 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAL: Improved Text-Image Matching by Mitigating Visual Semantic Hubs
Nov 22, 2019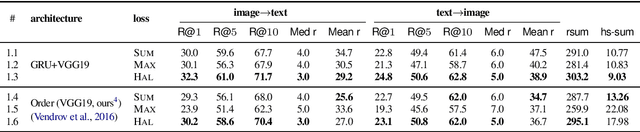
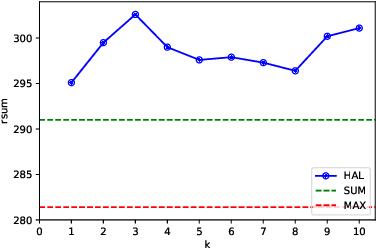
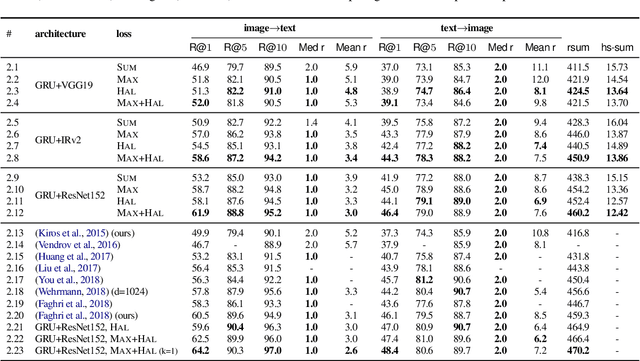
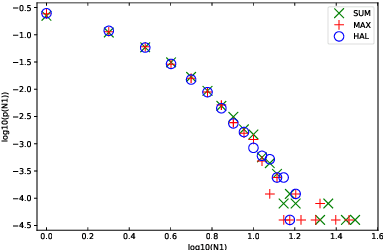
The hubness problem widely exists in high-dimensional embedding space and is a fundamental source of error for cross-modal matching tasks. In this work, we study the emergence of hubs in Visual Semantic Embeddings (VSE) with application to text-image matching. We analyze the pros and cons of two widely adopted optimization objectives for training VSE and propose a novel hubness-aware loss function (HAL) that addresses previous methods' defects. Unlike (Faghri et al.2018) which simply takes the hardest sample within a mini-batch, HAL takes all samples into account, using both local and global statistics to scale up the weights of "hubs". We experiment our method with various configurations of model architectures and datasets. The method exhibits exceptionally good robustness and brings consistent improvement on the task of text-image matching across all settings. Specifically, under the same model architectures as (Faghri et al. 2018) and (Lee at al. 2018), by switching only the learning objective, we report a maximum R@1improvement of 7.4% on MS-COCO and 8.3% on Flickr30k.
A Strong and Robust Baseline for Text-Image Matching
Jun 04, 2019
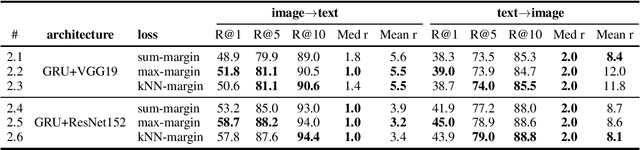
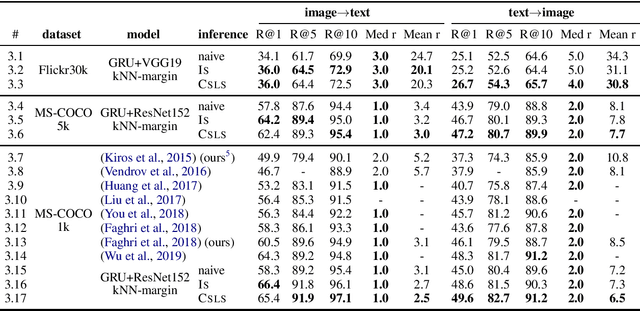
We review the current schemes of text-image matching models and propose improvements for both training and inference. First, we empirically show limitations of two popular loss (sum and max-margin loss) widely used in training text-image embeddings and propose a trade-off: a kNN-margin loss which 1) utilizes information from hard negatives and 2) is robust to noise as all $K$-most hardest samples are taken into account, tolerating \emph{pseudo} negatives and outliers. Second, we advocate the use of Inverted Softmax (\textsc{Is}) and Cross-modal Local Scaling (\textsc{Csls}) during inference to mitigate the so-called hubness problem in high-dimensional embedding space, enhancing scores of all metrics by a large margin.
