 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLDPoly: Latent Diffusion for Polygonal Road Outline Extraction in Large-Scale Topographic Mapping
Apr 29, 2025Polygonal road outline extraction from high-resolution aerial images is an important task in large-scale topographic mapping, where roads are represented as vectorized polygons, capturing essential geometric features with minimal vertex redundancy. Despite its importance, no existing method has been explicitly designed for this task. While polygonal building outline extraction has been extensively studied, the unique characteristics of roads, such as branching structures and topological connectivity, pose challenges to these methods. To address this gap, we introduce LDPoly, the first dedicated framework for extracting polygonal road outlines from high-resolution aerial images. Our method leverages a novel Dual-Latent Diffusion Model with a Channel-Embedded Fusion Module, enabling the model to simultaneously generate road masks and vertex heatmaps. A tailored polygonization method is then applied to obtain accurate vectorized road polygons with minimal vertex redundancy. We evaluate LDPoly on a new benchmark dataset, Map2ImLas, which contains detailed polygonal annotations for various topographic objects in several Dutch regions. Our experiments include both in-region and cross-region evaluations, with the latter designed to assess the model's generalization performance on unseen regions. Quantitative and qualitative results demonstrate that LDPoly outperforms state-of-the-art polygon extraction methods across various metrics, including pixel-level coverage, vertex efficiency, polygon regularity, and road connectivity. We also design two new metrics to assess polygon simplicity and boundary smoothness. Moreover, this work represents the first application of diffusion models for extracting precise vectorized object outlines without redundant vertices from remote-sensing imagery, paving the way for future advancements in this field.
RoIPoly: Vectorized Building Outline Extraction Using Vertex and Logit Embeddings
Jul 20, 2024Polygonal building outlines are crucial for geographic and cartographic applications. The existing approaches for outline extraction from aerial or satellite imagery are typically decomposed into subtasks, e.g., building masking and vectorization, or treat this task as a sequence-to-sequence prediction of ordered vertices. The former lacks efficiency, and the latter often generates redundant vertices, both resulting in suboptimal performance. To handle these issues, we propose a novel Region-of-Interest (RoI) query-based approach called RoIPoly. Specifically, we formulate each vertex as a query and constrain the query attention on the most relevant regions of a potential building, yielding reduced computational overhead and more efficient vertex level interaction. Moreover, we introduce a novel learnable logit embedding to facilitate vertex classification on the attention map; thus, no post-processing is needed for redundant vertex removal. We evaluated our method on the vectorized building outline extraction dataset CrowdAI and the 2D floorplan reconstruction dataset Structured3D. On the CrowdAI dataset, RoIPoly with a ResNet50 backbone outperforms existing methods with the same or better backbones on most MS-COCO metrics, especially on small buildings, and achieves competitive results in polygon quality and vertex redundancy without any post-processing. On the Structured3D dataset, our method achieves the second-best performance on most metrics among existing methods dedicated to 2D floorplan reconstruction, demonstrating our cross-domain generalization capability. The code will be released upon acceptance of this paper.
PolyR-CNN: R-CNN for end-to-end polygonal building outline extraction
Jul 20, 2024



