 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResponsible AI for Earth Observation
May 31, 2024The convergence of artificial intelligence (AI) and Earth observation (EO) technologies has brought geoscience and remote sensing into an era of unparalleled capabilities. AI's transformative impact on data analysis, particularly derived from EO platforms, holds great promise in addressing global challenges such as environmental monitoring, disaster response and climate change analysis. However, the rapid integration of AI necessitates a careful examination of the responsible dimensions inherent in its application within these domains. In this paper, we represent a pioneering effort to systematically define the intersection of AI and EO, with a central focus on responsible AI practices. Specifically, we identify several critical components guiding this exploration from both academia and industry perspectives within the EO field: AI and EO for social good, mitigating unfair biases, AI security in EO, geo-privacy and privacy-preserving measures, as well as maintaining scientific excellence, open data, and guiding AI usage based on ethical principles. Furthermore, the paper explores potential opportunities and emerging trends, providing valuable insights for future research endeavors.
Beyond Low Rank: A Graph-Based Propagation Approach to Tensor Completion for Multi-Acquisition Scenarios
Dec 06, 2023Tensor completion refers to the problem of recovering the missing, corrupted or unobserved entries in data represented by tensors. In this paper, we tackle the tensor completion problem in the scenario in which multiple tensor acquisitions are available and do so without placing constraints on the underlying tensor's rank. Whereas previous tensor completion work primarily focuses on low-rank completion methods, we propose a novel graph-based diffusion approach to the problem. Referred to as GraphProp, the method propagates observed entries around a graph-based representation of the tensor in order to recover the missing entries. A series of experiments have been performed to validate the presented approach, including a synthetically-generated tensor recovery experiment which shows that the method can be used to recover both low and high rank tensor entries. The successful tensor completion capabilities of the approach are also demonstrated on a real-world completion problem from the field of multispectral remote sensing completion. Using data acquired from the Landsat 7 platform, we synthetically obscure image sections in order to simulate the scenario in which image acquisitions overlap only partially. In these tests, we benchmark against alternative tensor completion approaches as well as existing graph signal recovery methods, demonstrating the superior reconstruction performance of our method versus the state of the art.
