 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Bark Beetle Attacks using Hyperspectral PRISMA Data and Few-Shot Learning
Nov 14, 2025Bark beetle infestations represent a serious challenge for maintaining the health of coniferous forests. This paper proposes a few-shot learning approach leveraging contrastive learning to detect bark beetle infestations using satellite PRISMA hyperspectral data. The methodology is based on a contrastive learning framework to pre-train a one-dimensional CNN encoder, enabling the extraction of robust feature representations from hyperspectral data. These extracted features are subsequently utilized as input to support vector regression estimators, one for each class, trained on few labeled samples to estimate the proportions of healthy, attacked by bark beetle, and dead trees for each pixel. Experiments on the area of study in the Dolomites show that our method outperforms the use of original PRISMA spectral bands and of Sentinel-2 data. The results indicate that PRISMA hyperspectral data combined with few-shot learning offers significant advantages for forest health monitoring.
A class-driven hierarchical ResNet for classification of multispectral remote sensing images
Oct 09, 2025This work presents a multitemporal class-driven hierarchical Residual Neural Network (ResNet) designed for modelling the classification of Time Series (TS) of multispectral images at different semantical class levels. The architecture consists of a modification of the ResNet where we introduce additional branches to perform the classification at the different hierarchy levels and leverage on hierarchy-penalty maps to discourage incoherent hierarchical transitions within the classification. In this way, we improve the discrimination capabilities of classes at different levels of semantic details and train a modular architecture that can be used as a backbone network for introducing new specific classes and additional tasks considering limited training samples available. We exploit the class-hierarchy labels to train efficiently the different layers of the architecture, allowing the first layers to train faster on the first levels of the hierarchy modeling general classes (i.e., the macro-classes) and the intermediate classes, while using the last ones to discriminate more specific classes (i.e., the micro-classes). In this way, the targets are constrained in following the hierarchy defined, improving the classification of classes at the most detailed level. The proposed modular network has intrinsic adaptation capability that can be obtained through fine tuning. The experimental results, obtained on two tiles of the Amazonian Forest on 12 monthly composites of Sentinel 2 images acquired during 2019, demonstrate the effectiveness of the hierarchical approach in both generalizing over different hierarchical levels and learning discriminant features for an accurate classification at the micro-class level on a new target area, with a better representation of the minoritarian classes.
* 11 pages, 2 figures, accepted conference paper at SPIE REMOTE SENSING, 3-7 September 2023, Amsterdam, Netherlands
Bayesian Modelling of Multi-Year Crop Type Classification Using Deep Neural Networks and Hidden Markov Models
Oct 08, 2025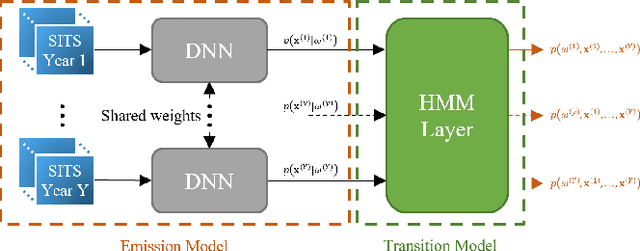
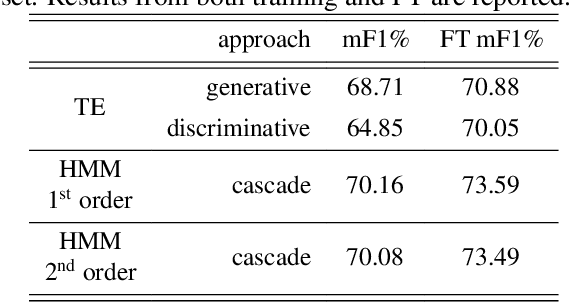

The temporal consistency of yearly land-cover maps is of great importance to model the evolution and change of the land cover over the years. In this paper, we focus the attention on a novel approach to classification of yearly satellite image time series (SITS) that combines deep learning with Bayesian modelling, using Hidden Markov Models (HMMs) integrated with Transformer Encoder (TE) based DNNs. The proposed approach aims to capture both i) intricate temporal correlations in yearly SITS and ii) specific patterns in multiyear crop type sequences. It leverages the cascade classification of an HMM layer built on top of the TE, discerning consistent yearly crop-type sequences. Validation on a multiyear crop type classification dataset spanning 47 crop types and six years of Sentinel-2 acquisitions demonstrates the importance of modelling temporal consistency in the predicted labels. HMMs enhance the overall performance and F1 scores, emphasising the effectiveness of the proposed approach.