Polygonal building outline extraction has been a research focus in recent years. Most existing methods have addressed this challenging task by decomposing it into several subtasks and employing carefully designed architectures. Despite their accuracy, such pipelines often introduce inefficiencies during training and inference. This paper presents an end-to-end framework, denoted as PolyR-CNN, which offers an efficient and fully integrated approach to predict vectorized building polygons and bounding boxes directly from remotely sensed images. Notably, PolyR-CNN leverages solely the features of the Region of Interest (RoI) for the prediction, thereby mitigating the necessity for complex designs. Furthermore, we propose a novel scheme with PolyR-CNN to extract detailed outline information from polygon vertex coordinates, termed vertex proposal feature, to guide the RoI features to predict more regular buildings. PolyR-CNN demonstrates the capacity to deal with buildings with holes through a simple post-processing method on the Inria dataset. Comprehensive experiments conducted on the CrowdAI dataset show that PolyR-CNN achieves competitive accuracy compared to state-of-the-art methods while significantly improving computational efficiency, i.e., achieving 79.2 Average Precision (AP), exhibiting a 15.9 AP gain and operating 2.5 times faster and four times lighter than the well-established end-to-end method PolyWorld. Replacing the backbone with a simple ResNet-50, PolyR-CNN maintains a 71.1 AP while running four times faster than PolyWorld.
Responsible AI for Earth Observation
May 31, 2024The convergence of artificial intelligence (AI) and Earth observation (EO) technologies has brought geoscience and remote sensing into an era of unparalleled capabilities. AI's transformative impact on data analysis, particularly derived from EO platforms, holds great promise in addressing global challenges such as environmental monitoring, disaster response and climate change analysis. However, the rapid integration of AI necessitates a careful examination of the responsible dimensions inherent in its application within these domains. In this paper, we represent a pioneering effort to systematically define the intersection of AI and EO, with a central focus on responsible AI practices. Specifically, we identify several critical components guiding this exploration from both academia and industry perspectives within the EO field: AI and EO for social good, mitigating unfair biases, AI security in EO, geo-privacy and privacy-preserving measures, as well as maintaining scientific excellence, open data, and guiding AI usage based on ethical principles. Furthermore, the paper explores potential opportunities and emerging trends, providing valuable insights for future research endeavors.
Towards Global Glacier Mapping with Deep Learning and Open Earth Observation Data
Jan 25, 2024Accurate global glacier mapping is critical for understanding climate change impacts. It is challenged by glacier diversity, difficult-to-classify debris and big data processing. Here we propose Glacier-VisionTransformer-U-Net (GlaViTU), a convolutional-transformer deep learning model, and five strategies for multitemporal global-scale glacier mapping using open satellite imagery. Assessing the spatial, temporal and cross-sensor generalisation shows that our best strategy achieves intersection over union >0.85 on previously unobserved images in most cases, which drops to >0.75 for debris-rich areas such as High-Mountain Asia and increases to >0.90 for regions dominated by clean ice. Additionally, adding synthetic aperture radar data, namely, backscatter and interferometric coherence, increases the accuracy in all regions where available. The calibrated confidence for glacier extents is reported making the predictions more reliable and interpretable. We also release a benchmark dataset that covers 9% of glaciers worldwide. Our results support efforts towards automated multitemporal and global glacier mapping.
DeepMerge: Deep Learning-Based Region-Merging for Image Segmentation
May 31, 2023

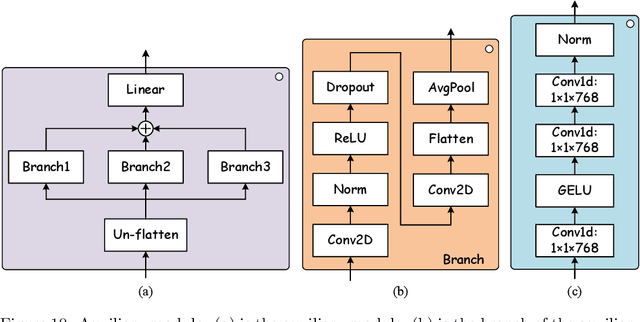
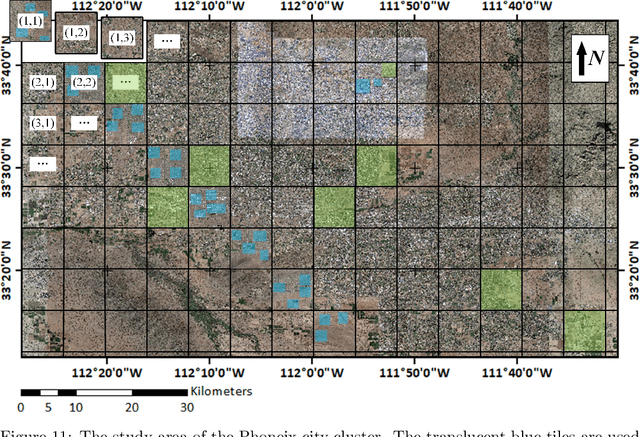
Accurate segmentation of large areas from very high spatial-resolution (VHR) remote sensing imagery remains a challenging issue in image analysis. Existing supervised and unsupervised methods both suffer from the large variance of object sizes and the difficulty in scale selection, which often result in poor segmentation accuracies. To address the above challenges, we propose a deep learning-based region-merging method (DeepMerge) to handle the segmentation in large VHR images by integrating a Transformer with a multi-level embedding module, a segment-based feature embedding module and a region-adjacency graph model. In addition, we propose a modified binary tree sampling method to generate multi-level inputs from initial segmentation results, serving as inputs for the DeepMerge model. To our best knowledge, the proposed method is the first to use deep learning to learn the similarity between adjacent segments for region-merging. The proposed DeepMerge method is validated using a remote sensing image of 0.55m resolution covering an area of 5,660 km^2 acquired from Google Earth. The experimental results show that the proposed DeepMerge with the highest F value (0.9446) and the lowest TE (0.0962) and ED2 (0.8989) is able to correctly segment objects of different sizes and outperforms all selected competing segmentation methods from both quantitative and qualitative assessments.
Multiresolution Fully Convolutional Networks to detect Clouds and Snow through Optical Satellite Images
Jan 07, 2022

