 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoEGF-Mol: Evolving Exponential Geodesic Flow for Structure-based Drug Design
Jan 30, 2026Structure-Based Drug Design (SBDD) aims to discover bioactive ligands. Conventional approaches construct probability paths separately in Euclidean and probabilistic spaces for continuous atomic coordinates and discrete chemical categories, leading to a mismatch with the underlying statistical manifolds. We address this issue from an information-geometric perspective by modeling molecules as composite exponential-family distributions and defining generative flows along exponential geodesics under the Fisher-Rao metric. To avoid the instantaneous trajectory collapse induced by geodesics directly targeting Dirac distributions, we propose Evolving Exponential Geodesic Flow for SBDD (EvoEGF-Mol), which replaces static Dirac targets with dynamically concentrating distributions, ensuring stable training via a progressive-parameter-refinement architecture. Our model approaches a reference-level PoseBusters passing rate (93.4%) on CrossDock, demonstrating remarkable geometric precision and interaction fidelity, while outperforming baselines on real-world MolGenBench tasks by recovering bioactive scaffolds and generating candidates that meet established MedChem filters.
P2DFlow: A Protein Ensemble Generative Model with SE(3) Flow Matching
Nov 26, 2024Biological processes, functions, and properties are intricately linked to the ensemble of protein conformations, rather than being solely determined by a single stable conformation. In this study, we have developed P2DFlow, a generative model based on SE(3) flow matching, to predict the structural ensembles of proteins. We specifically designed a valuable prior for the flow process and enhanced the model's ability to distinguish each intermediate state by incorporating an additional dimension to describe the ensemble data, which can reflect the physical laws governing the distribution of ensembles, so that the prior knowledge can effectively guide the generation process. When trained and evaluated on the MD datasets of ATLAS, P2DFlow outperforms other baseline models on extensive experiments, successfully