 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeeIQ Neutron: Redefining Edge-AI Inference with Integrated NPU and Compiler Innovations
Sep 17, 2025Neural Processing Units (NPUs) are key to enabling efficient AI inference in resource-constrained edge environments. While peak tera operations per second (TOPS) is often used to gauge performance, it poorly reflects real-world performance and typically rather correlates with higher silicon cost. To address this, architects must focus on maximizing compute utilization, without sacrificing flexibility. This paper presents the eIQ Neutron efficient-NPU, integrated into a commercial flagship MPU, alongside co-designed compiler algorithms. The architecture employs a flexible, data-driven design, while the compiler uses a constrained programming approach to optimize compute and data movement based on workload characteristics. Compared to the leading embedded NPU and compiler stack, our solution achieves an average speedup of 1.8x (4x peak) at equal TOPS and memory resources across standard AI-benchmarks. Even against NPUs with double the compute and memory resources, Neutron delivers up to 3.3x higher performance.
Fine-Grained Extraction of Road Networks via Joint Learning of Connectivity and Segmentation
Dec 07, 2023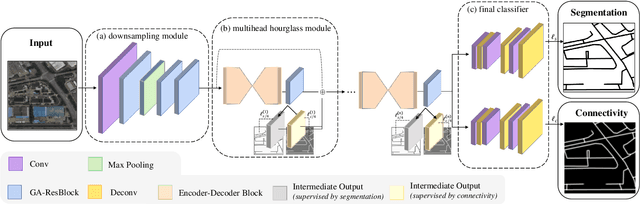

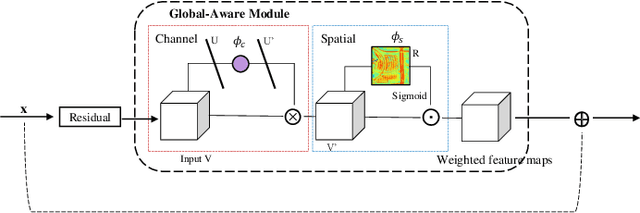
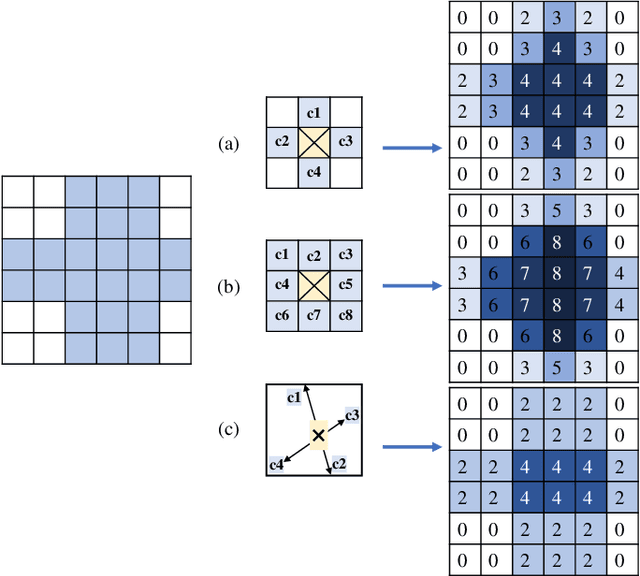
Road network extraction from satellite images is widely applicated in intelligent traffic management and autonomous driving fields. The high-resolution remote sensing images contain complex road areas and distracted background, which make it a challenge for road extraction. In this study, we present a stacked multitask network for end-to-end segmenting roads while preserving connectivity correctness. In the network, a global-aware module is introduced to enhance pixel-level road feature representation and eliminate background distraction from overhead images; a road-direction-related connectivity task is added to ensure that the network preserves the graph-level relationships of the road segments. We also develop a stacked multihead structure to jointly learn and effectively utilize the mutual information between connectivity learning and segmentation learning. We evaluate the performance of the proposed network on three public remote sensing datasets. The experimental results demonstrate that the network outperforms the state-of-the-art methods in terms of road segmentation accuracy and connectivity maintenance.
