 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedEHR-Gen: Federated Synthetic Time-Series EHR Generation via Latent Space Alignment and Distribution-Aware Aggregation
May 27, 2026Synthetic Electronic Health Record (EHR) generation provides a promising avenue for data augmentation and cross-hospital modeling in privacy-constrained healthcare settings. However, most existing EHR generative models are centralized and require pooling data across hospitals, which is often infeasible when real-world data sharing is restricted. While federated EHR generation offers a natural solution, direct federated modeling often collapses or diverges due to the high dimensionality, sparsity, and cross-hospital heterogeneity of EHR data. In this work, we propose FedEHR-Gen, the first federated framework for synthetic time-series EHR generation across distributed hospitals. FedEHR-Gen uses a two-stage learning paradigm. First, we introduce a federated autoencoder that projects high-dimensional and sparse EHR features onto a compact latent space. To ensure semantic consistency across hospitals, we develop a layer-wise matching aggregation mechanism that aligns local encoders into a unified global latent space. Second, operating on this aligned latent space, we train a federated temporal conditional variational autoencoder (TCVAE) with distribution-aware aggregation, enabling stable temporal generative modeling under severe cross-hospital heterogeneity. Extensive experiments on the eICU and MIMIC-III datasets demonstrate that FedEHR-Gen achieves generation fidelity, downstream utility, and privacy risk comparable to centralized training, while consistently outperforming the standard federated baseline.
SafeRx-Agent: A Knowledge-Grounded Multi-Agent Framework for Safe and Explainable Medication Recommendation
May 27, 2026Medication recommendation predicts medications for patient visits, but existing methods still face two key challenges. At the model level, traditional drug recommendation methods only predict structured drug codes with limited evidence grounding, while LLM agents can use richer clinical context but may lack safety verification and traceability. At the task level, existing benchmarks often use broad medication categories, which ignore subgroup-level safety differences and can lead to risk overestimation. We introduce the first fine-grained medication recommendation setting based on fourth-level ATC code generation. We propose Safe Prescription Agent (SafeRx-Agent), a knowledge-grounded multi-agent framework that uses patient context, external clinical knowledge, and safety verification to recommend traceable medication sets. Experimental results on MIMIC-III and MIMIC-IV datasets show that SafeRx-Agent improves fine-grained medication prediction accuracy while controlling drug interactions, contraindications, and medication set size.
MV-S2V: Multi-View Subject-Consistent Video Generation
Jan 27, 2026Existing Subject-to-Video Generation (S2V) methods have achieved high-fidelity and subject-consistent video generation, yet remain constrained to single-view subject references. This limitation renders the S2V task reducible to an S2I + I2V pipeline, failing to exploit the full potential of video subject control. In this work, we propose and address the challenging Multi-View S2V (MV-S2V) task, which synthesizes videos from multiple reference views to enforce 3D-level subject consistency. Regarding the scarcity of training data, we first develop a synthetic data curation pipeline to generate highly customized synthetic data, complemented by a small-scale real-world captured dataset to boost the training of MV-S2V. Another key issue lies in the potential confusion between cross-subject and cross-view references in conditional generation. To overcome this, we further introduce Temporally Shifted RoPE (TS-RoPE) to distinguish between different subjects and distinct views of the same subject in reference conditioning. Our framework achieves superior 3D subject consistency w.r.t. multi-view reference images and high-quality visual outputs, establishing a new meaningful direction for subject-driven video generation. Our project page is available at: https://szy-young.github.io/mv-s2v
Depth Anything in $360^\circ$: Towards Scale Invariance in the Wild
Dec 28, 2025Panoramic depth estimation provides a comprehensive solution for capturing complete $360^\circ$ environmental structural information, offering significant benefits for robotics and AR/VR applications. However, while extensively studied in indoor settings, its zero-shot generalization to open-world domains lags far behind perspective images, which benefit from abundant training data. This disparity makes transferring capabilities from the perspective domain an attractive solution. To bridge this gap, we present Depth Anything in $360^\circ$ (DA360), a panoramic-adapted version of Depth Anything V2. Our key innovation involves learning a shift parameter from the ViT backbone, transforming the model's scale- and shift-invariant output into a scale-invariant estimate that directly yields well-formed 3D point clouds. This is complemented by integrating circular padding into the DPT decoder to eliminate seam artifacts, ensuring spatially coherent depth maps that respect spherical continuity. Evaluated on standard indoor benchmarks and our newly curated outdoor dataset, Metropolis, DA360 shows substantial gains over its base model, achieving over 50\% and 10\% relative depth error reduction on indoor and outdoor benchmarks, respectively. Furthermore, DA360 significantly outperforms robust panoramic depth estimation methods, achieving about 30\% relative error improvement compared to PanDA across all three test datasets and establishing new state-of-the-art performance for zero-shot panoramic depth estimation.
