 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeeIQ Neutron: Redefining Edge-AI Inference with Integrated NPU and Compiler Innovations
Sep 17, 2025Neural Processing Units (NPUs) are key to enabling efficient AI inference in resource-constrained edge environments. While peak tera operations per second (TOPS) is often used to gauge performance, it poorly reflects real-world performance and typically rather correlates with higher silicon cost. To address this, architects must focus on maximizing compute utilization, without sacrificing flexibility. This paper presents the eIQ Neutron efficient-NPU, integrated into a commercial flagship MPU, alongside co-designed compiler algorithms. The architecture employs a flexible, data-driven design, while the compiler uses a constrained programming approach to optimize compute and data movement based on workload characteristics. Compared to the leading embedded NPU and compiler stack, our solution achieves an average speedup of 1.8x (4x peak) at equal TOPS and memory resources across standard AI-benchmarks. Even against NPUs with double the compute and memory resources, Neutron delivers up to 3.3x higher performance.
Exploiting Neural-Network Statistics for Low-Power DNN Inference
Nov 09, 2023



Specialized compute blocks have been developed for efficient DNN execution. However, due to the vast amount of data and parameter movements, the interconnects and on-chip memories form another bottleneck, impairing power and performance. This work addresses this bottleneck by contributing a low-power technique for edge-AI inference engines that combines overhead-free coding with a statistical analysis of the data and parameters of neural networks. Our approach reduces the interconnect and memory power consumption by up to 80% for state-of-the-art benchmarks while providing additional power savings for the compute blocks by up to 39%. These power improvements are achieved with no loss of accuracy and negligible hardware cost.
Synapse Compression for Event-Based Convolutional-Neural-Network Accelerators
Dec 25, 2021

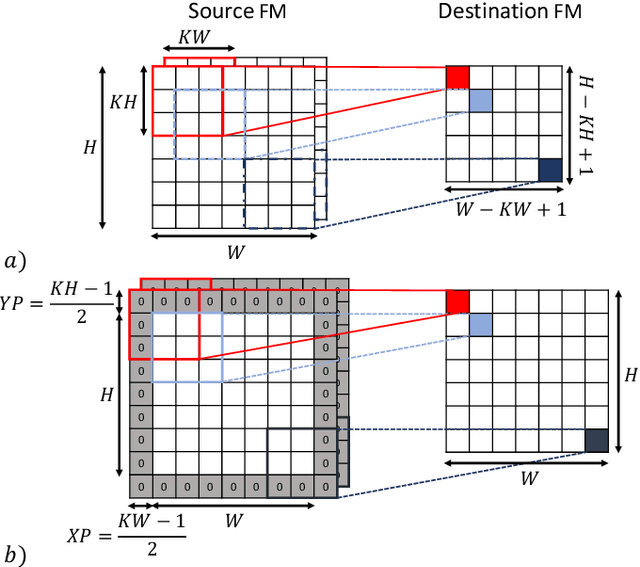
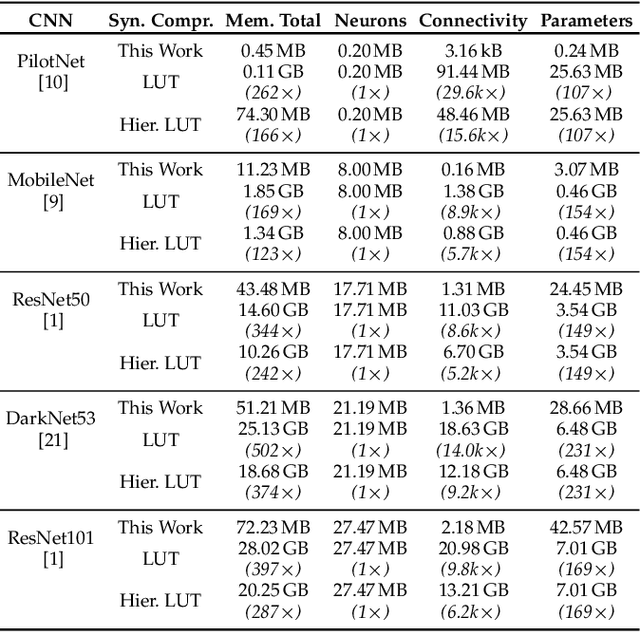
Manufacturing-viable neuromorphic chips require novel computer architectures to achieve the massively parallel and efficient information processing the brain supports so effortlessly. Emerging event-based architectures are making this dream a reality. However, the large memory requirements for synaptic connectivity are a showstopper for the execution of modern convolutional neural networks (CNNs) on massively parallel, event-based (spiking) architectures. This work overcomes this roadblock by contributing a lightweight hardware scheme to compress the synaptic memory requirements by several thousand times, enabling the execution of complex CNNs on a single chip of small form factor. A silicon implementation in a 12-nm technology shows that the technique increases the system's implementation cost by only 2%, despite achieving a total memory-footprint reduction of up to 374x compared to the best previously published technique.