 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncomplete Multimodal Learning for Remote Sensing Data Fusion
Paper and Code
Apr 22, 2023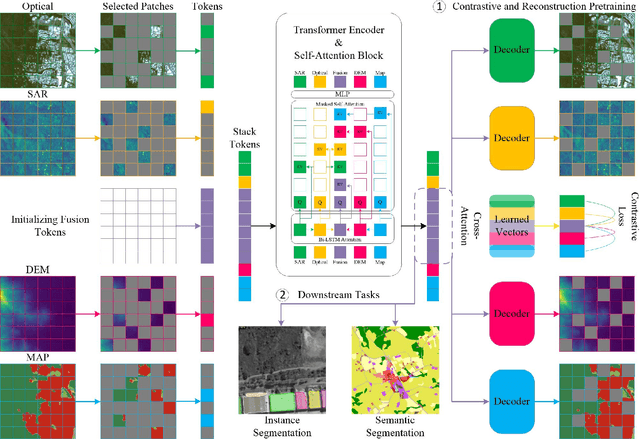



The mechanism of connecting multimodal signals through self-attention operation is a key factor in the success of multimodal Transformer networks in remote sensing data fusion tasks. However, traditional approaches assume access to all modalities during both training and inference, which can lead to severe degradation when dealing with modal-incomplete inputs in downstream applications. To address this limitation, our proposed approach introduces a novel model for incomplete multimodal learning in the context of remote sensing data fusion. This approach can be used in both supervised and self-supervised pretraining paradigms and leverages the additional learned fusion tokens in combination with Bi-LSTM attention and masked self-attention mechanisms to collect multimodal signals. The proposed approach employs reconstruction and contrastive loss to facilitate fusion in pre-training while allowing for random modality combinations as inputs in network training. Our approach delivers state-of-the-art performance on two multimodal datasets for tasks such as building instance / semantic segmentation and land-cover mapping tasks when dealing with incomplete inputs during inference.