3D Depthwise Convolution: Reducing Model Parameters in 3D Vision Tasks
Aug 05, 2018



Standard 3D convolution operations require much larger amounts of memory and computation cost than 2D convolution operations. The fact has hindered the development of deep neural nets in many 3D vision tasks. In this paper, we investigate the possibility of applying depthwise separable convolutions in 3D scenario and introduce the use of 3D depthwise convolution. A 3D depthwise convolution splits a single standard 3D convolution into two separate steps, which would drastically reduce the number of parameters in 3D convolutions with more than one order of magnitude. We experiment with 3D depthwise convolution on popular CNN architectures and also compare it with a similar structure called pseudo-3D convolution. The results demonstrate that, with 3D depthwise convolutions, 3D vision tasks like classification and reconstruction can be carried out with more light-weighted neural networks while still delivering comparable performances.
3DCNN-DQN-RNN: A Deep Reinforcement Learning Framework for Semantic Parsing of Large-scale 3D Point Clouds
Jul 21, 2017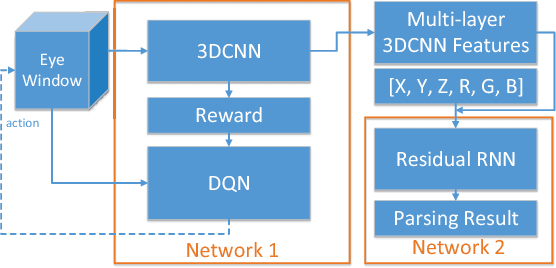
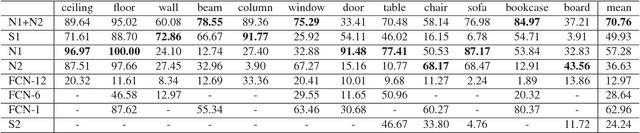
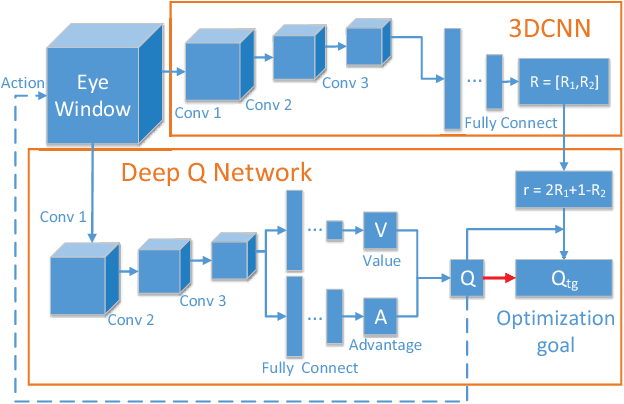

Semantic parsing of large-scale 3D point clouds is an important research topic in computer vision and remote sensing fields. Most existing approaches utilize hand-crafted features for each modality independently and combine them in a heuristic manner. They often fail to consider the consistency and complementary information among features adequately, which makes them difficult to capture high-level semantic structures. The features learned by most of the current deep learning methods can obtain high-quality image classification results. However, these methods are hard to be applied to recognize 3D point clouds due to unorganized distribution and various point density of data. In this paper, we propose a 3DCNN-DQN-RNN method which fuses the 3D convolutional neural network (CNN), Deep Q-Network (DQN) and Residual recurrent neural network (RNN) for an efficient semantic parsing of large-scale 3D point clouds. In our method, an eye window under control of the 3D CNN and DQN can localize and segment the points of the object class efficiently. The 3D CNN and Residual RNN further extract robust and discriminative features of the points in the eye window, and thus greatly enhance the parsing accuracy of large-scale point clouds. Our method provides an automatic process that maps the raw data to the classification results. It also integrates object localization, segmentation and classification into one framework. Experimental results demonstrate that the proposed method outperforms the state-of-the-art point cloud classification methods.