 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Global Forest Mapping by Semi-automatic Sample Labeling with Deep Learning on Google Earth Images
Aug 06, 2021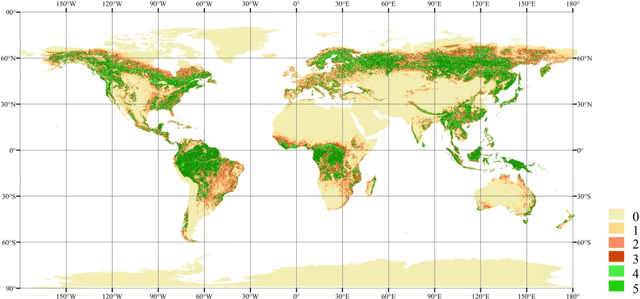
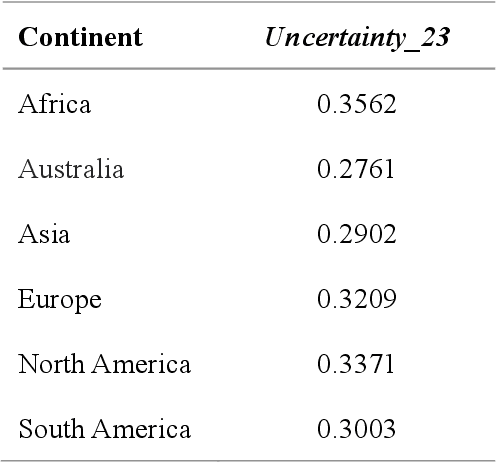
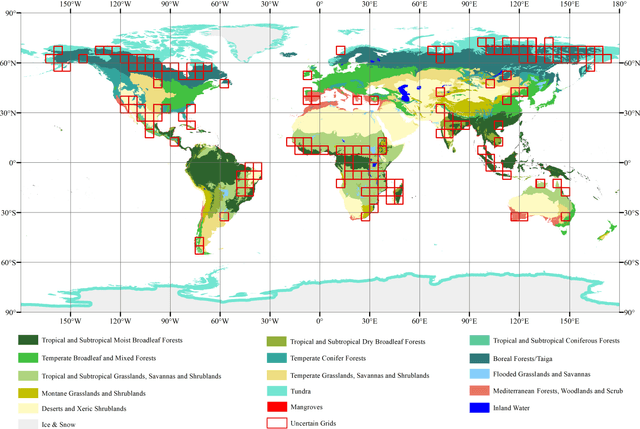
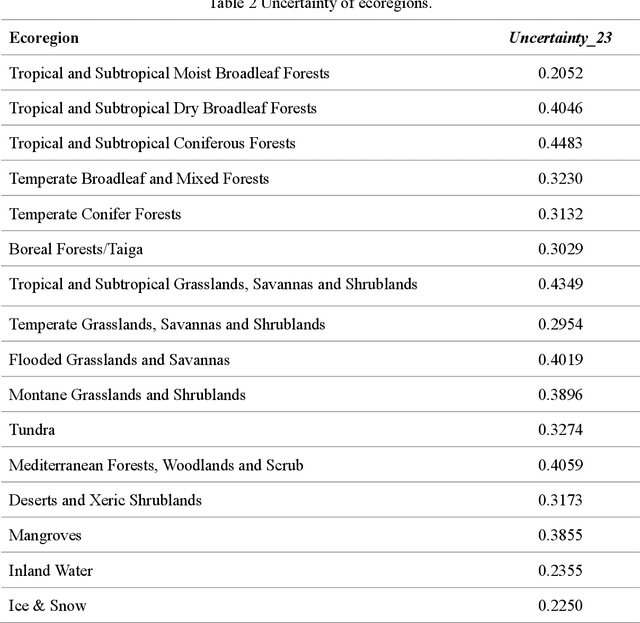
Global forest cover is critical to the provision of certain ecosystem services. With the advent of the google earth engine cloud platform, fine resolution global land cover mapping task could be accomplished in a matter of days instead of years. The amount of global forest cover (GFC) products has been steadily increasing in the last decades. However, it's hard for users to select suitable one due to great differences between these products, and the accuracy of these GFC products has not been verified on global scale. To provide guidelines for users and producers, it is urgent to produce a validation sample set at the global level. However, this labeling task is time and labor consuming, which has been the main obstacle to the progress of global land cover mapping. In this research, a labor-efficient semi-automatic framework is introduced to build a biggest ever Forest Sample Set (FSS) contained 395280 scattered samples categorized as forest, shrubland, grassland, impervious surface, etc. On the other hand, to provide guidelines for the users, we comprehensively validated the local and global mapping accuracy of all existing 30m GFC products, and analyzed and mapped the agreement of them. Moreover, to provide guidelines for the producers, optimal sampling strategy was proposed to improve the global forest classification. Furthermore, a new global forest cover named GlobeForest2020 has been generated, which proved to improve the previous highest state-of-the-art accuracies (obtained by Gong et al., 2017) by 2.77% in uncertain grids and by 1.11% in certain grids.
