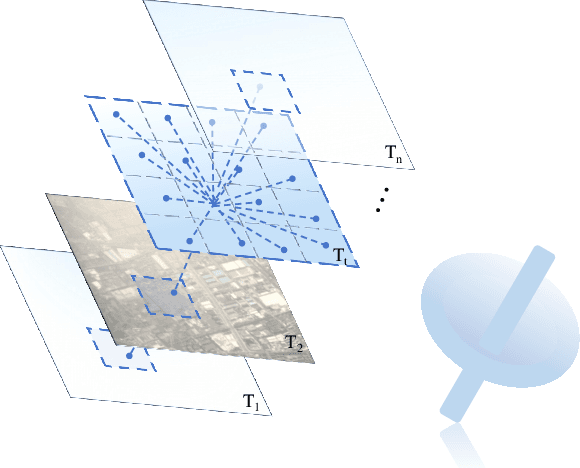
Satellite image time series (SITS) provide continuous observations of the Earth's surface, making them essential for applications such as environmental management and disaster assessment. However, existing spatiotemporal foundation models rely on plain vision transformers, which encode entire temporal sequences without explicitly capturing multiscale spatiotemporal relationships between land objects. This limitation hinders their effectiveness in downstream tasks. To overcome this challenge, we propose TiMo, a novel hierarchical vision transformer foundation model tailored for SITS analysis. At its core, we introduce a spatiotemporal gyroscope attention mechanism that dynamically captures evolving multiscale patterns across both time and space. For pre-training, we curate MillionST, a large-scale dataset of one million images from 100,000 geographic locations, each captured across 10 temporal phases over five years, encompassing diverse geospatial changes and seasonal variations. Leveraging this dataset, we adapt masked image modeling to pre-train TiMo, enabling it to effectively learn and encode generalizable spatiotemporal representations.Extensive experiments across multiple spatiotemporal tasks-including deforestation monitoring, land cover segmentation, crop type classification, and flood detection-demonstrate TiMo's superiority over state-of-the-art methods. Code, model, and dataset will be released at https://github.com/MiliLab/TiMo.
SITSMamba for Crop Classification based on Satellite Image Time Series
Sep 15, 2024Satellite image time series (SITS) data provides continuous observations over time, allowing for the tracking of vegetation changes and growth patterns throughout the seasons and years. Numerous deep learning (DL) approaches using SITS for crop classification have emerged recently, with the latest approaches adopting Transformer for SITS classification. However, the quadratic complexity of self-attention in Transformer poses challenges for classifying long time series. While the cutting-edge Mamba architecture has demonstrated strength in various domains, including remote sensing image interpretation, its capacity to learn temporal representations in SITS data remains unexplored. Moreover, the existing SITS classification methods often depend solely on crop labels as supervision signals, which fails to fully exploit the temporal information. In this paper, we proposed a Satellite Image Time Series Mamba (SITSMamba) method for crop classification based on remote sensing time series data. The proposed SITSMamba contains a spatial encoder based on Convolutional Neural Networks (CNN) and a Mamba-based temporal encoder. To exploit richer temporal information from SITS, we design two branches of decoder used for different tasks. The first branch is a crop Classification Branch (CBranch), which includes a ConvBlock to decode the feature to a crop map. The second branch is a SITS Reconstruction Branch that uses a Linear layer to transform the encoded feature to predict the original input values. Furthermore, we design a Positional Weight (PW) applied to the RBranch to help the model learn rich latent knowledge from SITS. We also design two weighting factors to control the balance of the two branches during training. The code of SITSMamba is available at: https://github.com/XiaoleiQinn/SITSMamba.
HyperSIGMA: Hyperspectral Intelligence Comprehension Foundation Model
Jun 17, 2024



Foundation models (FMs) are revolutionizing the analysis and understanding of remote sensing (RS) scenes, including aerial RGB, multispectral, and SAR images. However, hyperspectral images (HSIs), which are rich in spectral information, have not seen much application of FMs, with existing methods often restricted to specific tasks and lacking generality. To fill this gap, we introduce HyperSIGMA, a vision transformer-based foundation model for HSI interpretation, scalable to over a billion parameters. To tackle the spectral and spatial redundancy challenges in HSIs, we introduce a novel sparse sampling attention (SSA) mechanism, which effectively promotes the learning of diverse contextual features and serves as the basic block of HyperSIGMA. HyperSIGMA integrates spatial and spectral features using a specially designed spectral enhancement module. In addition, we construct a large-scale hyperspectral dataset, HyperGlobal-450K, for pre-training, which contains about 450K hyperspectral images, significantly surpassing existing datasets in scale. Extensive experiments on various high-level and low-level HSI tasks demonstrate HyperSIGMA's versatility and superior representational capability compared to current state-of-the-art methods. Moreover, HyperSIGMA shows significant advantages in scalability, robustness, cross-modal transferring capability, and real-world applicability.