* 5 pages, 1 figure, accepted conference paper at IEEE International Geoscience and Remote Sensing Symposium, 7-12 July 2024, Athens, Greece
A Semantics-Aware Hierarchical Self-Supervised Approach to Classification of Remote Sensing Images
Oct 06, 2025Deep learning has become increasingly important in remote sensing image classification due to its ability to extract semantic information from complex data. Classification tasks often include predefined label hierarchies that represent the semantic relationships among classes. However, these hierarchies are frequently overlooked, and most approaches focus only on fine-grained classification schemes. In this paper, we present a novel Semantics-Aware Hierarchical Consensus (SAHC) method for learning hierarchical features and relationships by integrating hierarchy-specific classification heads within a deep network architecture, each specialized in different degrees of class granularity. The proposed approach employs trainable hierarchy matrices, which guide the network through the learning of the hierarchical structure in a self-supervised manner. Furthermore, we introduce a hierarchical consensus mechanism to ensure consistent probability distributions across different hierarchical levels. This mechanism acts as a weighted ensemble being able to effectively leverage the inherent structure of the hierarchical classification task. The proposed SAHC method is evaluated on three benchmark datasets with different degrees of hierarchical complexity on different tasks, using distinct backbone architectures to effectively emphasize its adaptability. Experimental results show both the effectiveness of the proposed approach in guiding network learning and the robustness of the hierarchical consensus for remote sensing image classification tasks.
A Spatial-Spectral-Frequency Interactive Network for Multimodal Remote Sensing Classification
Oct 06, 2025Deep learning-based methods have achieved significant success in remote sensing Earth observation data analysis. Numerous feature fusion techniques address multimodal remote sensing image classification by integrating global and local features. However, these techniques often struggle to extract structural and detail features from heterogeneous and redundant multimodal images. With the goal of introducing frequency domain learning to model key and sparse detail features, this paper introduces the spatial-spectral-frequency interaction network (S$^2$Fin), which integrates pairwise fusion modules across the spatial, spectral, and frequency domains. Specifically, we propose a high-frequency sparse enhancement transformer that employs sparse spatial-spectral attention to optimize the parameters of the high-frequency filter. Subsequently, a two-level spatial-frequency fusion strategy is introduced, comprising an adaptive frequency channel module that fuses low-frequency structures with enhanced high-frequency details, and a high-frequency resonance mask that emphasizes sharp edges via phase similarity. In addition, a spatial-spectral attention fusion module further enhances feature extraction at intermediate layers of the network. Experiments on four benchmark multimodal datasets with limited labeled data demonstrate that S$^2$Fin performs superior classification, outperforming state-of-the-art methods. The code is available at https://github.com/HaoLiu-XDU/SSFin.