ByteLoom: Weaving Geometry-Consistent Human-Object Interactions through Progressive Curriculum Learning
Dec 28, 2025Human-object interaction (HOI) video generation has garnered increasing attention due to its promising applications in digital humans, e-commerce, advertising, and robotics imitation learning. However, existing methods face two critical limitations: (1) a lack of effective mechanisms to inject multi-view information of the object into the model, leading to poor cross-view consistency, and (2) heavy reliance on fine-grained hand mesh annotations for modeling interaction occlusions. To address these challenges, we introduce ByteLoom, a Diffusion Transformer (DiT)-based framework that generates realistic HOI videos with geometrically consistent object illustration, using simplified human conditioning and 3D object inputs. We first propose an RCM-cache mechanism that leverages Relative Coordinate Maps (RCM) as a universal representation to maintain object's geometry consistency and precisely control 6-DoF object transformations in the meantime. To compensate HOI dataset scarcity and leverage existing datasets, we further design a training curriculum that enhances model capabilities in a progressive style and relaxes the demand of hand mesh. Extensive experiments demonstrate that our method faithfully preserves human identity and the object's multi-view geometry, while maintaining smooth motion and object manipulation.
Anatomy-R1: Enhancing Anatomy Reasoning in Multimodal Large Language Models via Anatomical Similarity Curriculum and Group Diversity Augmentation
Dec 24, 2025Multimodal Large Language Models (MLLMs) have achieved impressive progress in natural image reasoning, yet their potential in medical imaging remains underexplored, especially in clinical anatomical surgical images. Anatomy understanding tasks demand precise understanding and clinically coherent answers, which are difficult to achieve due to the complexity of medical data and the scarcity of high-quality expert annotations. These challenges limit the effectiveness of conventional Supervised Fine-Tuning (SFT) strategies. While recent work has demonstrated that Group Relative Policy Optimization (GRPO) can enhance reasoning in MLLMs without relying on large amounts of data, we find two weaknesses that hinder GRPO's reasoning performance in anatomy recognition: 1) knowledge cannot be effectively shared between different anatomical structures, resulting in uneven information gain and preventing the model from converging, and 2) the model quickly converges to a single reasoning path, suppressing the exploration of diverse strategies. To overcome these challenges, we propose two novel methods. First, we implement a progressive learning strategy called Anatomical Similarity Curriculum Learning by controlling question difficulty via the similarity of answer choices, enabling the model to master complex problems incrementally. Second, we utilize question augmentation referred to as Group Diversity Question Augmentation to expand the model's search space for difficult queries, mitigating the tendency to produce uniform responses. Comprehensive experiments on the SGG-VQA and OmniMedVQA benchmarks show our method achieves a significant improvement across the two benchmarks, demonstrating its effectiveness in enhancing the medical reasoning capabilities of MLLMs. The code can be found in https://github.com/tomato996/Anatomy-R1
CETCAM: Camera-Controllable Video Generation via Consistent and Extensible Tokenization
Dec 22, 2025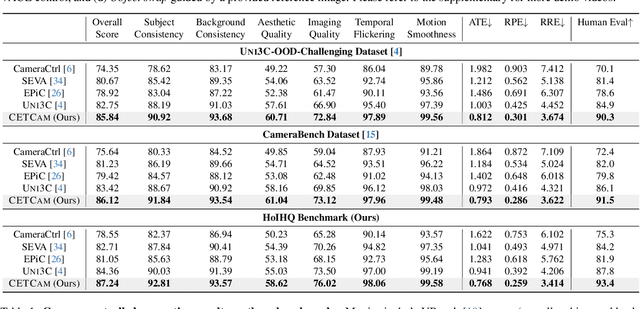
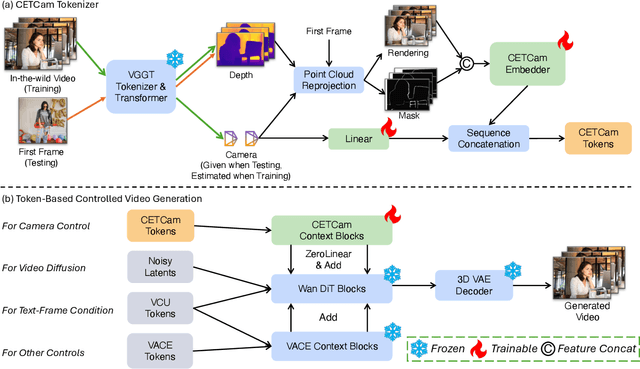
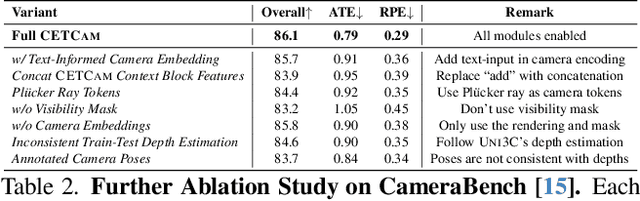

Achieving precise camera control in video generation remains challenging, as existing methods often rely on camera pose annotations that are difficult to scale to large and dynamic datasets and are frequently inconsistent with depth estimation, leading to train-test discrepancies. We introduce CETCAM, a camera-controllable video generation framework that eliminates the need for camera annotations through a consistent and extensible tokenization scheme. CETCAM leverages recent advances in geometry foundation models, such as VGGT, to estimate depth and camera parameters and converts them into unified, geometry-aware tokens. These tokens are seamlessly integrated into a pretrained video diffusion backbone via lightweight context blocks. Trained in two progressive stages, CETCAM first learns robust camera controllability from diverse raw video data and then refines fine-grained visual quality using curated high-fidelity datasets. Extensive experiments across multiple benchmarks demonstrate state-of-the-art geometric consistency, temporal stability, and visual realism. Moreover, CETCAM exhibits strong adaptability to additional control modalities, including inpainting and layout control, highlighting its flexibility beyond camera control. The project page is available at https://sjtuytc.github.io/CETCam_project_page.github.io/.
