 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreqTrack: Frequency Learning based Vision Transformer for RGB-Event Object Tracking
Apr 16, 2026Existing single-modal RGB trackers often face performance bottlenecks in complex dynamic scenes, while the introduction of event sensors offers new potential for enhancing tracking capabilities. However, most current RGB-event fusion methods, primarily designed in the spatial domain using convolutional, Transformer, or Mamba architectures, fail to fully exploit the unique temporal response and high-frequency characteristics of event data. To address this, we1 propose FreqTrack, a frequency-aware RGBE tracking framework that establishes complementary inter-modal correlations through frequency-domain transformations for more robust feature fusion. We design a Spectral Enhancement Transformer (SET) layer that incorporates multi-head dynamic Fourier filtering to adaptively enhance and select frequency-domain features. Additionally, we develop a Wavelet Edge Refinement (WER) module, which leverages learnable wavelet transforms to explicitly extract multi-scale edge structures from event data, effectively improving modeling capability in high-speed and low-light scenarios. Extensive experiments on the COESOT and FE108 datasets demonstrate that FreqTrack achieves highly competitive performance, particularly attaining leading precision of 76.6\% on the COESOT benchmark, validating the effectiveness of frequency-domain modeling for RGBE tracking.
Event-Adaptive State Transition and Gated Fusion for RGB-Event Object Tracking
Apr 15, 2026Existing Vision Mamba-based RGB-Event(RGBE) tracking methods suffer from using static state transition matrices, which fail to adapt to variations in event sparsity. This rigidity leads to imbalanced modeling-underfitting sparse event streams and overfitting dense ones-thus degrading cross-modal fusion robustness. To address these limitations, we propose MambaTrack, a multimodal and efficient tracking framework built upon a Dynamic State Space Model(DSSM). Our contributions are twofold. First, we introduce an event-adaptive state transition mechanism that dynamically modulates the state transition matrix based on event stream density. A learnable scalar governs the state evolution rate, enabling differentiated modeling of sparse and dense event flows. Second, we develop a Gated Projection Fusion(GPF) module for robust cross-modal integration. This module projects RGB features into the event feature space and generates adaptive gates from event density and RGB confidence scores. These gates precisely control the fusion intensity, suppressing noise while preserving complementary information. Experiments show that MambaTrack achieves state-of-the-art performance on the FE108 and FELT datasets. Its lightweight design suggests potential for real-time embedded deployment.
Consistent and Efficient MSCKF-based LiDAR-Inertial Odometry with Inferred Cluster-to-Plane Constraints for UAVs
Mar 13, 2026Robust and accurate navigation is critical for Unmanned Aerial Vehicles (UAVs) especially for those with stringent Size, Weight, and Power (SWaP) constraints. However, most state-of-the-art (SOTA) LiDAR-Inertial Odometry (LIO) systems still suffer from estimation inconsistency and computational bottlenecks when deployed on such platforms. To address these issues, this paper proposes a consistent and efficient tightly-coupled LIO framework tailored for UAVs. Within the efficient Multi-State Constraint Kalman Filter (MSCKF) framework, we build coplanar constraints inferred from planar features observed across a sliding window. By applying null-space projection to sliding-window coplanar constraints, we eliminate the direct dependency on feature parameters in the state vector, thereby mitigating overconfidence and improving consistency. More importantly, to further boost the efficiency, we introduce a parallel voxel-based data association and a novel compact cluster-to-plane measurement model. This compact measurement model losslessly reduces observation dimensionality and significantly accelerating the update process. Extensive evaluations demonstrate that our method outperforms most state-of-the-art (SOTA) approaches by providing a superior balance of consistency and efficiency. It exhibits improved robustness in degenerate scenarios, achieves the lowest memory usage via its map-free nature, and runs in real-time on resource-constrained embedded platforms (e.g., NVIDIA Jetson TX2).
