 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysInOne: Visual Physics Learning and Reasoning in One Suite
Apr 10, 2026We present PhysInOne, a large-scale synthetic dataset addressing the critical scarcity of physically-grounded training data for AI systems. Unlike existing datasets limited to merely hundreds or thousands of examples, PhysInOne provides 2 million videos across 153,810 dynamic 3D scenes, covering 71 basic physical phenomena in mechanics, optics, fluid dynamics, and magnetism. Distinct from previous works, our scenes feature multiobject interactions against complex backgrounds, with comprehensive ground-truth annotations including 3D geometry, semantics, dynamic motion, physical properties, and text descriptions. We demonstrate PhysInOne's efficacy across four emerging applications: physics-aware video generation, long-/short-term future frame prediction, physical property estimation, and motion transfer. Experiments show that fine-tuning foundation models on PhysInOne significantly enhances physical plausibility, while also exposing critical gaps in modeling complex physical dynamics and estimating intrinsic properties. As the largest dataset of its kind, orders of magnitude beyond prior works, PhysInOne establishes a new benchmark for advancing physics-grounded world models in generation, simulation, and embodied AI.
FreeGave: 3D Physics Learning from Dynamic Videos by Gaussian Velocity
Jun 09, 2025In this paper, we aim to model 3D scene geometry, appearance, and the underlying physics purely from multi-view videos. By applying various governing PDEs as PINN losses or incorporating physics simulation into neural networks, existing works often fail to learn complex physical motions at boundaries or require object priors such as masks or types. In this paper, we propose FreeGave to learn the physics of complex dynamic 3D scenes without needing any object priors. The key to our approach is to introduce a physics code followed by a carefully designed divergence-free module for estimating a per-Gaussian velocity field, without relying on the inefficient PINN losses. Extensive experiments on three public datasets and a newly collected challenging real-world dataset demonstrate the superior performance of our method for future frame extrapolation and motion segmentation. Most notably, our investigation into the learned physics codes reveals that they truly learn meaningful 3D physical motion patterns in the absence of any human labels in training.
OSN: Infinite Representations of Dynamic 3D Scenes from Monocular Videos
Jul 08, 2024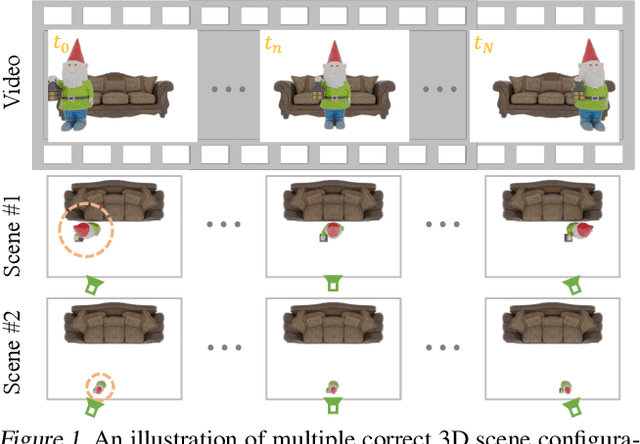
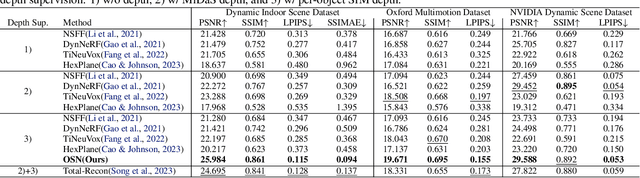
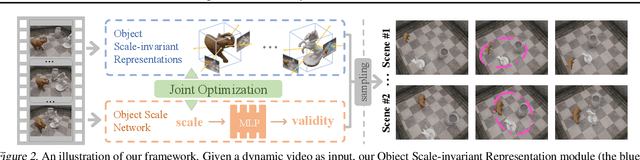
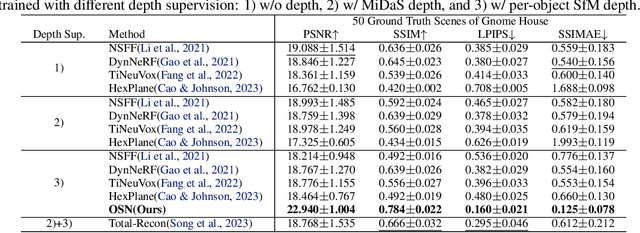