capturing the observable dynamic fluctuations as evidenced in crystal structure and MD simulations. As a potential proxy agent for protein molecular simulation, the high-quality ensembles generated by P2DFlow could significantly aid in understanding protein functions across various scenarios. Code is available at https://github.com/BLEACH366/P2DFlow.
Improving Global Forest Mapping by Semi-automatic Sample Labeling with Deep Learning on Google Earth Images
Aug 06, 2021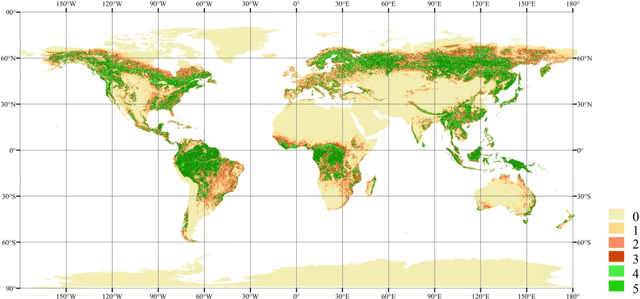
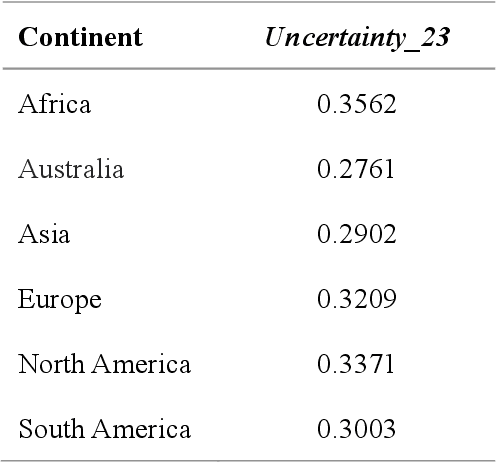
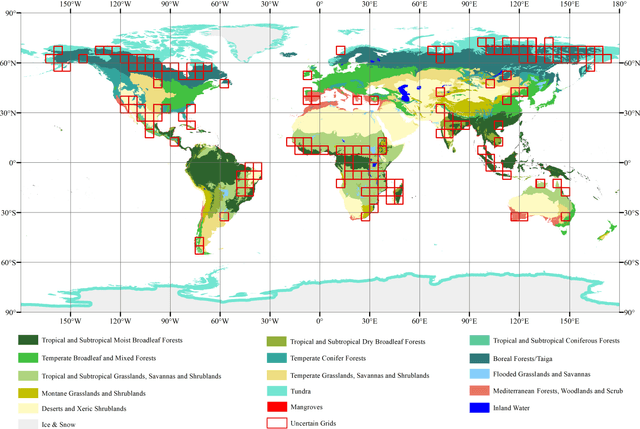
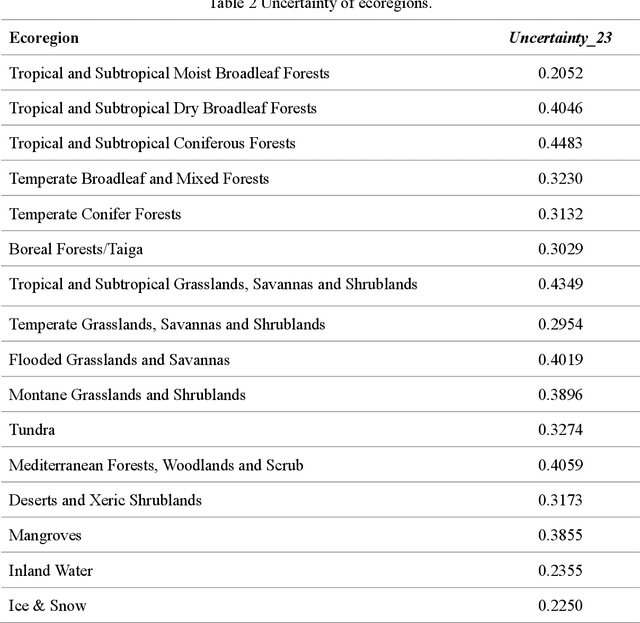
Global forest cover is critical to the provision of certain ecosystem services. With the advent of the google earth engine cloud platform, fine resolution global land cover mapping task could be accomplished in a matter of days instead of years. The amount of global forest cover (GFC) products has been steadily increasing in the last decades. However, it's hard for users to select suitable one due to great differences between these products, and the accuracy of these GFC products has not been verified on global scale. To provide guidelines for users and producers, it is urgent to produce a validation sample set at the global level. However, this labeling task is time and labor consuming, which has been the main obstacle to the progress of global land cover mapping. In this research, a labor-efficient semi-automatic framework is introduced to build a biggest ever Forest Sample Set (FSS) contained 395280 scattered samples categorized as forest, shrubland, grassland, impervious surface, etc. On the other hand, to provide guidelines for the users, we comprehensively validated the local and global mapping accuracy of all existing 30m GFC products, and analyzed and mapped the agreement of them. Moreover, to provide guidelines for the producers, optimal sampling strategy was proposed to improve the global forest classification. Furthermore, a new global forest cover named GlobeForest2020 has been generated, which proved to improve the previous highest state-of-the-art accuracies (obtained by Gong et al., 2017) by 2.77% in uncertain grids and by 1.11% in certain grids.