Looking Outside the Window: Wide-Context Transformer for the Semantic Segmentation of High-Resolution Remote Sensing Images
Jul 14, 2021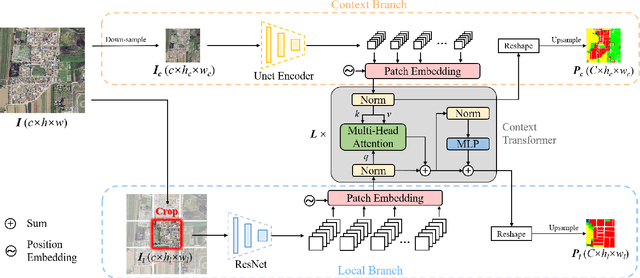
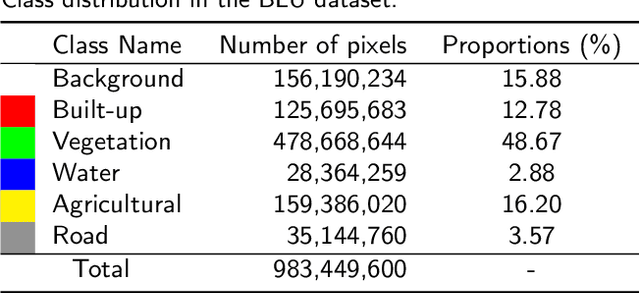
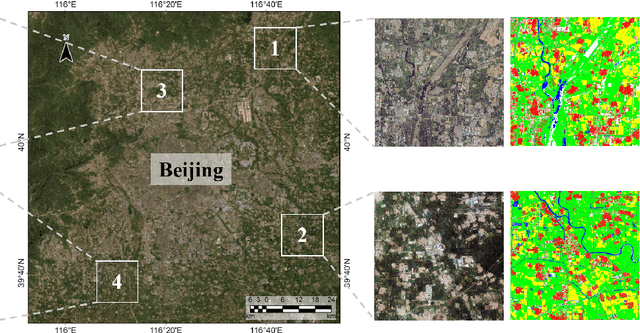
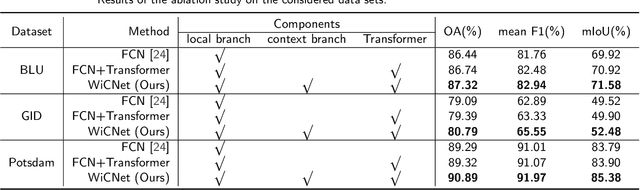
Long-range context information is crucial for the semantic segmentation of High-Resolution (HR) Remote Sensing Images (RSIs). The image cropping operations, commonly used for training neural networks, limit the perception of long-range context information in large RSIs. To break this limitation, we propose a Wide-Context Network (WiCoNet) for the semantic segmentation of HR RSIs. In the WiCoNet, apart from a conventional feature extraction network that aggregates the local information, an extra context branch is designed to explicitly model the spatial information in a larger image area. The information between the two branches is communicated through a Context Transformer, which is a novel design derived from the Vision Transformer to model the long-range context correlations. Ablation studies and comparative experiments conducted on several benchmark datasets prove the effectiveness of the proposed method. In addition, we present a new Beijing Land-Use (BLU) dataset. This is a large-scale HR satellite dataset provided with high-quality and fine-grained reference labels, which can boost future studies in this field.