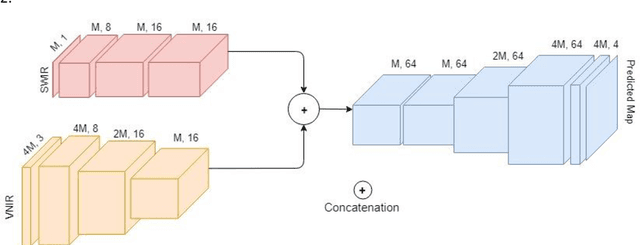

Clouds and snow have similar spectral features in the visible and near-infrared (VNIR) range and are thus difficult to distinguish from each other in high resolution VNIR images. We address this issue by introducing a shortwave-infrared (SWIR) band where clouds are highly reflective, and snow is absorptive. As SWIR is typically of a lower resolution compared to VNIR, this study proposes a multiresolution fully convolutional neural network (FCN) that can effectively detect clouds and snow in VNIR images. We fuse the multiresolution bands within a deep FCN and perform semantic segmentation at the higher, VNIR resolution. Such a fusion-based classifier, trained in an end-to-end manner, achieved 94.31% overall accuracy and an F1 score of 97.67% for clouds on Resourcesat-2 data captured over the state of Uttarakhand, India. These scores were found to be 30% higher than a Random Forest classifier, and 10% higher than a standalone single-resolution FCN. Apart from being useful for cloud detection purposes, the study also highlights the potential of convolutional neural networks for multi-sensor fusion problems.
Deep Learning and Earth Observation to Support the Sustainable Development Goals
Dec 21, 2021
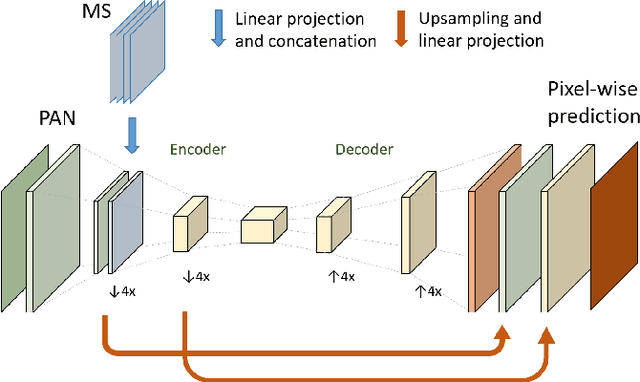