Super-resolution-based Change Detection Network with Stacked Attention Module for Images with Different Resolutions
Feb 27, 2021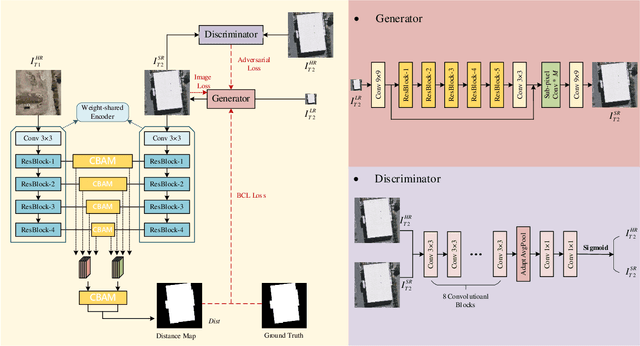

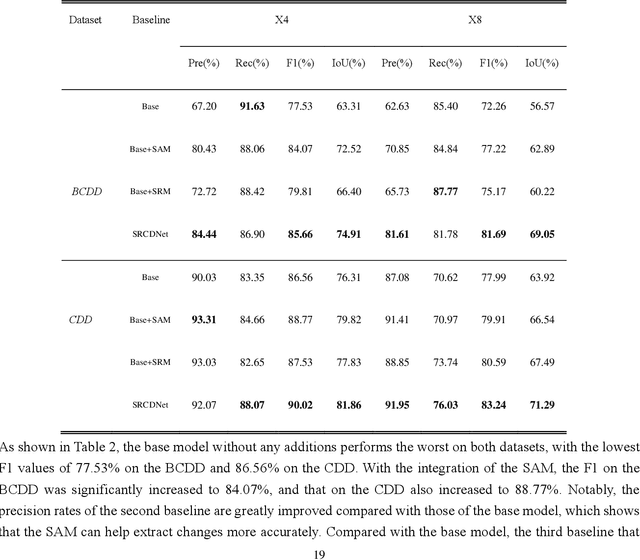

Change detection, which aims to distinguish surface changes based on bi-temporal images, plays a vital role in ecological protection and urban planning. Since high resolution (HR) images cannot be typically acquired continuously over time, bi-temporal images with different resolutions are often adopted for change detection in practical applications. Traditional subpixel-based methods for change detection using images with different resolutions may lead to substantial error accumulation when HR images are employed; this is because of intraclass heterogeneity and interclass similarity. Therefore, it is necessary to develop a novel method for change detection using images with different resolutions, that is more suitable for HR images. To this end, we propose a super-resolution-based change detection network (SRCDNet) with a stacked attention module. The SRCDNet employs a super resolution (SR) module containing a generator and a discriminator to directly learn SR images through adversarial learning and overcome the resolution difference between bi-temporal images. To enhance the useful information in multi-scale features, a stacked attention module consisting of five convolutional block attention modules (CBAMs) is integrated to the feature extractor. The final change map is obtained through a metric learning-based change decision module, wherein a distance map between bi-temporal features is calculated. The experimental results demonstrate the superiority of the proposed method, which not only outperforms all baselines -with the highest F1 scores of 87.40% on the building change detection dataset and 92.94% on the change detection dataset -but also obtains the best accuracies on experiments performed with images having a 4x and 8x resolution difference. The source code of SRCDNet will be available at https://github.com/liumency/SRCDNet.