DML-GANR: Deep Metric Learning With Generative Adversarial Network Regularization for High Spatial Resolution Remote Sensing Image Retrieval
Oct 07, 2020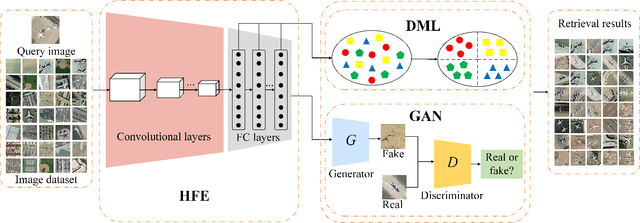


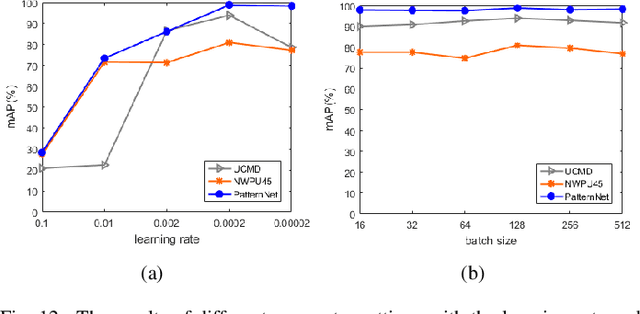
With a small number of labeled samples for training, it can save considerable manpower and material resources, especially when the amount of high spatial resolution remote sensing images (HSR-RSIs) increases considerably. However, many deep models face the problem of overfitting when using a small number of labeled samples. This might degrade HSRRSI retrieval accuracy. Aiming at obtaining more accurate HSR-RSI retrieval performance with small training samples, we develop a deep metric learning approach with generative adversarial network regularization (DML-GANR) for HSR-RSI retrieval. The DML-GANR starts from a high-level feature extraction (HFE) to extract high-level features, which includes convolutional layers and fully connected (FC) layers. Each of the FC layers is constructed by deep metric learning (DML) to maximize the interclass variations and minimize the intraclass variations. The generative adversarial network (GAN) is adopted to mitigate the overfitting problem and validate the qualities of extracted high-level features. DML-GANR is optimized through a customized approach, and the optimal parameters are obtained. The experimental results on the three data sets demonstrate the superior performance of DML-GANR over state-of-the-art techniques in HSR-RSI retrieval.
SLCRF: Subspace Learning with Conditional Random Field for Hyperspectral Image Classification
Oct 07, 2020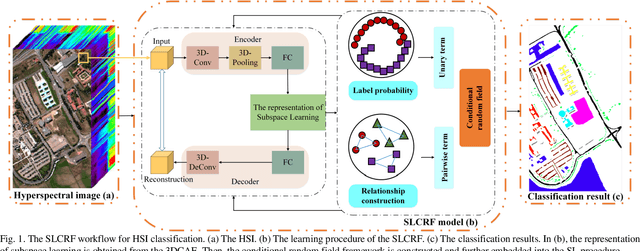

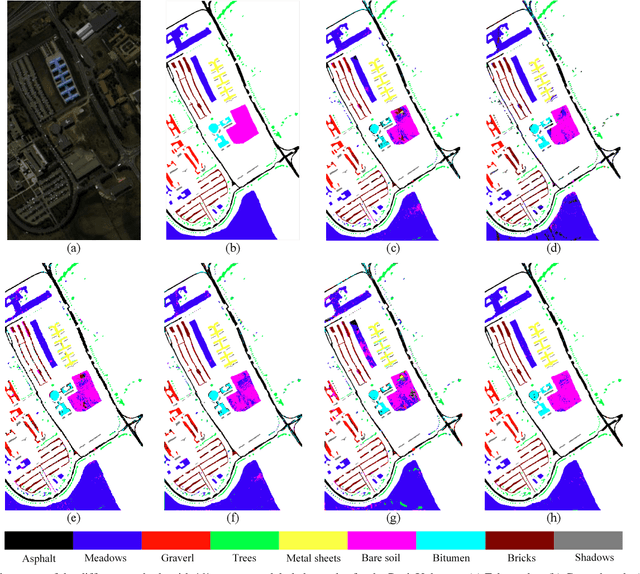
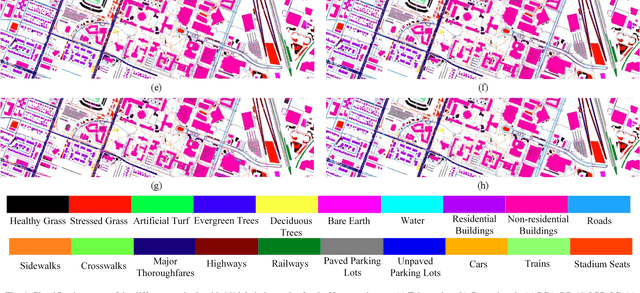
Subspace learning (SL) plays an important role in hyperspectral image (HSI) classification, since it can provide an effective solution to reduce the redundant information in the image pixels of HSIs. Previous works about SL aim to improve the accuracy of HSI recognition. Using a large number of labeled samples, related methods can train the parameters of the proposed solutions to obtain better representations of HSI pixels. However, the data instances may not be sufficient enough to learn a precise model for HSI classification in real applications. Moreover, it is well-known that it takes much time, labor and human expertise to label HSI images. To avoid the aforementioned problems, a novel SL method that includes the probability assumption called subspace learning with conditional random field (SLCRF) is developed. In SLCRF, first, the 3D convolutional autoencoder (3DCAE) is introduced to remove the redundant information in HSI pixels. In addition, the relationships are also constructed using the spectral-spatial information among the adjacent pixels. Then, the conditional random field (CRF) framework can be constructed and further embedded into the HSI SL procedure with the semi-supervised approach. Through the linearized alternating direction method termed LADMAP, the objective function of SLCRF is optimized using a defined iterative algorithm. The proposed method is comprehensively evaluated using the challenging public HSI datasets. We can achieve stateof-the-art performance using these HSI sets.