Layer-adaptive Expert Pruning for Pre-Training of Mixture-of-Experts Large Language Models
Jan 20, 2026Although Mixture-of-Experts (MoE) Large Language Models (LLMs) deliver superior accuracy with a reduced number of active parameters, their pre-training represents a significant computationally bottleneck due to underutilized experts and limited training efficiency. This work introduces a Layer-Adaptive Expert Pruning (LAEP) algorithm designed for the pre-training stage of MoE LLMs. In contrast to previous expert pruning approaches that operate primarily in the post-training phase, the proposed algorithm enhances training efficiency by selectively pruning underutilized experts and reorganizing experts across computing devices according to token distribution statistics. Comprehensive experiments demonstrate that LAEP effectively reduces model size and substantially improves pre-training efficiency. In particular, when pre-training the 1010B Base model from scratch, LAEP achieves a 48.3\% improvement in training efficiency alongside a 33.3% parameter reduction, while still delivering excellent performance across multiple domains.
Yuan3.0 Flash: An Open Multimodal Large Language Model for Enterprise Applications
Jan 05, 2026We introduce Yuan3.0 Flash, an open-source Mixture-of-Experts (MoE) MultiModal Large Language Model featuring 3.7B activated parameters and 40B total parameters, specifically designed to enhance performance on enterprise-oriented tasks while maintaining competitive capabilities on general-purpose tasks. To address the overthinking phenomenon commonly observed in Large Reasoning Models (LRMs), we propose Reflection-aware Adaptive Policy Optimization (RAPO), a novel RL training algorithm that effectively regulates overthinking behaviors. In enterprise-oriented tasks such as retrieval-augmented generation (RAG), complex table understanding, and summarization, Yuan3.0 Flash consistently achieves superior performance. Moreover, it also demonstrates strong reasoning capabilities in domains such as mathematics, science, etc., attaining accuracy comparable to frontier model while requiring only approximately 1/4 to 1/2 of the average tokens. Yuan3.0 Flash has been fully open-sourced to facilitate further research and real-world deployment: https://github.com/Yuan-lab-LLM/Yuan3.0.
Yuan-TecSwin: A text conditioned Diffusion model with Swin-transformer blocks
Dec 18, 2025Diffusion models have shown remarkable capacity in image synthesis based on their U-shaped architecture and convolutional neural networks (CNN) as basic blocks. The locality of the convolution operation in CNN may limit the model's ability to understand long-range semantic information. To address this issue, we propose Yuan-TecSwin, a text-conditioned diffusion model with Swin-transformer in this work. The Swin-transformer blocks take the place of CNN blocks in the encoder and decoder, to improve the non-local modeling ability in feature extraction and image restoration. The text-image alignment is improved with a well-chosen text encoder, effective utilization of text embedding, and careful design in the incorporation of text condition. Using an adapted time step to search in different diffusion stages, inference performance is further improved by 10%. Yuan-TecSwin achieves the state-of-the-art FID score of 1.37 on ImageNet generation benchmark, without any additional models at different denoising stages. In a side-by-side comparison, we find it difficult for human interviewees to tell the model-generated images from the human-painted ones.
Robust 4D Radar-aided Inertial Navigation for Aerial Vehicles
Feb 21, 2025



While LiDAR and cameras are becoming ubiquitous for unmanned aerial vehicles (UAVs) but can be ineffective in challenging environments, 4D millimeter-wave (MMW) radars that can provide robust 3D ranging and Doppler velocity measurements are less exploited for aerial navigation. In this paper, we develop an efficient and robust error-state Kalman filter (ESKF)-based radar-inertial navigation for UAVs. The key idea of the proposed approach is the point-to-distribution radar scan matching to provide motion constraints with proper uncertainty qualification, which are used to update the navigation states in a tightly coupled manner, along with the Doppler velocity measurements. Moreover, we propose a robust keyframe-based matching scheme against the prior map (if available) to bound the accumulated navigation errors and thus provide a radar-based global localization solution with high accuracy. Extensive real-world experimental validations have demonstrated that the proposed radar-aided inertial navigation outperforms state-of-the-art methods in both accuracy and robustness.