EC-SAGINs: Edge Computing-enhanced Space-Air-Ground Integrated Networks for Internet of Vehicles
Jan 15, 2021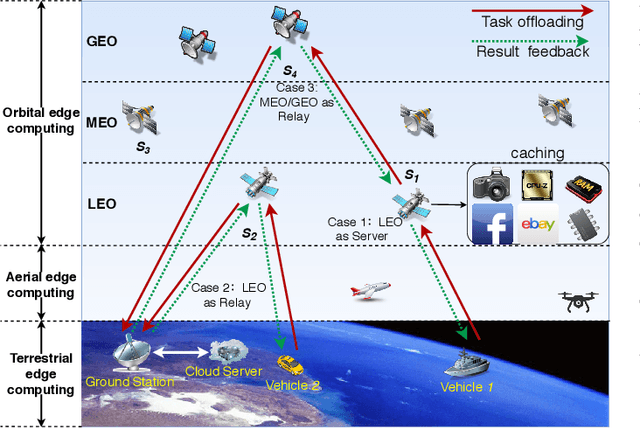
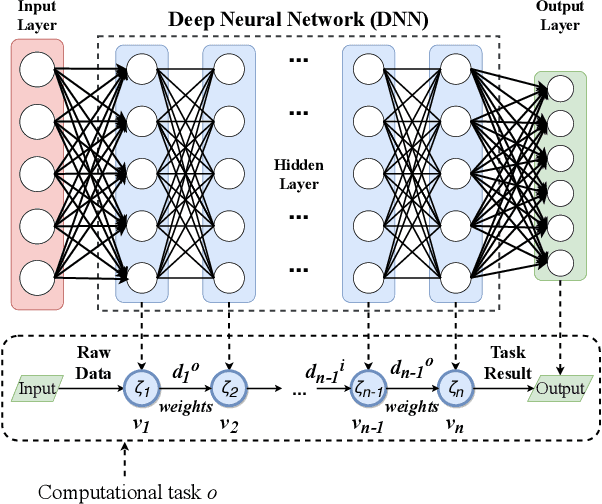
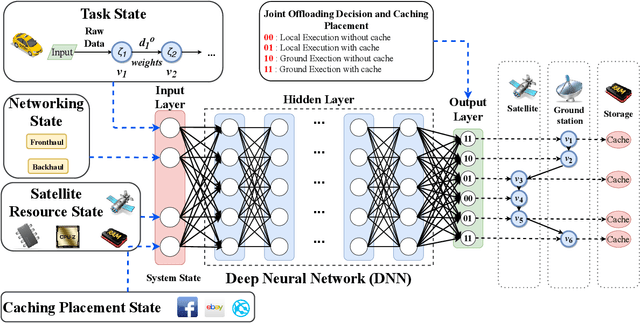
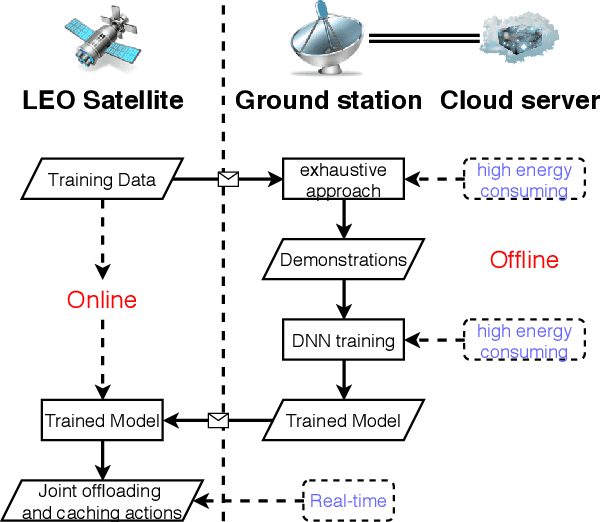
Edge computing-enhanced Internet of Vehicles (EC-IoV) enables ubiquitous data processing and content sharing among vehicles and terrestrial edge computing (TEC) infrastructures (e.g., 5G base stations and roadside units) with little or no human intervention, plays a key role in the intelligent transportation systems. However, EC-IoV is heavily dependent on the connections and interactions between vehicles and TEC infrastructures, thus will break down in some remote areas where TEC infrastructures are unavailable (e.g., desert, isolated islands and disaster-stricken areas). Driven by the ubiquitous connections and global-area coverage, space-air-ground integrated networks (SAGINs) efficiently support seamless coverage and efficient resource management, represent the next frontier for edge computing. In light of this, we first review the state-of-the-art edge computing research for SAGINs in this article. After discussing several existing orbital and aerial edge computing architectures, we propose a framework of edge computing-enabled space-air-ground integrated networks (EC-SAGINs) to support various IoV services for the vehicles in remote areas. The main objective of the framework is to minimize the task completion time and satellite resource usage. To this end, a pre-classification scheme is presented to reduce the size of action space, and a deep imitation learning (DIL) driven offloading and caching algorithm is proposed to achieve real-time decision making. Simulation results show the effectiveness of our proposed scheme. At last, we also discuss some technology challenges and future directions.