S2C: Learning Noise-Resistant Differences for Unsupervised Change Detection in Multimodal Remote Sensing Images
Feb 18, 2025
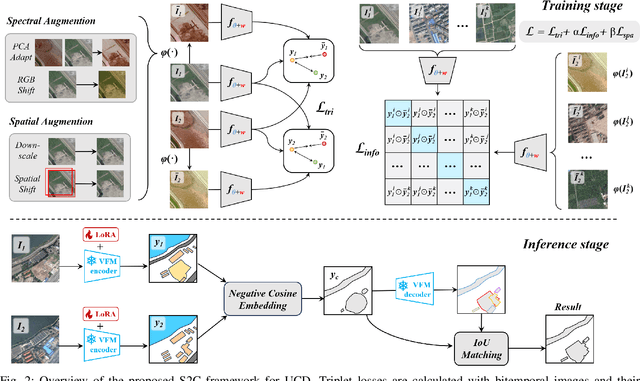
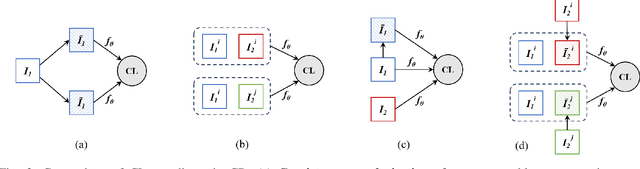

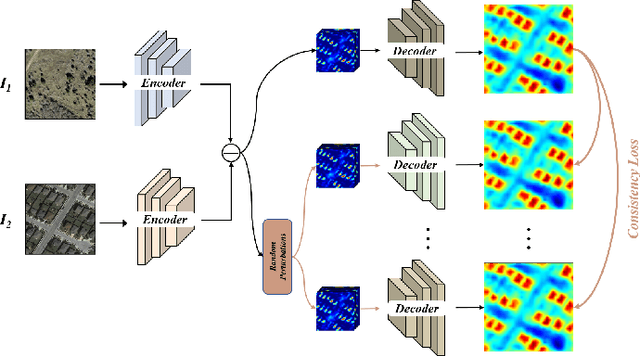
Unsupervised Change Detection (UCD) in multimodal Remote Sensing (RS) images remains a difficult challenge due to the inherent spatio-temporal complexity within data, and the heterogeneity arising from different imaging sensors. Inspired by recent advancements in Visual Foundation Models (VFMs) and Contrastive Learning (CL) methodologies, this research aims to develop CL methodologies to translate implicit knowledge in VFM into change representations, thus eliminating the need for explicit supervision. To this end, we introduce a Semantic-to-Change (S2C) learning framework for UCD in both homogeneous and multimodal RS images. Differently from existing CL methodologies that typically focus on learning multi-temporal similarities, we introduce a novel triplet learning strategy that explicitly models temporal differences, which are crucial to the CD task. Furthermore, random spatial and spectral perturbations are introduced during the training to enhance robustness to temporal noise. In addition, a grid sparsity regularization is defined to suppress insignificant changes, and an IoU-matching algorithm is developed to refine the CD results. Experiments on four benchmark CD datasets demonstrate that the proposed S2C learning framework achieves significant improvements in accuracy, surpassing current state-of-the-art by over 31\%, 9\%, 23\%, and 15\%, respectively. It also demonstrates robustness and sample efficiency, suitable for training and adaptation of various Visual Foundation Models (VFMs) or backbone neural networks. The relevant code will be available at: github.com/DingLei14/S2C.
A Survey of Sample-Efficient Deep Learning for Change Detection in Remote Sensing: Tasks, Strategies, and Challenges
Feb 05, 2025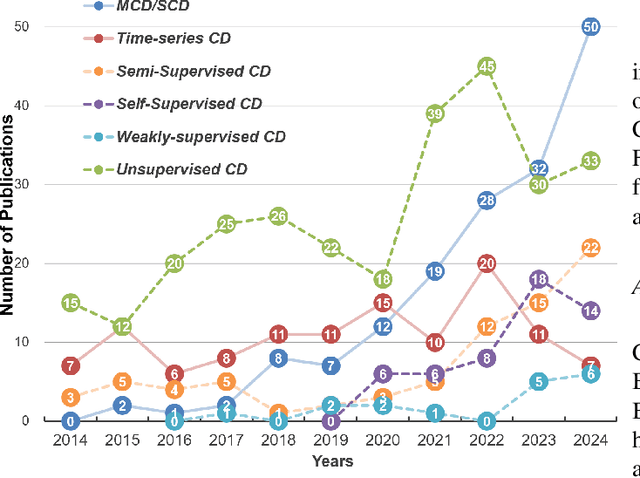
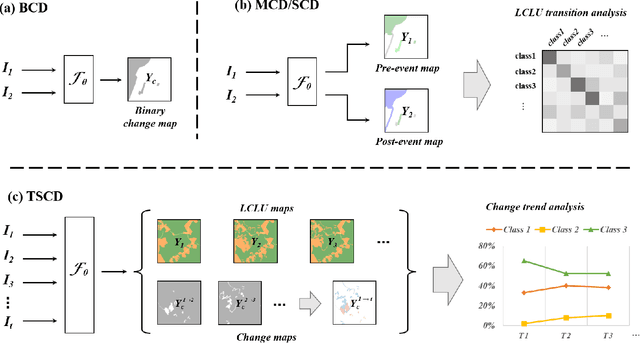
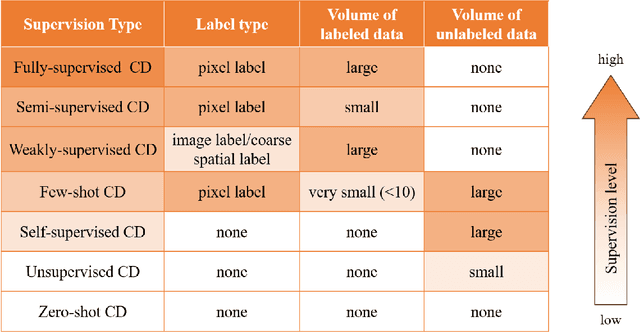
In the last decade, the rapid development of deep learning (DL) has made it possible to perform automatic, accurate, and robust Change Detection (CD) on large volumes of Remote Sensing Images (RSIs). However, despite advances in CD methods, their practical application in real-world contexts remains limited due to the diverse input data and the applicational context. For example, the collected RSIs can be time-series