 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAL: Improved Text-Image Matching by Mitigating Visual Semantic Hubs
Paper and Code
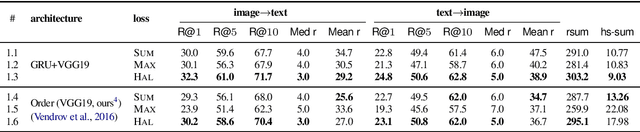
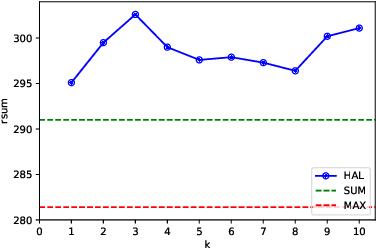
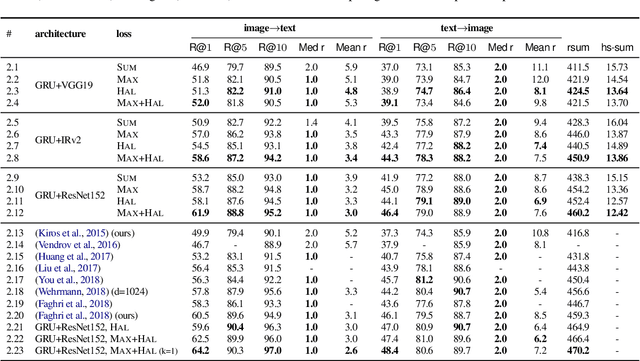
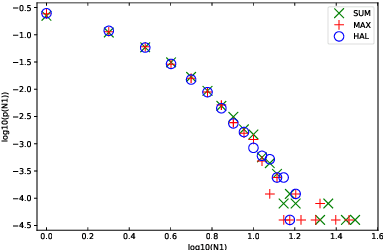
The hubness problem widely exists in high-dimensional embedding space and is a fundamental source of error for cross-modal matching tasks. In this work, we study the emergence of hubs in Visual Semantic Embeddings (VSE) with application to text-image matching. We analyze the pros and cons of two widely adopted optimization objectives for training VSE and propose a novel hubness-aware loss function (HAL) that addresses previous methods' defects. Unlike (Faghri et al.2018) which simply takes the hardest sample within a mini-batch, HAL takes all samples into account, using both local and global statistics to scale up the weights of "hubs". We experiment our method with various configurations of model architectures and datasets. The method exhibits exceptionally good robustness and brings consistent improvement on the task of text-image matching across all settings. Specifically, under the same model architectures as (Faghri et al. 2018) and (Lee at al. 2018), by switching only the learning objective, we report a maximum R@1improvement of 7.4% on MS-COCO and 8.3% on Flickr30k.