Improving embedding of graphs with missing data by soft manifolds
Nov 29, 2023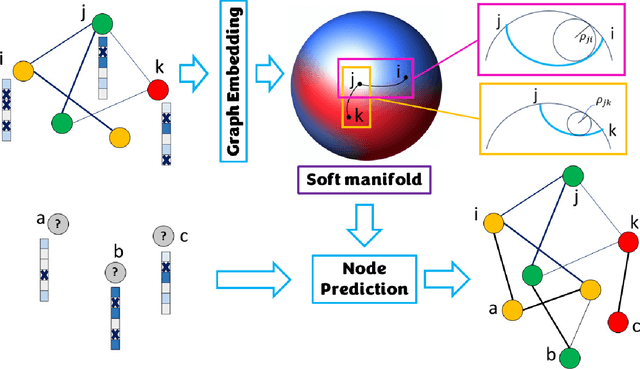
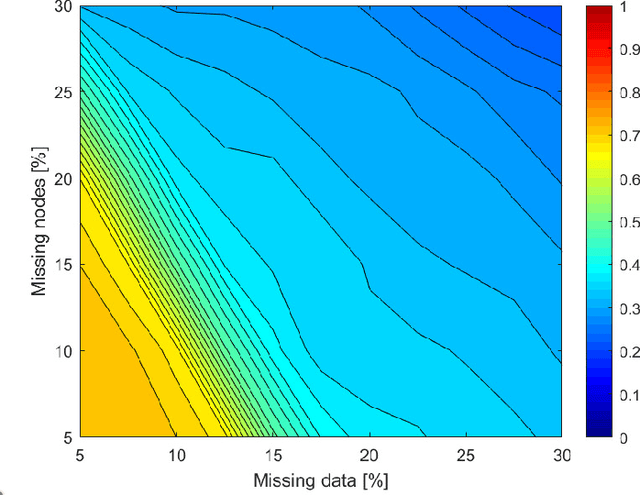
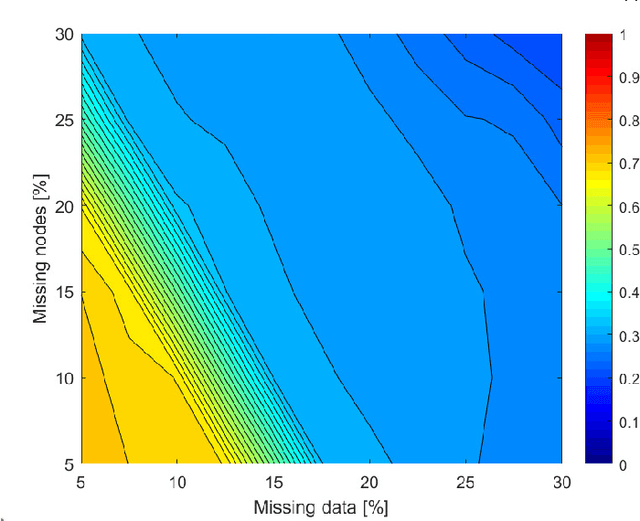
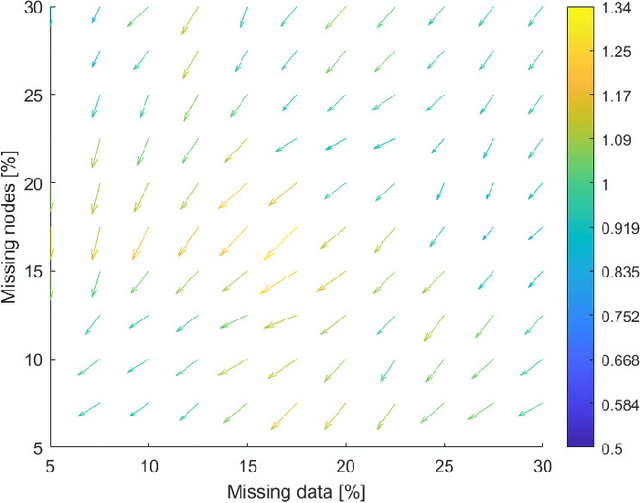
Embedding graphs in continous spaces is a key factor in designing and developing algorithms for automatic information extraction to be applied in diverse tasks (e.g., learning, inferring, predicting). The reliability of graph embeddings directly depends on how much the geometry of the continuous space matches the graph structure. Manifolds are mathematical structure that can enable to incorporate in their topological spaces the graph characteristics, and in particular nodes distances. State-of-the-art of manifold-based graph embedding algorithms take advantage of the assumption that the projection on a tangential space of each point in the manifold (corresponding to a node in the graph) would locally resemble a Euclidean space. Although this condition helps in achieving efficient analytical solutions to the embedding problem, it does not represent an adequate set-up to work with modern real life graphs, that are characterized by weighted connections across nodes often computed over sparse datasets with missing records. In this work, we introduce a new class of manifold, named soft manifold, that can solve this situation. In particular, soft manifolds are mathematical structures with spherical symmetry where the tangent spaces to each point are hypocycloids whose shape is defined according to the velocity of information propagation across the data points. Using soft manifolds for graph embedding, we can provide continuous spaces to pursue any task in data analysis over complex datasets. Experimental results on reconstruction tasks on synthetic and real datasets show how the proposed approach enable more accurate and reliable characterization of graphs in continuous spaces with respect to the state-of-the-art.
A graph representation based on fluid diffusion model for multimodal data analysis: theoretical aspects and enhanced community detection
Dec 07, 2021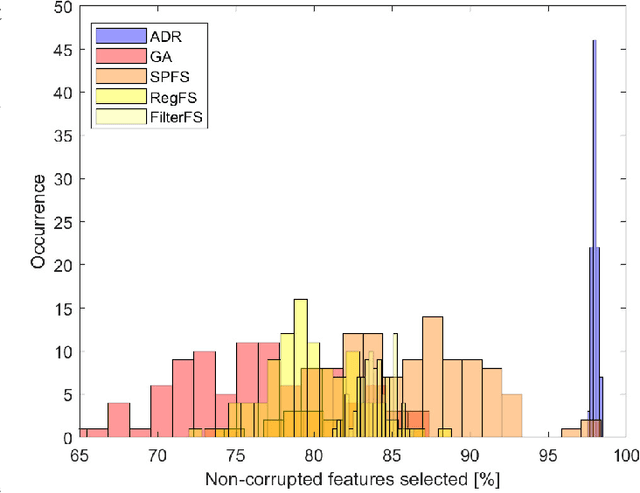
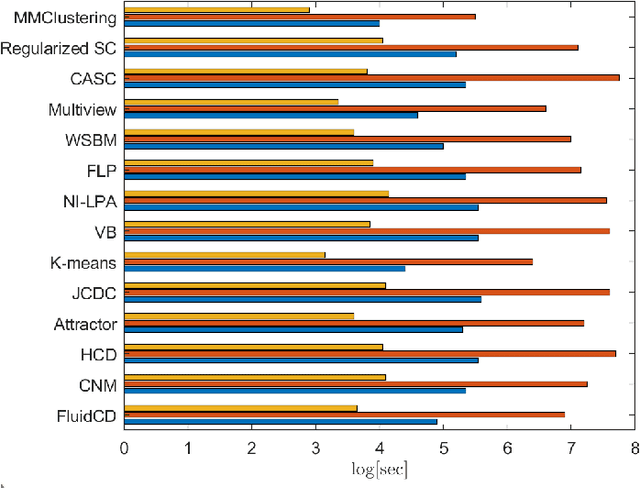