observations, and more informative results are required to indicate the time of change or the specific change category. Moreover, training a Deep Neural Network (DNN) requires a massive amount of training samples, whereas in many cases these samples are difficult to collect. To address these challenges, various specific CD methods have been developed considering different application scenarios and training resources. Additionally, recent advancements in image generation, self-supervision, and visual foundation models (VFMs) have opened up new approaches to address the 'data-hungry' issue of DL-based CD. The development of these methods in broader application scenarios requires further investigation and discussion. Therefore, this article summarizes the literature methods for different CD tasks and the available strategies and techniques to train and deploy DL-based CD methods in sample-limited scenarios. We expect that this survey can provide new insights and inspiration for researchers in this field to develop more effective CD methods that can be applied in a wider range of contexts.
CoMiX: Cross-Modal Fusion with Deformable Convolutions for HSI-X Semantic Segmentation
Nov 13, 2024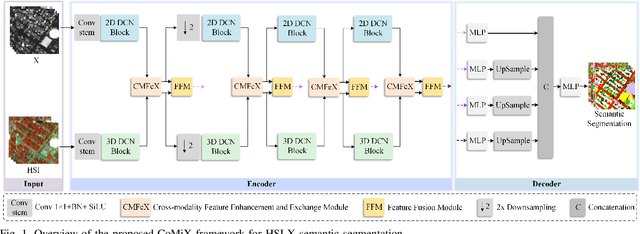
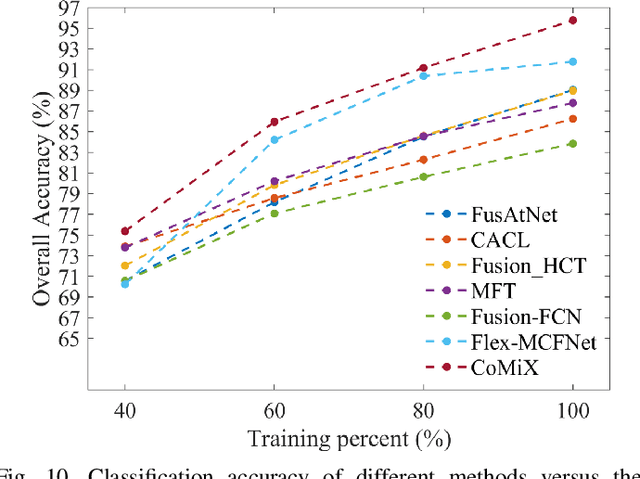
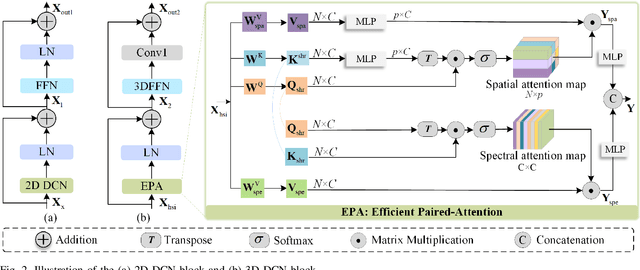
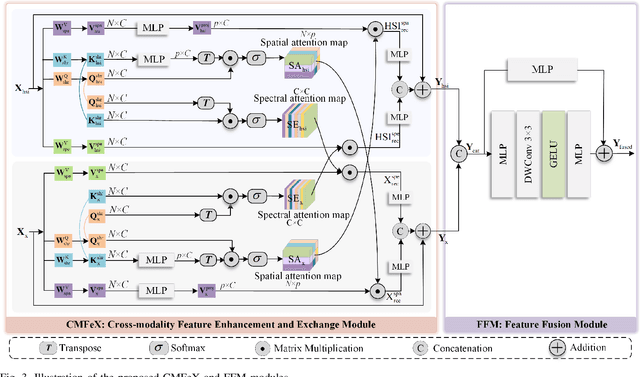
Improving hyperspectral image (HSI) semantic segmentation by exploiting complementary information from a supplementary data type (referred to X-modality) is promising but challenging due to differences in imaging sensors, image content, and resolution. Current techniques struggle to enhance modality-specific and modality-shared information, as well as to capture dynamic interaction and fusion between different modalities. In response, this study proposes CoMiX, an asymmetric encoder-decoder architecture with deformable convolutions (DCNs) for HSI-X semantic segmentation. CoMiX is designed to extract, calibrate, and fuse information from HSI and X data. Its pipeline includes an encoder with two parallel and interacting backbones and a lightweight all-multilayer perceptron (ALL-MLP) decoder. The encoder consists of four stages, each incorporating 2D DCN blocks for the X model to accommodate geometric variations and 3D DCN blocks for HSIs to adaptively aggregate spatial-spectral features. Additionally, each stage includes a Cross-Modality Feature enhancement and eXchange (CMFeX) module and a feature fusion module (FFM). CMFeX is designed to exploit spatial-spectral