Few-Shot Hyperspectral Image Classification With Unknown Classes Using Multitask Deep Learning
Sep 08, 2020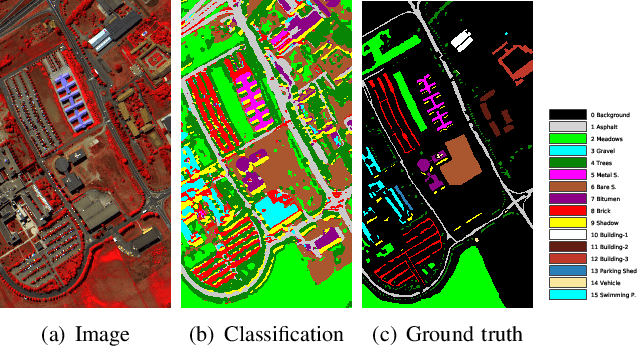
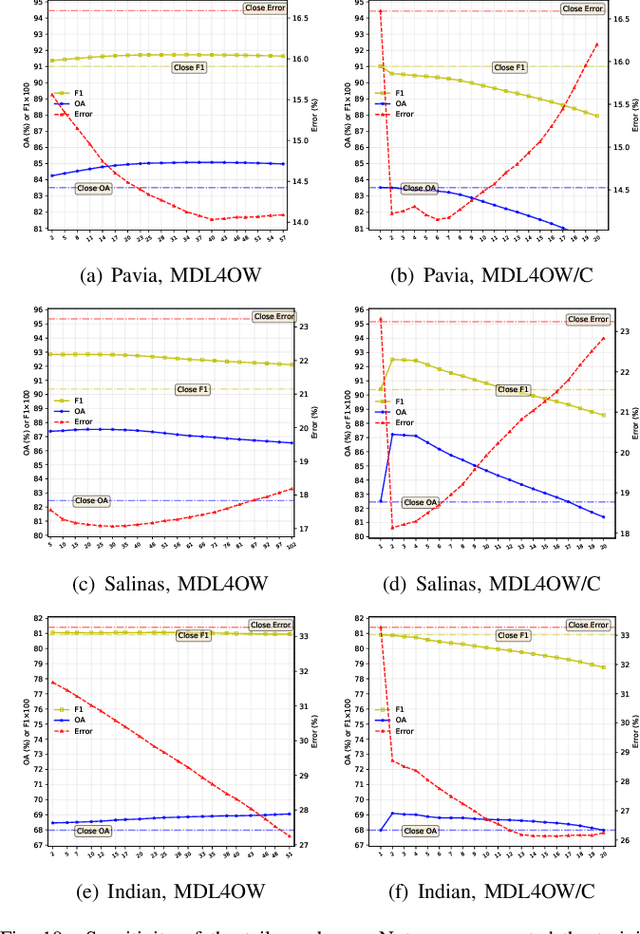
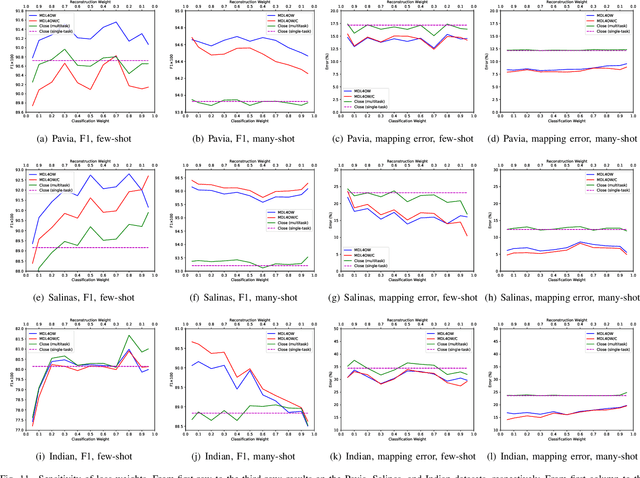

Current hyperspectral image classification assumes that a predefined classification system is closed and complete, and there are no unknown or novel classes in the unseen data. However, this assumption may be too strict for the real world. Often, novel classes are overlooked when the classification system is constructed. The closed nature forces a model to assign a label given a new sample and may lead to overestimation of known land covers (e.g., crop area). To tackle this issue, we propose a multitask deep learning method that simultaneously conducts classification and reconstruction in the open world (named MDL4OW) where unknown classes may exist. The reconstructed data are compared with the original data; those failing to be reconstructed are considered unknown, based on the assumption that they are not well represented in the latent features due to the lack of labels. A threshold needs to be defined to separate the unknown and known classes; we propose two strategies based on the extreme value theory for few-shot and many-shot scenarios. The proposed method was tested on real-world hyperspectral images; state-of-the-art results were achieved, e.g., improving the overall accuracy by 4.94% for the Salinas data. By considering the existence of unknown classes in the open world, our method achieved more accurate hyperspectral image classification, especially under the few-shot context.