Cross-modal Retrieval Models for Stripped Binary Analysis
Dec 11, 2025
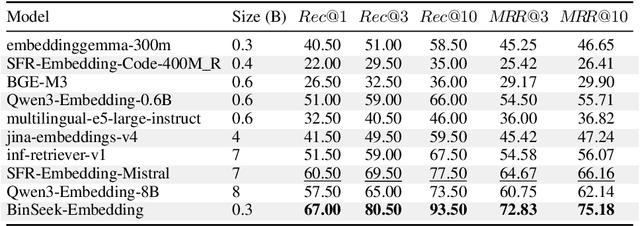
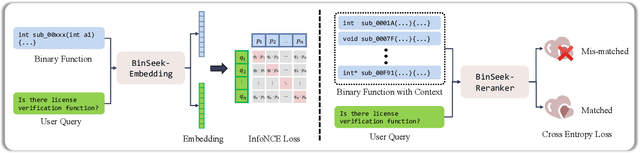
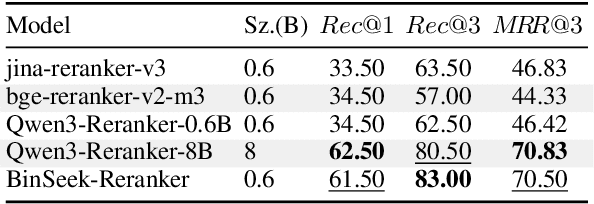
LLM-agent based binary code analysis has demonstrated significant potential across a wide range of software security scenarios, including vulnerability detection, malware analysis, etc. In agent workflow, however, retrieving the positive from thousands of stripped binary functions based on user query remains under-studied and challenging, as the absence of symbolic information distinguishes it from source code retrieval. In this paper, we introduce, BinSeek, the first two-stage cross-modal retrieval framework for stripped binary code analysis. It consists of two models: BinSeekEmbedding is trained on large-scale dataset to learn the semantic relevance of the binary code and the natural language description, furthermore, BinSeek-Reranker learns to carefully judge the relevance of the candidate code to the description with context augmentation. To this end, we built an LLM-based data synthesis pipeline to automate training construction, also deriving a domain benchmark for future research. Our evaluation results show that BinSeek achieved the state-of-the-art performance, surpassing the the same scale models by 31.42% in Rec@3 and 27.17% in MRR@3, as well as leading the advanced general-purpose models that have 16 times larger parameters.
Multimodal Causal-Driven Representation Learning for Generalizable Medical Image Segmentation
Aug 07, 2025Vision-Language Models (VLMs), such as CLIP, have demonstrated remarkable zero-shot capabilities in various computer vision tasks. However, their application to medical imaging remains challenging due to the high variability and complexity of medical data. Specifically, medical images often exhibit significant domain shifts caused by various confounders, including equipment differences, procedure artifacts, and imaging modes, which can lead to poor generalization when models are applied to unseen domains. To address this limitation, we propose Multimodal Causal-Driven Representation Learning (MCDRL), a novel framework that integrates causal inference with the VLM to tackle domain generalization in medical image segmentation. MCDRL is implemented in two steps: first, it leverages CLIP's cross-modal capabilities to identify candidate lesion regions and construct a confounder dictionary through text prompts, specifically designed to represent domain-specific variations; second, it trains a causal intervention network that utilizes this dictionary to identify and eliminate the influence of these domain-specific variations while preserving the anatomical structural information critical for segmentation tasks. Extensive experiments demonstrate that MCDRL consistently outperforms competing methods, yielding superior segmentation accuracy and exhibiting robust generalizability.
FreeGave: 3D Physics Learning from Dynamic Videos by Gaussian Velocity
Jun 09, 2025In this paper, we aim to model 3D scene geometry, appearance, and the underlying physics purely from multi-view videos. By applying various governing PDEs as PINN losses or incorporating physics simulation into neural networks, existing works often fail to learn complex physical motions at boundaries or require object priors such as masks or types. In this paper, we propose FreeGave to learn the physics of complex dynamic 3D scenes without needing any object priors. The key to our approach is to introduce a physics code followed by a carefully designed divergence-free module for estimating a per-Gaussian velocity field, without relying on the inefficient PINN losses. Extensive experiments on three public datasets and a newly collected challenging real-world dataset demonstrate the superior performance of our method for future frame extrapolation and motion segmentation. Most notably, our investigation into the learned physics codes reveals that they truly learn meaningful 3D physical motion patterns in the absence of any human labels in training.