HELLaMA: LLaMA-based Table to Text Generation by Highlighting the Important Evidence
Nov 15, 2023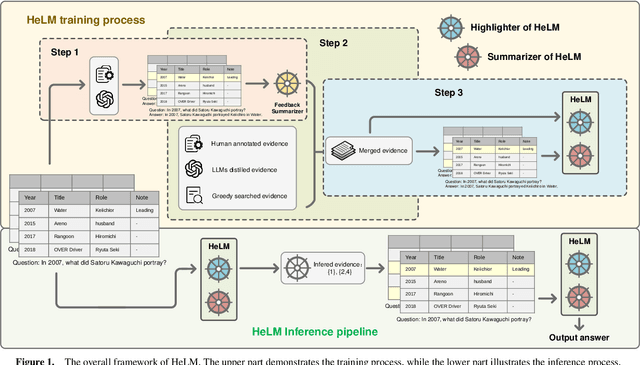
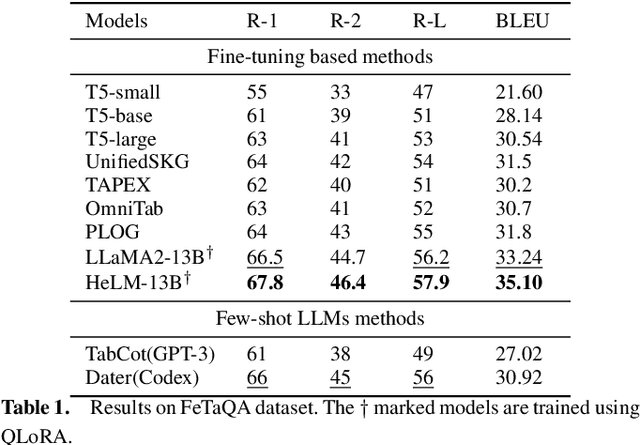

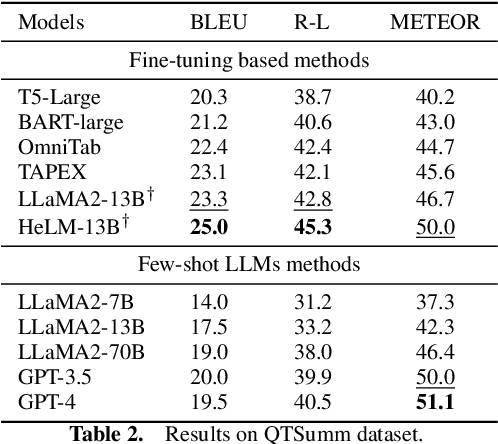
Large models have demonstrated significant progress across various domains, particularly in tasks related to text generation. In the domain of Table to Text, many Large Language Model (LLM)-based methods currently resort to modifying prompts to invoke public APIs, incurring potential costs and information leaks. With the advent of open-source large models, fine-tuning LLMs has become feasible. In this study, we conducted parameter-efficient fine-tuning on the LLaMA2 model. Distinguishing itself from previous fine-tuning-based table-to-text methods, our approach involves injecting reasoning information into the input by emphasizing table-specific row data. Our model consists of two modules: 1) a table reasoner that identifies relevant row evidence, and 2) a table summarizer that generates sentences based on the highlighted table. To facilitate this, we propose a search strategy to construct reasoning labels for training the table reasoner. On both the FetaQA and QTSumm datasets, our approach achieved state-of-the-art results. Additionally, we observed that highlighting input tables significantly enhances the model's performance and provides valuable interpretability.