SQLfuse: Enhancing Text-to-SQL Performance through Comprehensive LLM Synergy
Jul 19, 2024



Text-to-SQL conversion is a critical innovation, simplifying the transition from complex SQL to intuitive natural language queries, especially significant given SQL's prevalence in the job market across various roles. The rise of Large Language Models (LLMs) like GPT-3.5 and GPT-4 has greatly advanced this field, offering improved natural language understanding and the ability to generate nuanced SQL statements. However, the potential of open-source LLMs in Text-to-SQL applications remains underexplored, with many frameworks failing to leverage their full capabilities, particularly in handling complex database queries and incorporating feedback for iterative refinement. Addressing these limitations, this paper introduces SQLfuse, a robust system integrating open-source LLMs with a suite of tools to enhance Text-to-SQL translation's accuracy and usability. SQLfuse features four modules: schema mining, schema linking, SQL generation, and a SQL critic module, to not only generate but also continuously enhance SQL query quality. Demonstrated by its leading performance on the Spider Leaderboard and deployment by Ant Group, SQLfuse showcases the practical merits of open-source LLMs in diverse business contexts.
Yuan 2.0-M32: Mixture of Experts with Attention Router
May 29, 2024



Yuan 2.0-M32, with a similar base architecture as Yuan-2.0 2B, uses a mixture-of-experts architecture with 32 experts of which 2 experts are active. A new router network, Attention Router, is proposed and adopted for a more efficient selection of experts, which improves the accuracy compared to the model with classical router network. Yuan 2.0-M32 is trained with 2000B tokens from scratch, and the training computation consumption is only 9.25% of a dense model at the same parameter scale. Yuan 2.0-M32 demonstrates competitive capability on coding, math, and various domains of expertise, with only 3.7B active parameters of 40B in total, and 7.4 GFlops forward computation per token, both of which are only 1/19 of Llama3-70B. Yuan 2.0-M32 surpass Llama3-70B on MATH and ARC-Challenge benchmark, with accuracy of 55.89 and 95.8 respectively. The models and source codes of Yuan 2.0-M32 are released at Github1.
YUAN 2.0: A Large Language Model with Localized Filtering-based Attention
Dec 04, 2023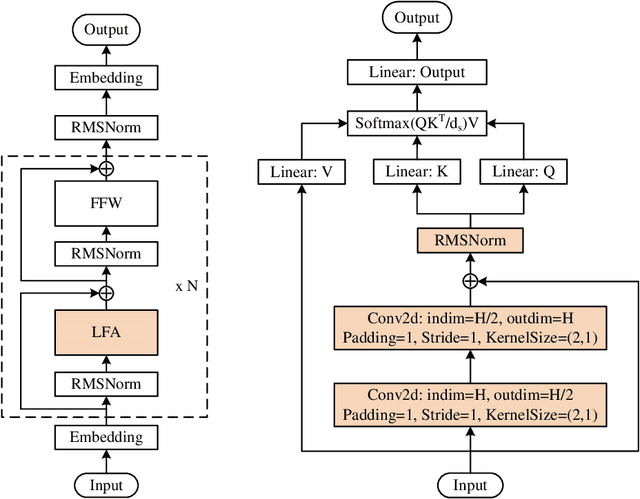

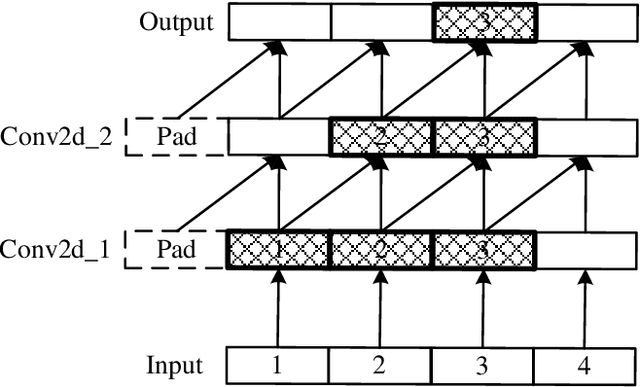
In this work, we develop and release Yuan 2.0, a series of large language models with parameters ranging from 2.1 billion to 102.6 billion. The Localized Filtering-based Attention (LFA) is introduced to incorporate prior knowledge of local dependencies of natural language into Attention. A data filtering and generating system is presented to build pre-training and fine-tuning dataset in high quality. A distributed training method with non-uniform pipeline parallel, data parallel, and optimizer parallel is proposed, which greatly reduces the bandwidth requirements of intra-node communication, and achieves good performance in large-scale distributed training. Yuan 2.0 models display impressive ability in code generation, math problem-solving, and chatting compared with existing models. The latest version of YUAN 2.0, including model weights and source code, is accessible at Github.