Extracting Lifestyle Factors for Alzheimer's Disease from Clinical Notes Using Deep Learning with Weak Supervision
Jan 25, 2021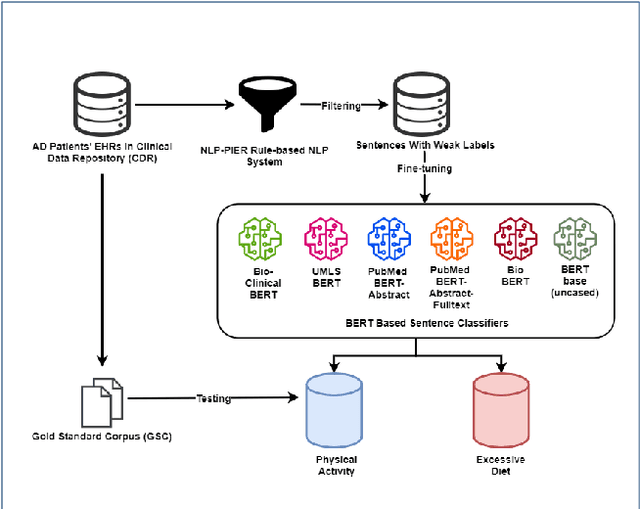
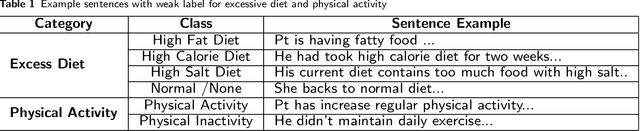
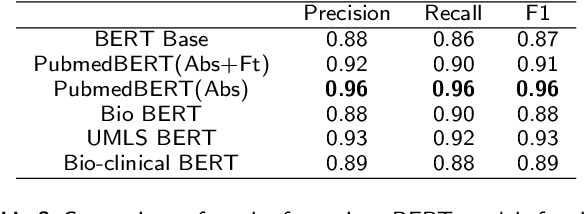
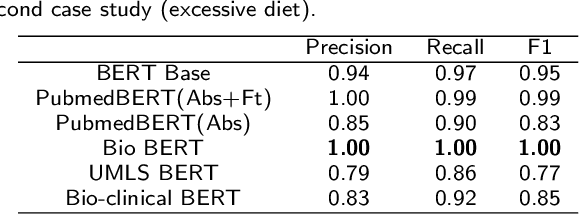
Since no effective therapies exist for Alzheimer's disease (AD), prevention has become more critical through lifestyle factor changes and interventions. Analyzing electronic health records (EHR) of patients with AD can help us better understand lifestyle's effect on AD. However, lifestyle information is typically stored in clinical narratives. Thus, the objective of the study was to demonstrate the feasibility of natural language processing (NLP) models to classify lifestyle factors (e.g., physical activity and excessive diet) from clinical texts. We automatically generated labels for the training data by using a rule-based NLP algorithm. We conducted weak supervision for pre-trained Bidirectional Encoder Representations from Transformers (BERT) models on the weakly labeled training corpus. These models include the BERT base model, PubMedBERT(abstracts + full text), PubMedBERT(only abstracts), Unified Medical Language System (UMLS) BERT, Bio BERT, and Bio-clinical BERT. We performed two case studies: physical activity and excessive diet, in order to validate the effectiveness of BERT models in classifying lifestyle factors for AD. These models were compared on the developed Gold Standard Corpus (GSC) on the two case studies. The PubmedBERT(Abs) model achieved the best performance for physical activity, with its precision, recall, and F-1 scores of 0.96, 0.96, and 0.96, respectively. Regarding classifying excessive diet, the Bio BERT model showed the highest performance with perfect precision, recall, and F-1 scores. The proposed approach leveraging weak supervision could significantly increase the sample size, which is required for training the deep learning models. The study also demonstrates the effectiveness of BERT models for extracting lifestyle factors for Alzheimer's disease from clinical notes.