Improving Global Forest Mapping by Semi-automatic Sample Labeling with Deep Learning on Google Earth Images
Aug 06, 2021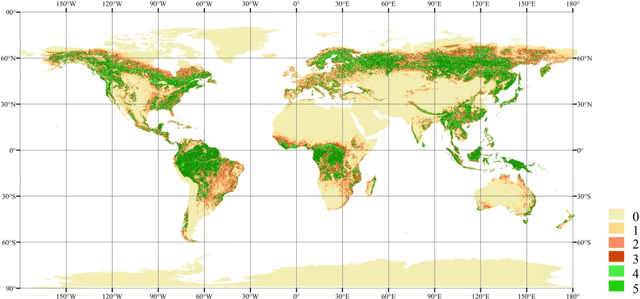
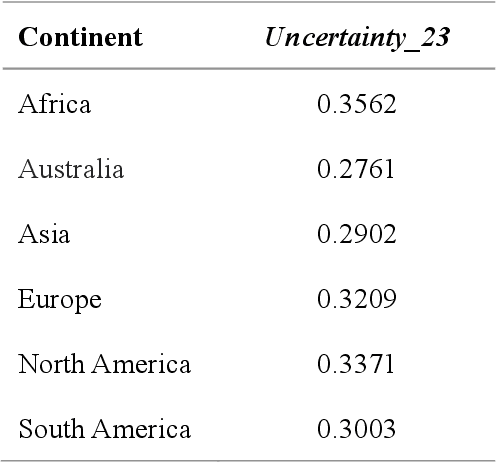
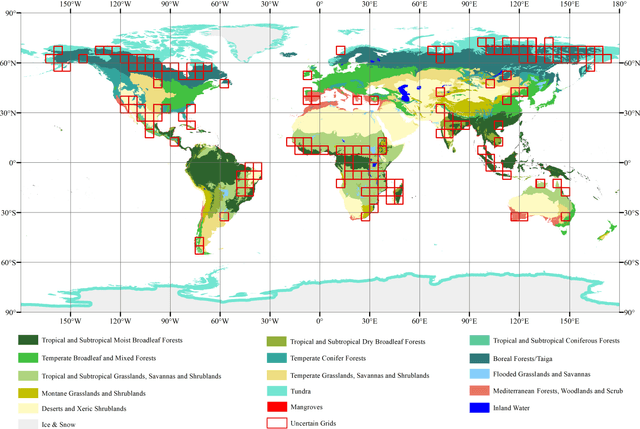
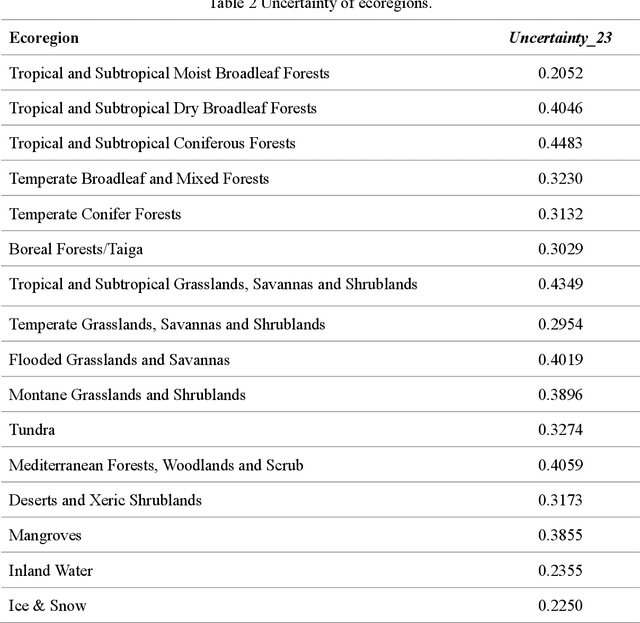
Global forest cover is critical to the provision of certain ecosystem services. With the advent of the google earth engine cloud platform, fine resolution global land cover mapping task could be accomplished in a matter of days instead of years. The amount of global forest cover (GFC) products has been steadily increasing in the last decades. However, it's hard for users to select suitable one due to great differences between these products, and the accuracy of these GFC products has not been verified on global scale. To provide guidelines for users and producers, it is urgent to produce a validation sample set at the global level. However, this labeling task is time and labor consuming, which has been the main obstacle to the progress of global land cover mapping. In this research, a labor-efficient semi-automatic framework is introduced to build a biggest ever Forest Sample Set (FSS) contained 395280 scattered samples categorized as forest, shrubland, grassland, impervious surface, etc. On the other hand, to provide guidelines for the users, we comprehensively validated the local and global mapping accuracy of all existing 30m GFC products, and analyzed and mapped the agreement of them. Moreover, to provide guidelines for the producers, optimal sampling strategy was proposed to improve the global forest classification. Furthermore, a new global forest cover named GlobeForest2020 has been generated, which proved to improve the previous highest state-of-the-art accuracies (obtained by Gong et al., 2017) by 2.77% in uncertain grids and by 1.11% in certain grids.