correlations from different modalities to recalibrate and enhance modality-specific and modality-shared features while adaptively exchanging complementary information between them. Outputs from CMFeX are fed into the FFM for fusion and passed to the next stage for further information learning. Finally, the outputs from each FFM are integrated by the ALL-MLP decoder for final prediction. Extensive experiments demonstrate that our CoMiX achieves superior performance and generalizes well to various multimodal recognition tasks. The CoMiX code will be released.
Local-to-Global Cross-Modal Attention-Aware Fusion for HSI-X Semantic Segmentation
Jun 25, 2024



Hyperspectral image (HSI) classification has recently reached its performance bottleneck. Multimodal data fusion is emerging as a promising approach to overcome this bottleneck by providing rich complementary information from the supplementary modality (X-modality). However, achieving comprehensive cross-modal interaction and fusion that can be generalized across different sensing modalities is challenging due to the disparity in imaging sensors, resolution, and content of different modalities. In this study, we propose a Local-to-Global Cross-modal Attention-aware Fusion (LoGoCAF) framework for HSI-X classification that jointly considers efficiency, accuracy, and generalizability. LoGoCAF adopts a pixel-to-pixel two-branch semantic segmentation architecture to learn information from HSI and X modalities. The pipeline of LoGoCAF consists of a local-to-global encoder and a lightweight multilayer perceptron (MLP) decoder. In the encoder, convolutions are used to encode local and high-resolution fine details in shallow layers, while transformers are used to integrate global and low-resolution coarse features in deeper layers. The MLP decoder aggregates information from the encoder for feature fusion and prediction. In particular, two cross-modality modules, the feature enhancement module (FEM) and the feature interaction and fusion module (FIFM), are introduced in each encoder stage. The FEM is used to enhance complementary information by combining the feature from the other modality across direction-aware, position-sensitive, and channel-wise dimensions. With the enhanced features, the FIFM is designed to promote cross-modality information interaction and fusion for the final semantic prediction. Extensive experiments demonstrate that our LoGoCAF achieves superior performance and generalizes well. The code will be made publicly available.