MLRSNet: A Multi-label High Spatial Resolution Remote Sensing Dataset for Semantic Scene Understanding
Oct 01, 2020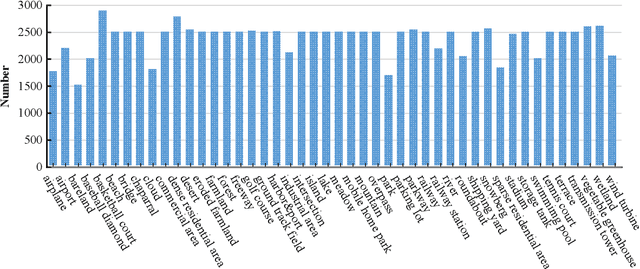
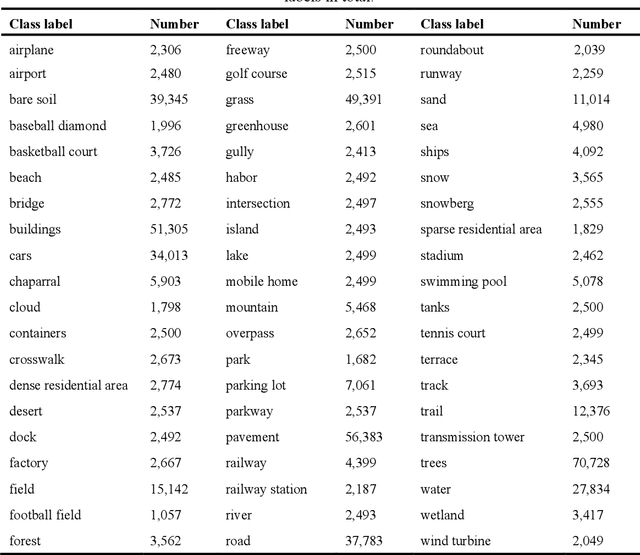

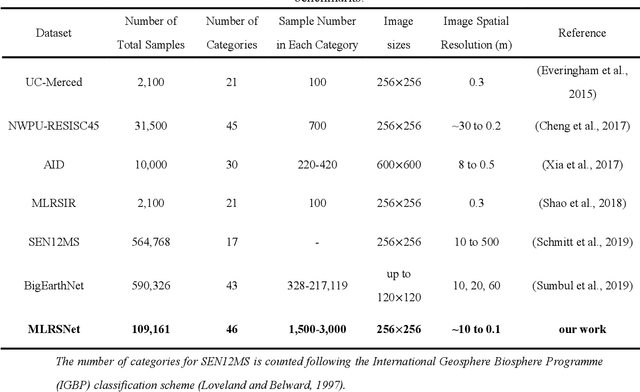
To better understand scene images in the field of remote sensing, multi-label annotation of scene images is necessary. Moreover, to enhance the performance of deep learning models for dealing with semantic scene understanding tasks, it is vital to train them on large-scale annotated data. However, most existing datasets are annotated by a single label, which cannot describe the complex remote sensing images well because scene images might have multiple land cover classes. Few multi-label high spatial resolution remote sensing datasets have been developed to train deep learning models for multi-label based tasks, such as scene classification and image retrieval. To address this issue, in this paper, we construct a multi-label high spatial resolution remote sensing dataset named MLRSNet for semantic scene understanding with deep learning from the overhead perspective. It is composed of high-resolution optical satellite or aerial images. MLRSNet contains a total of 109,161 samples within 46 scene categories, and each image has at least one of 60 predefined labels. We have designed visual recognition tasks, including multi-label based image classification and image retrieval, in which a wide variety of deep learning approaches are evaluated with MLRSNet. The experimental results demonstrate that MLRSNet is a significant benchmark for future research, and it complements the current widely used datasets such as ImageNet, which fills gaps in multi-label image research. Furthermore, we will continue to expand the MLRSNet. MLRSNet and all related materials have been made publicly available at https://data.mendeley.com/datasets/7j9bv9vwsx/2 and https://github.com/cugbrs/MLRSNet.git.