Representing data by means of graph structures identifies one of the most valid approach to extract information in several data analysis applications. This is especially true when multimodal datasets are investigated, as records collected by means of diverse sensing strategies are taken into account and explored. Nevertheless, classic graph signal processing is based on a model for information propagation that is configured according to heat diffusion mechanism. This system provides several constraints and assumptions on the data properties that might be not valid for multimodal data analysis, especially when large scale datasets collected from heterogeneous sources are considered, so that the accuracy and robustness of the outcomes might be severely jeopardized. In this paper, we introduce a novel model for graph definition based on fluid diffusion. The proposed approach improves the ability of graph-based data analysis to take into account several issues of modern data analysis in operational scenarios, so to provide a platform for precise, versatile, and efficient understanding of the phenomena underlying the records under exam, and to fully exploit the potential provided by the diversity of the records in obtaining a thorough characterization of the data and their significance. In this work, we focus our attention to using this fluid diffusion model to drive a community detection scheme, i.e., to divide multimodal datasets into many groups according to similarity among nodes in an unsupervised fashion. Experimental results achieved by testing real multimodal datasets in diverse application scenarios show that our method is able to strongly outperform state-of-the-art schemes for community detection in multimodal data analysis.
Improving Global Forest Mapping by Semi-automatic Sample Labeling with Deep Learning on Google Earth Images
Aug 06, 2021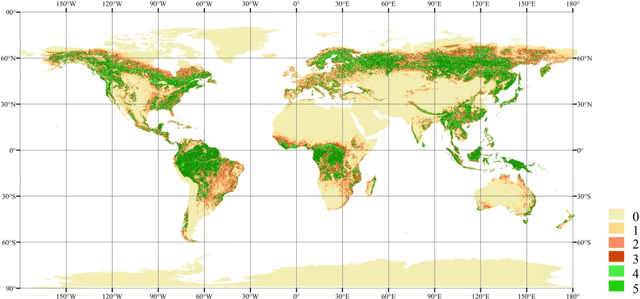
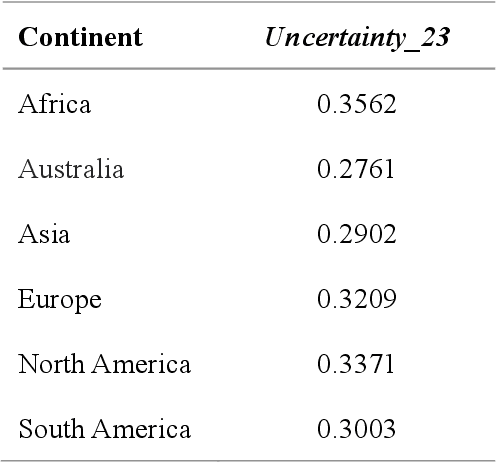
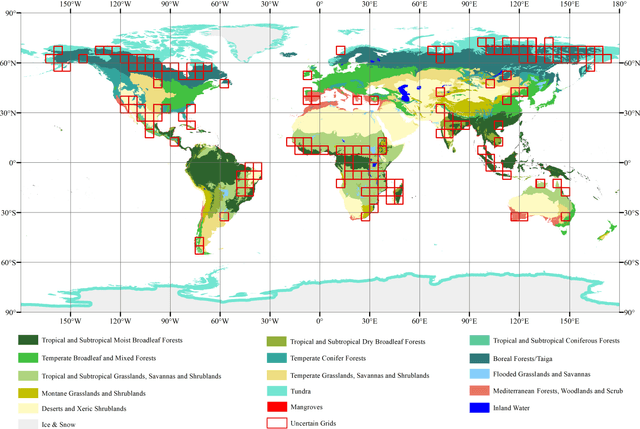
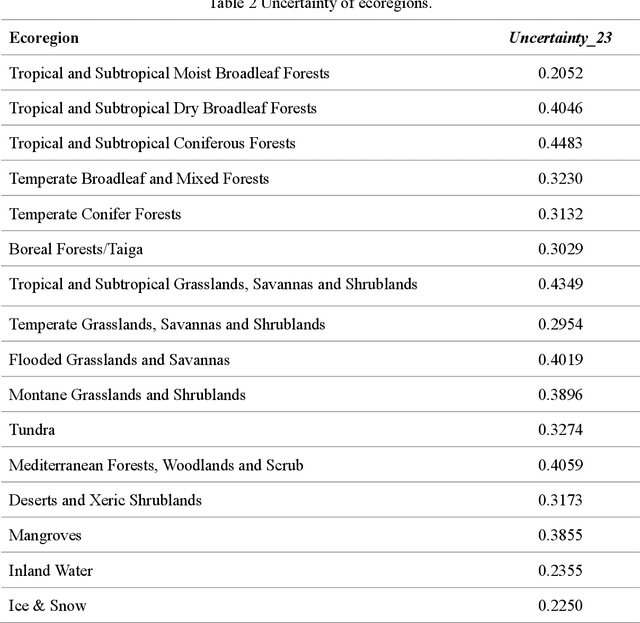
Global forest cover is critical to the provision of certain ecosystem services. With the advent of the google earth engine cloud platform, fine resolution global land cover mapping task could be accomplished in a matter of days instead of years. The amount of global forest cover (GFC) products has been steadily increasing in the last decades. However, it's hard for users to select suitable one due to great differences between these products, and the accuracy of these GFC products has not been verified on global scale. To provide guidelines for users and producers, it is urgent to produce a validation sample set at the global