 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSN: Infinite Representations of Dynamic 3D Scenes from Monocular Videos
Paper and Code
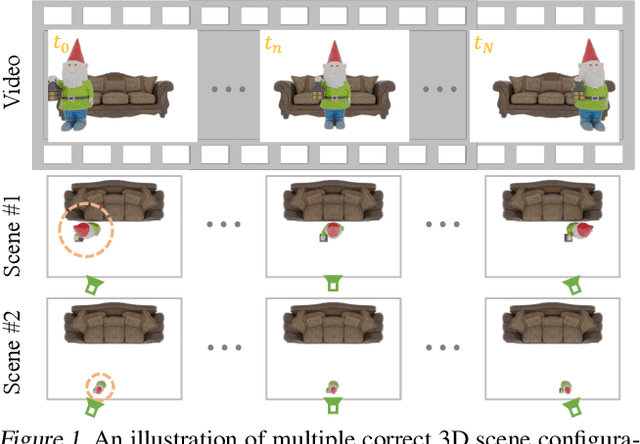
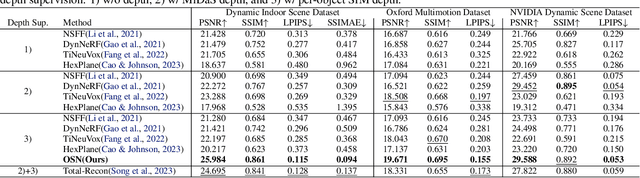
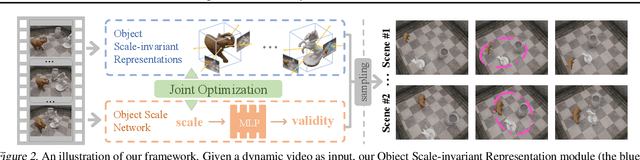
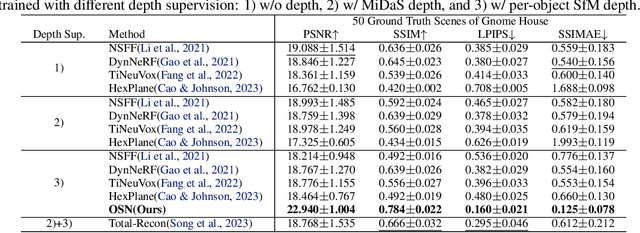
It has long been challenging to recover the underlying dynamic 3D scene representations from a monocular RGB video. Existing works formulate this problem into finding a single most plausible solution by adding various constraints such as depth priors and strong geometry constraints, ignoring the fact that there could be infinitely many 3D scene representations corresponding to a single dynamic video. In this paper, we aim to learn all plausible 3D scene configurations that match the input video, instead of just inferring a specific one. To achieve this ambitious goal, we introduce a new framework, called OSN. The key to our approach is a simple yet innovative object scale network together with a joint optimization module to learn an accurate scale range for every dynamic 3D object. This allows us to sample as many faithful 3D scene configurations as possible. Extensive experiments show that our method surpasses all baselines and achieves superior accuracy in dynamic novel view synthesis on multiple synthetic and real-world datasets. Most notably, our method demonstrates a clear advantage in learning fine-grained 3D scene geometry. Our code and data are available at https://github.com/vLAR-group/OSN