 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynapse Compression for Event-Based Convolutional-Neural-Network Accelerators
Dec 25, 2021

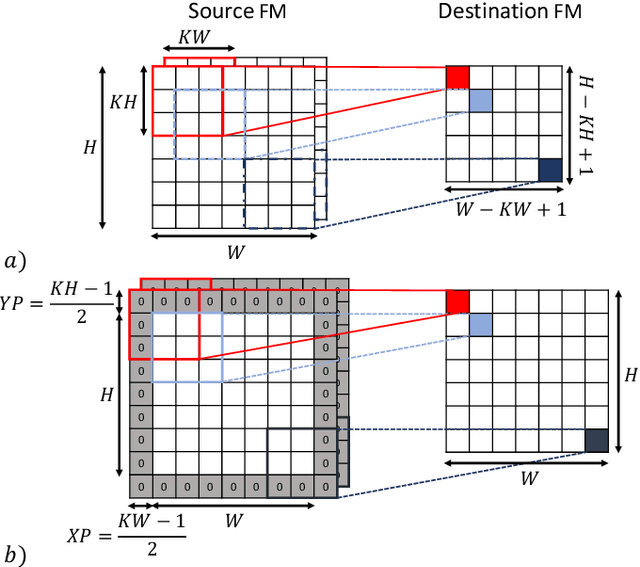
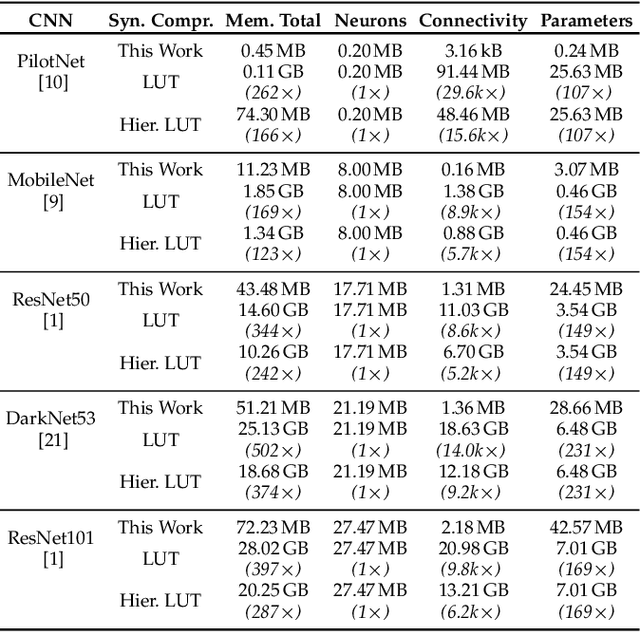
Manufacturing-viable neuromorphic chips require novel computer architectures to achieve the massively parallel and efficient information processing the brain supports so effortlessly. Emerging event-based architectures are making this dream a reality. However, the large memory requirements for synaptic connectivity are a showstopper for the execution of modern convolutional neural networks (CNNs) on massively parallel, event-based (spiking) architectures. This work overcomes this roadblock by contributing a lightweight hardware scheme to compress the synaptic memory requirements by several thousand times, enabling the execution of complex CNNs on a single chip of small form factor. A silicon implementation in a 12-nm technology shows that the technique increases the system's implementation cost by only 2%, despite achieving a total memory-footprint reduction of up to 374x compared to the best previously published technique.
Evolutionary Acyclic Graph Partitioning
Sep 25, 2017



Directed graphs are widely used to model data flow and execution dependencies in streaming applications. This enables the utilization of graph partitioning algorithms for the problem of parallelizing computation for multiprocessor architectures. However due to resource restrictions, an acyclicity constraint on the partition is necessary when mapping streaming applications to an embedded multiprocessor. Here, we contribute a multi-level algorithm for the acyclic graph partitioning problem. Based on this, we engineer an evolutionary algorithm to further reduce communication cost, as well as to improve load balancing and the scheduling makespan on embedded multiprocessor architectures.
Graph Partitioning with Acyclicity Constraints
Apr 03, 2017



Graphs are widely used to model execution dependencies in applications. In particular, the NP-complete problem of partitioning a graph under constraints receives enormous attention by researchers because of its applicability in multiprocessor scheduling. We identified the additional constraint of acyclic dependencies between blocks when mapping computer vision and imaging applications to a heterogeneous embedded multiprocessor. Existing algorithms and heuristics do not address this requirement and deliver results that are not applicable for our use-case. In this work, we show that this more constrained version of the graph partitioning problem is NP-complete and present heuristics that achieve a close approximation of the optimal solution found by an exhaustive search for small problem instances and much better scalability for larger instances. In addition, we can show a positive impact on the schedule of a real imaging application that improves communication volume and execution time.