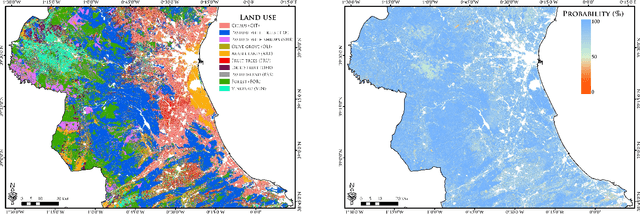
The synergistic combination of deep learning models and Earth observation promises significant advances to support the sustainable development goals (SDGs). New developments and a plethora of applications are already changing the way humanity will face the living planet challenges. This paper reviews current deep learning approaches for Earth observation data, along with their application towards monitoring and achieving the SDGs most impacted by the rapid development of deep learning in Earth observation. We systematically review case studies to 1) achieve zero hunger, 2) sustainable cities, 3) deliver tenure security, 4) mitigate and adapt to climate change, and 5) preserve biodiversity. Important societal, economic and environmental implications are concerned. Exciting times ahead are coming where algorithms and Earth data can help in our endeavor to address the climate crisis and support more sustainable development.
Recent Advances in Domain Adaptation for the Classification of Remote Sensing Data
Apr 15, 2021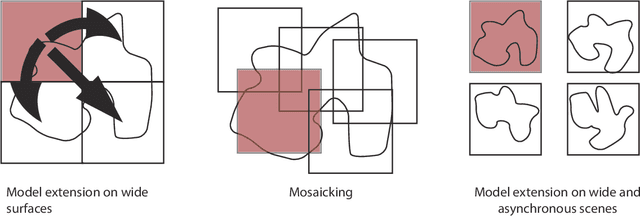
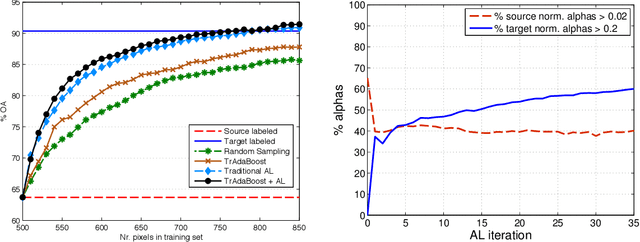
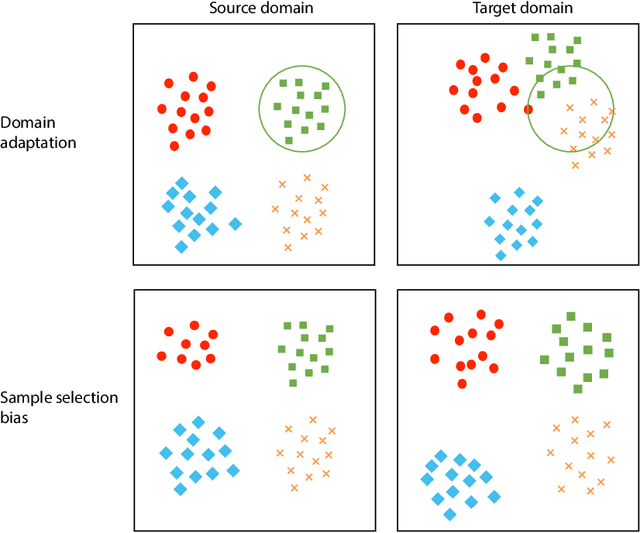
The success of supervised classification of remotely sensed images acquired over large geographical areas or at short time intervals strongly depends on the representativity of the samples used to train the classification algorithm and to define the model. When training samples are collected from an image (or a spatial region) different from the one used for mapping, spectral shifts between the two distributions are likely to make the model fail. Such shifts are generally due to differences in acquisition and atmospheric conditions or to changes in the nature of the object observed. In order to design classification methods that are robust to data-set shifts, recent remote sensing literature has considered solutions based on domain adaptation (DA) approaches. Inspired by machine learning literature, several DA methods have been proposed to solve specific problems in remote sensing data classification. This paper provides a critical review of the recent advances in DA for remote sensing and presents an overview of methods divided into four categories: i) invariant feature selection; ii) representation matching; iii) adaptation of classifiers and iv) selective sampling. We provide an overview of recent methodologies, as well as examples of application of the considered techniques to real remote sensing images characterized by very high spatial and spectral resolution. Finally, we propose guidelines to the selection of the method to use in real application scenarios.
Despeckling Polarimetric SAR Data Using a Multi-Stream Complex-Valued Fully Convolutional Network
Mar 12, 2021

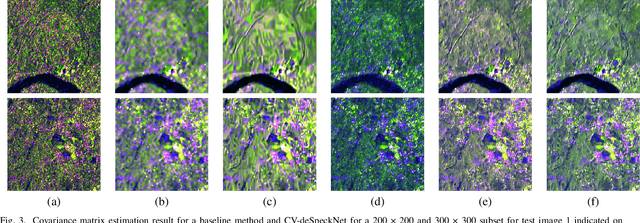

A Polarimetric Synthetic Aperture Radar (PolSAR) sensor is able to collect images in different polarization states, making it a rich source of information for target characterization. PolSAR images are inherently affected by speckle. Therefore, before deriving ad hoc products from the data, the polarimetric covariance matrix needs to be estimated by reducing speckle. In recent years, deep learning based despeckling methods have started to evolve from single channel SAR images to PolSAR images. To this aim, deep learning based approaches separate the real and imaginary components of the complex-valued covariance matrix and use them as independent channels in a standard convolutional neural networks. However, this approach neglects the mathematical relationship that exists between the real and imaginary components, resulting in sub-optimal output. Here, we propose a multi-stream complex-valued fully convolutional network to reduce speckle and effectively estimate the PolSAR covariance matrix. To evaluate the performance of CV-deSpeckNet, we used Sentinel-1 dual polarimetric SAR images to compare against its real-valued counterpart, that separates the real and imaginary parts of the complex covariance matrix. CV-deSpeckNet was also compared against the state of the art PolSAR despeckling methods. The results show CV-deSpeckNet was able to be trained with a fewer number of samples, has a higher generalization capability and resulted in a higher accuracy than its real-valued counterpart and state-of-the-art PolSAR despeckling methods. These results showcase the potential of complex-valued deep learning for PolSAR despeckling.