 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Global Glacier Mapping with Deep Learning and Open Earth Observation Data
Jan 25, 2024Accurate global glacier mapping is critical for understanding climate change impacts. It is challenged by glacier diversity, difficult-to-classify debris and big data processing. Here we propose Glacier-VisionTransformer-U-Net (GlaViTU), a convolutional-transformer deep learning model, and five strategies for multitemporal global-scale glacier mapping using open satellite imagery. Assessing the spatial, temporal and cross-sensor generalisation shows that our best strategy achieves intersection over union >0.85 on previously unobserved images in most cases, which drops to >0.75 for debris-rich areas such as High-Mountain Asia and increases to >0.90 for regions dominated by clean ice. Additionally, adding synthetic aperture radar data, namely, backscatter and interferometric coherence, increases the accuracy in all regions where available. The calibrated confidence for glacier extents is reported making the predictions more reliable and interpretable. We also release a benchmark dataset that covers 9% of glaciers worldwide. Our results support efforts towards automated multitemporal and global glacier mapping.
DeepMerge: Deep Learning-Based Region-Merging for Image Segmentation
May 31, 2023

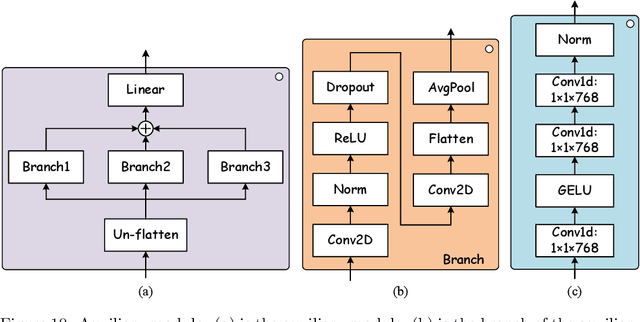
Accurate segmentation of large areas from very high spatial-resolution (VHR) remote sensing imagery remains a challenging issue in image analysis. Existing supervised and unsupervised methods both suffer from the large variance of object sizes and the difficulty in scale selection, which often result in poor segmentation accuracies. To address the above challenges, we propose a deep learning-based region-merging method (DeepMerge) to handle the segmentation in large VHR images by integrating a Transformer with a multi-level embedding module, a segment-based feature embedding module and a region-adjacency graph model. In addition, we propose a modified binary tree sampling method to generate multi-level inputs from initial segmentation results, serving as inputs for the DeepMerge model. To our best knowledge, the proposed method is the first to use deep learning to learn the similarity between adjacent segments for region-merging. The proposed DeepMerge method is validated using a remote sensing image of 0.55m resolution covering an area of 5,660 km^2 acquired from Google Earth. The experimental results show that the proposed DeepMerge with the highest F value (0.9446) and the lowest TE (0.0962) and ED2 (0.8989) is able to correctly segment objects of different sizes and outperforms all selected competing segmentation methods from both quantitative and qualitative assessments.
3D Fully Convolutional Neural Networks with Intersection Over Union Loss for Crop Mapping from Multi-Temporal Satellite Images
Feb 15, 2021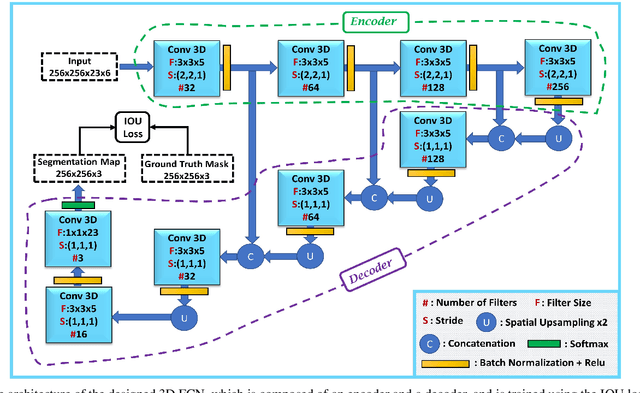
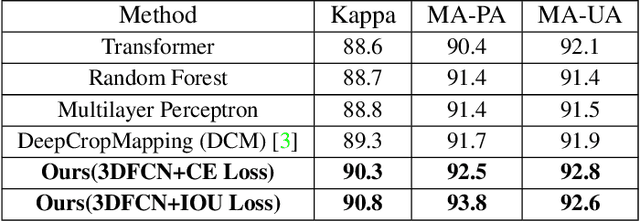
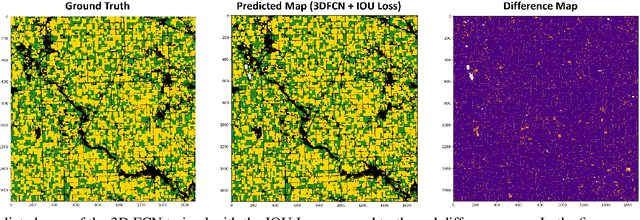
Information on cultivated crops is relevant for a large number of food security studies. Different scientific efforts are dedicated to generate this information from remote sensing images by means of machine learning methods. Unfortunately, these methods do not account for the spatial-temporal relationships inherent in remote sensing images. In our paper, we explore the capability of a 3D Fully Convolutional Neural Network (FCN) to map crop types from multi-temporal images. In addition, we propose the Intersection Over Union (IOU) loss function for increasing the overlap between the predicted classes and ground truth data. The proposed method was applied to identify soybean and corn from a study area situated in the US corn belt using multi-temporal Landsat images. The study shows that our method outperforms related methods, obtaining a Kappa coefficient of 90.8%. We conclude that using the IOU Loss function provides a superior choice to learn individual crop types.
Recurrent Multiresolution Convolutional Networks for VHR Image Classification
Jun 15, 2018



Classification of very high resolution (VHR) satellite images has three major challenges: 1) inherent low intra-class and high inter-class spectral similarities, 2) mismatching resolution of available bands, and 3) the need to regularize noisy classification maps. Conventional methods have addressed these challenges by adopting separate stages of image fusion, feature extraction, and post-classification map regularization. These processing stages, however, are not jointly optimizing the classification task at hand. In this study, we propose a single-stage framework embedding the processing stages in a recurrent multiresolution convolutional network trained in an end-to-end manner. The feedforward version of the network, called FuseNet, aims to match the resolution of the panchromatic and multispectral bands in a VHR image using convolutional layers with corresponding downsampling and upsampling operations. Contextual label information is incorporated into FuseNet by means of a recurrent version called ReuseNet. We compared FuseNet and ReuseNet against the use of separate processing steps for both image fusion, e.g. pansharpening and resampling through interpolation, and map regularization such as conditional random fields. We carried out our experiments on a land cover classification task using a Worldview-03 image of Quezon City, Philippines and the ISPRS 2D semantic labeling benchmark dataset of Vaihingen, Germany. FuseNet and ReuseNet surpass the baseline approaches in both quantitative and qualitative results.