level. However, this labeling task is time and labor consuming, which has been the main obstacle to the progress of global land cover mapping. In this research, a labor-efficient semi-automatic framework is introduced to build a biggest ever Forest Sample Set (FSS) contained 395280 scattered samples categorized as forest, shrubland, grassland, impervious surface, etc. On the other hand, to provide guidelines for the users, we comprehensively validated the local and global mapping accuracy of all existing 30m GFC products, and analyzed and mapped the agreement of them. Moreover, to provide guidelines for the producers, optimal sampling strategy was proposed to improve the global forest classification. Furthermore, a new global forest cover named GlobeForest2020 has been generated, which proved to improve the previous highest state-of-the-art accuracies (obtained by Gong et al., 2017) by 2.77% in uncertain grids and by 1.11% in certain grids.
Enhancing ensemble learning and transfer learning in multimodal data analysis by adaptive dimensionality reduction
May 08, 2021
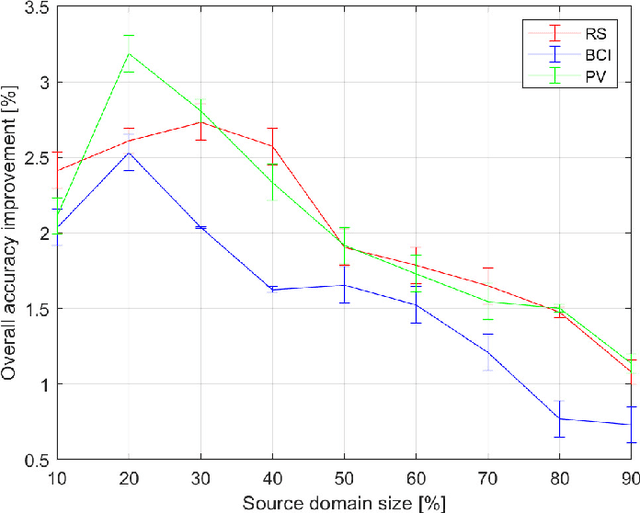
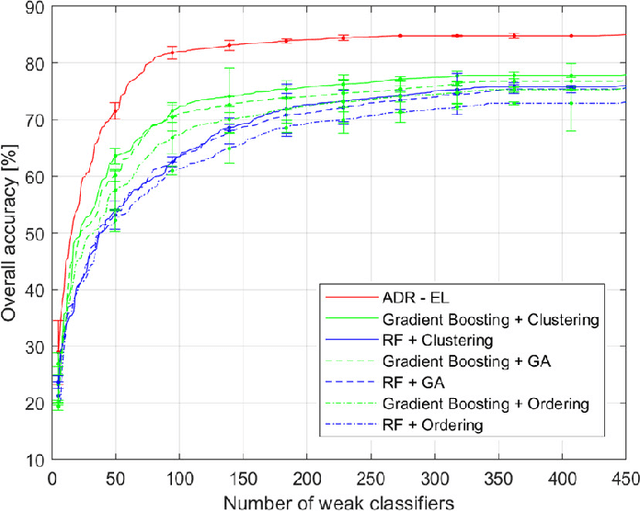

Modern data analytics take advantage of ensemble learning and transfer learning approaches to tackle some of the most relevant issues in data analysis, such as lack of labeled data to use to train the analysis models, sparsity of the information, and unbalanced distributions of the records. Nonetheless, when applied to multimodal datasets (i.e., datasets acquired by means of multiple sensing techniques or strategies), the state-of-theart methods for ensemble learning and transfer learning might show some limitations. In fact, in multimodal data analysis, not all observations would show the same level of reliability or information quality, nor an homogeneous distribution of errors and uncertainties. This condition might undermine the classic assumptions ensemble learning and transfer learning methods rely on. In this work, we propose an adaptive approach for dimensionality reduction to overcome this issue. By means of a graph theory-based approach, the most relevant features across variable size subsets of the considered datasets are identified. This information is then used to set-up ensemble learning and transfer learning architectures. We test our approach on multimodal datasets acquired in diverse research fields (remote sensing, brain-computer interfaces, photovoltaic energy). Experimental results show the validity and the robustness of our approach, able to outperform state-of-the-art techniques.