3DCNN-DQN-RNN: A Deep Reinforcement Learning Framework for Semantic Parsing of Large-scale 3D Point Clouds
Jul 21, 2017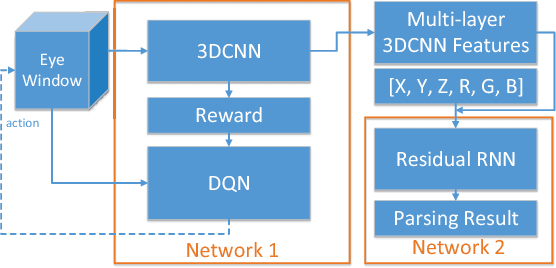
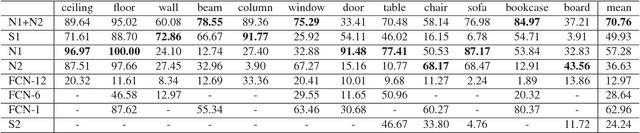
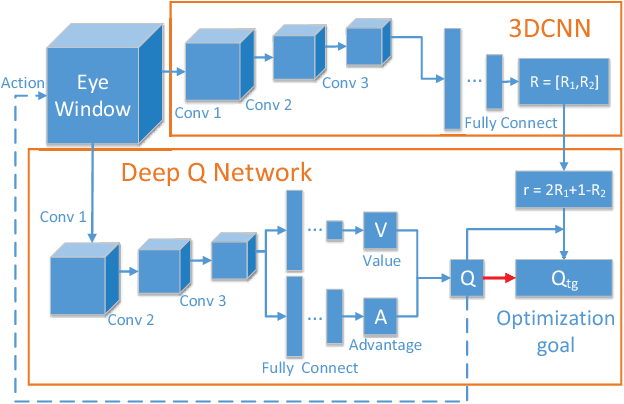

Semantic parsing of large-scale 3D point clouds is an important research topic in computer vision and remote sensing fields. Most existing approaches utilize hand-crafted features for each modality independently and combine them in a heuristic manner. They often fail to consider the consistency and complementary information among features adequately, which makes them difficult to capture high-level semantic structures. The features learned by most of the current deep learning methods can obtain high-quality image classification results. However, these methods are hard to be applied to recognize 3D point clouds due to unorganized distribution and various point density of data. In this paper, we propose a 3DCNN-DQN-RNN method which fuses the 3D convolutional neural network (CNN), Deep Q-Network (DQN) and Residual recurrent neural network (RNN) for an efficient semantic parsing of large-scale 3D point clouds. In our method, an eye window under control of the 3D CNN and DQN can localize and segment the points of the object class efficiently. The 3D CNN and Residual RNN further extract robust and discriminative features of the points in the eye window, and thus greatly enhance the parsing accuracy of large-scale point clouds. Our method provides an automatic process that maps the raw data to the classification results. It also integrates object localization, segmentation and classification into one framework. Experimental results demonstrate that the proposed method outperforms the state-of-the-art point cloud classification methods.