Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Strong and Robust Baseline for Text-Image Matching
Paper and Code
Jun 04, 2019
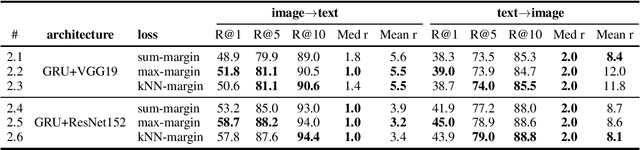
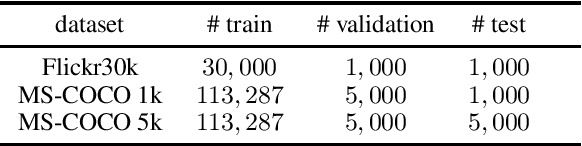
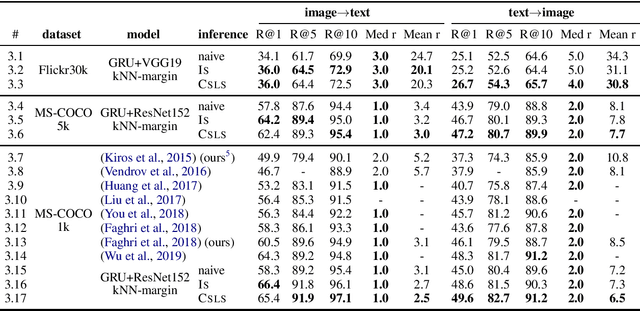
We review the current schemes of text-image matching models and propose improvements for both training and inference. First, we empirically show limitations of two popular loss (sum and max-margin loss) widely used in training text-image embeddings and propose a trade-off: a kNN-margin loss which 1) utilizes information from hard negatives and 2) is robust to noise as all $K$-most hardest samples are taken into account, tolerating \emph{pseudo} negatives and outliers. Second, we advocate the use of Inverted Softmax (\textsc{Is}) and Cross-modal Local Scaling (\textsc{Csls}) during inference to mitigate the so-called hubness problem in high-dimensional embedding space, enhancing scores of all metrics by a large margin.
* 6 pages (excluding references); 2019 ACL Student Research Workshop
(to appear)
View paper on