OBSUM: An object-based spatial unmixing model for spatiotemporal fusion of remote sensing images
Oct 14, 2023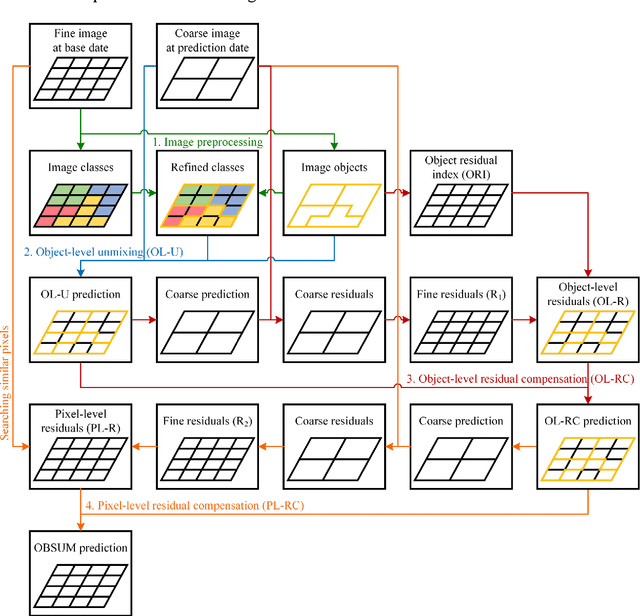
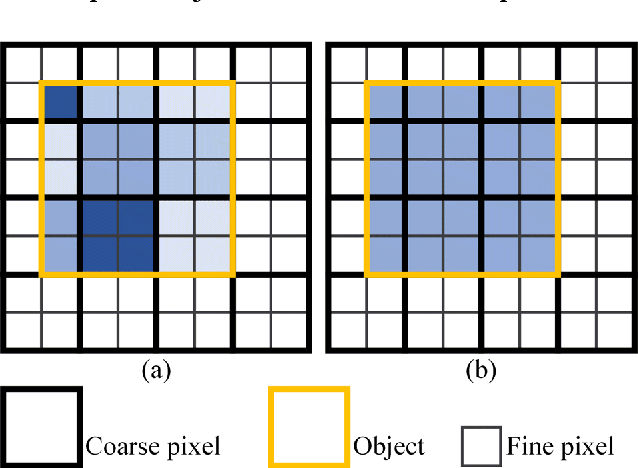
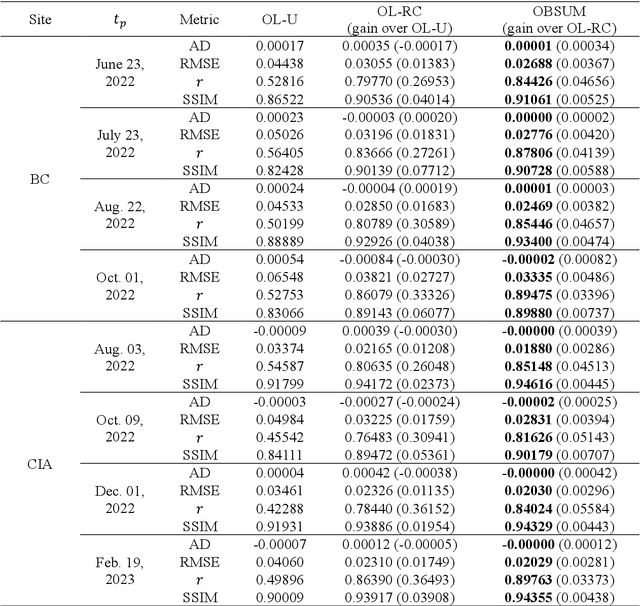
Spatiotemporal fusion aims to improve both the spatial and temporal resolution of remote sensing images, thus facilitating time-series analysis at a fine spatial scale. However, there are several important issues that limit the application of current spatiotemporal fusion methods. First, most spatiotemporal fusion methods are based on pixel-level computation, which neglects the valuable object-level information of the land surface. Moreover, many existing methods cannot accurately retrieve strong temporal changes between the available high-resolution image at base date and the predicted one. This study proposes an Object-Based Spatial Unmixing Model (OBSUM), which incorporates object-based image analysis and spatial unmixing, to overcome the two abovementioned problems. OBSUM consists of one preprocessing step and three fusion steps, i.e., object-level unmixing, object-level residual compensation, and pixel-level residual compensation. OBSUM can be applied using only one fine image at the base date and one coarse image at the prediction date, without the need of a coarse image at the base date. The performance of OBSUM was compared with five representative spatiotemporal fusion methods. The experimental results demonstrated that OBSUM outperformed other methods in terms of both accuracy indices and visual effects over time-series. Furthermore, OBSUM also achieved satisfactory results in two typical remote sensing applications. Therefore, it has great potential to generate accurate and high-resolution time-series observations for supporting various remote sensing applications.