Super-resolution-based Change Detection Network with Stacked Attention Module for Images with Different Resolutions
Feb 27, 2021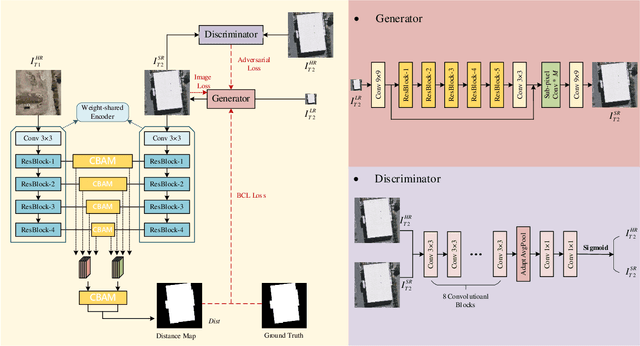

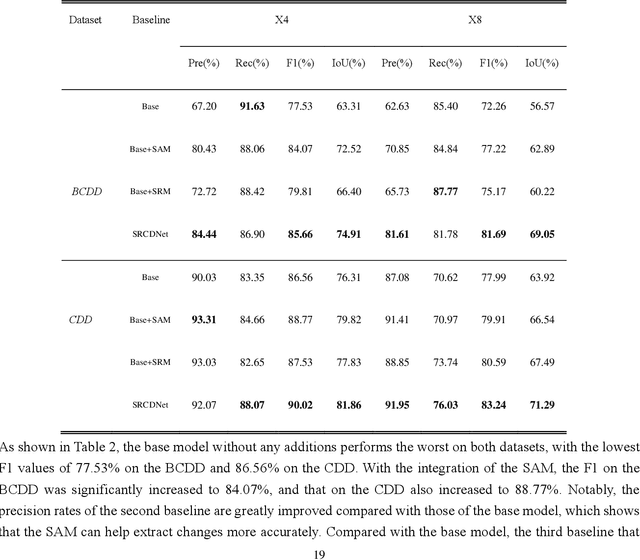

Change detection, which aims to distinguish surface changes based on bi-temporal images, plays a vital role in ecological protection and urban planning. Since high resolution (HR) images cannot be typically acquired continuously over time, bi-temporal images with different resolutions are often adopted for change detection in practical applications. Traditional subpixel-based methods for change detection using images with different resolutions may lead to substantial error accumulation when HR images are employed; this is because of intraclass heterogeneity and interclass similarity. Therefore, it is necessary to develop a novel method for change detection using images with different resolutions, that is more suitable for HR images. To this end, we propose a super-resolution-based change detection network (SRCDNet) with a stacked attention module. The SRCDNet employs a super resolution (SR) module containing a generator and a discriminator to directly learn SR images through adversarial learning and overcome the resolution difference between bi-temporal images. To enhance the useful information in multi-scale features, a stacked attention module consisting of five convolutional block attention modules (CBAMs) is integrated to the feature extractor. The final change map is obtained through a metric learning-based change decision module, wherein a distance map between bi-temporal features is calculated. The experimental results demonstrate the superiority of the proposed method, which not only outperforms all baselines -with the highest F1 scores of 87.40% on the building change detection dataset and 92.94% on the change detection dataset -but also obtains the best accuracies on experiments performed with images having a 4x and 8x resolution difference. The source code of SRCDNet will be available at https://github.com/liumency/SRCDNet.