Active Ensemble Deep Learning for Polarimetric Synthetic Aperture Radar Image Classification
Jun 29, 2020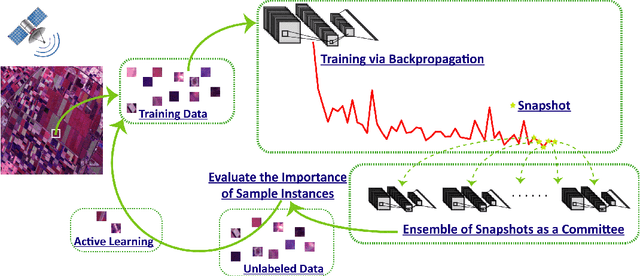

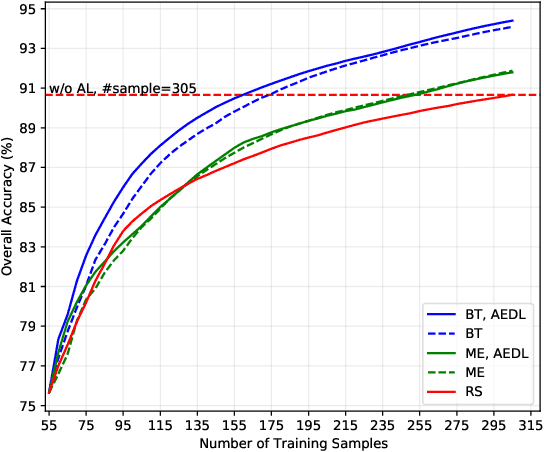

Although deep learning has achieved great success in image classification tasks, its performance is subject to the quantity and quality of training samples. For classification of polarimetric synthetic aperture radar (PolSAR) images, it is nearly impossible to annotate the images from visual interpretation. Therefore, it is urgent for remote sensing scientists to develop new techniques for PolSAR image classification under the condition of very few training samples. In this letter, we take the advantage of active learning and propose active ensemble deep learning (AEDL) for PolSAR image classification. We first show that only 35\% of the predicted labels of a deep learning model's snapshots near its convergence were exactly the same. The disagreement between snapshots is non-negligible. From the perspective of multiview learning, the snapshots together serve as a good committee to evaluate the importance of unlabeled instances. Using the snapshots committee to give out the informativeness of unlabeled data, the proposed AEDL achieved better performance on two real PolSAR images compared with standard active learning strategies. It achieved the same classification accuracy with only 86% and 55% of the training samples compared with breaking ties active learning and random selection for the Flevoland dataset.
Multitask deep learning with spectral knowledge for hyperspectral image classification
May 11, 2019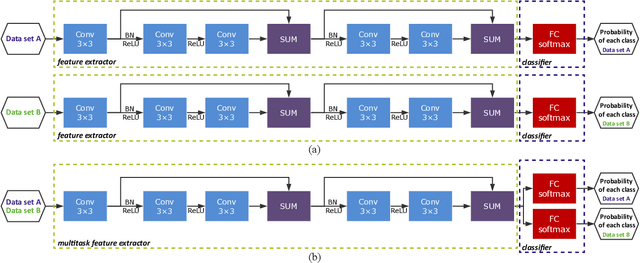

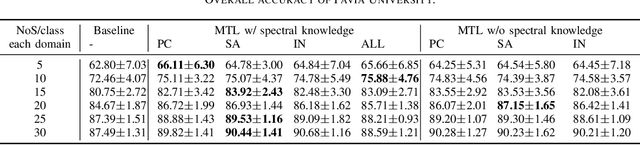

In this letter, we introduce multitask learning to hyperspectral image classification. Deep learning models have achieved promising results on hyperspectral image classification, but their performance highly rely on sufficient labeled samples, which are scarce on hyperspectral images. However, samples from multiple data sets might be sufficient to train one deep learning model, thereby improving its performance. To do so, spectral knowledge is introduced to ensure that the shared features are similar across domains. Four hyperspectral data sets were used in the experiments. We achieved better classification accuracies on three data sets (Pavia University, Indian Pines, and Pavia Center) originally with poor results or simple classification systems and competitive results on Salinas Valley data originally with a complex classification system. Spectral knowledge is useful to prevent the deep network from overfitting when the training samples were scarce. The proposed method successfully utilized samples from multiple data sets to increase its performance.