It has long been challenging to recover the underlying dynamic 3D scene representations from a monocular RGB video. Existing works formulate this problem into finding a single most plausible solution by adding various constraints such as depth priors and strong geometry constraints, ignoring the fact that there could be infinitely many 3D scene representations corresponding to a single dynamic video. In this paper, we aim to learn all plausible 3D scene configurations that match the input video, instead of just inferring a specific one. To achieve this ambitious goal, we introduce a new framework, called OSN. The key to our approach is a simple yet innovative object scale network together with a joint optimization module to learn an accurate scale range for every dynamic 3D object. This allows us to sample as many faithful 3D scene configurations as possible. Extensive experiments show that our method surpasses all baselines and achieves superior accuracy in dynamic novel view synthesis on multiple synthetic and real-world datasets. Most notably, our method demonstrates a clear advantage in learning fine-grained 3D scene geometry. Our code and data are available at https://github.com/vLAR-group/OSN
NVFi: Neural Velocity Fields for 3D Physics Learning from Dynamic Videos
Dec 11, 2023



In this paper, we aim to model 3D scene dynamics from multi-view videos. Unlike the majority of existing works which usually focus on the common task of novel view synthesis within the training time period, we propose to simultaneously learn the geometry, appearance, and physical velocity of 3D scenes only from video frames, such that multiple desirable applications can be supported, including future frame extrapolation, unsupervised 3D semantic scene decomposition, and dynamic motion transfer. Our method consists of three major components, 1) the keyframe dynamic radiance field, 2) the interframe velocity field, and 3) a joint keyframe and interframe optimization module which is the core of our framework to effectively train both networks. To validate our method, we further introduce two dynamic 3D datasets: 1) Dynamic Object dataset, and 2) Dynamic Indoor Scene dataset. We conduct extensive experiments on multiple datasets, demonstrating the superior performance of our method over all baselines, particularly in the critical tasks of future frame extrapolation and unsupervised 3D semantic scene decomposition.
Probabilistic Symmetry for Improved Trajectory Forecasting
May 04, 2022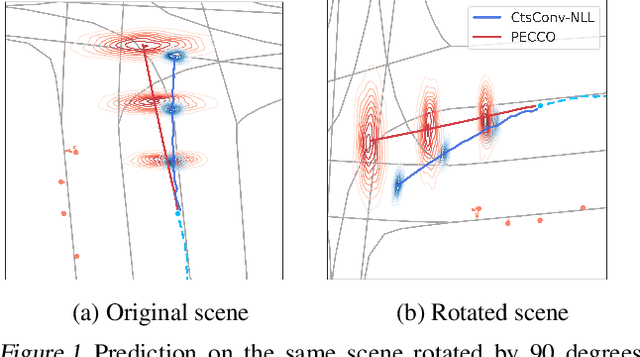
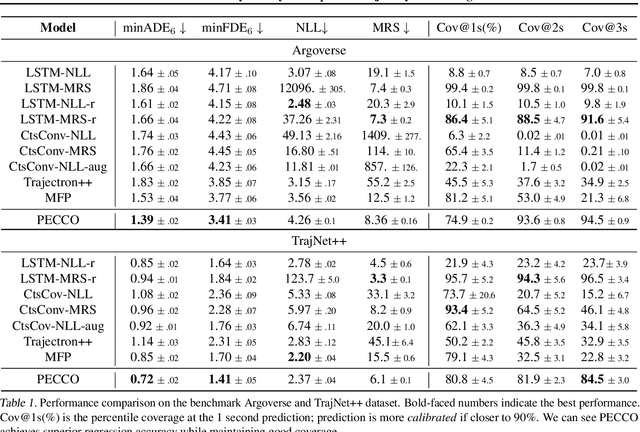
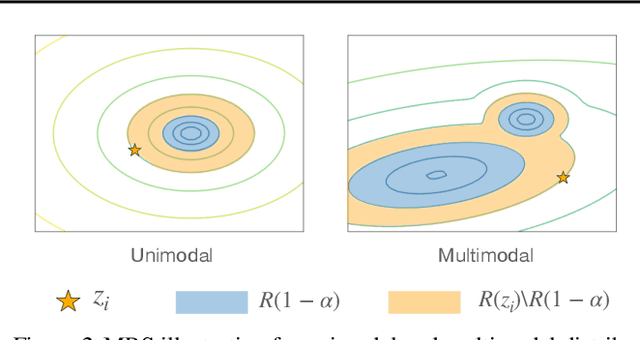

Trajectory prediction is a core AI problem with broad applications in robotics and autonomous driving. While most existing works focus on deterministic prediction, producing probabilistic forecasts to quantify prediction uncertainty is critical for downstream decision-making tasks such as risk assessment, motion planning, and safety guarantees. We introduce a new metric, mean regional score (MRS), to evaluate the quality of probabilistic trajectory forecasts. We propose a novel probabilistic trajectory prediction model, Probabilistic Equivariant Continuous COnvolution (PECCO) and show that leveraging symmetry, specifically rotation equivariance, can improve the predictions' accuracy as well as coverage. On both vehicle and pedestrian datasets, PECCO shows state-of-the-art prediction performance and improved calibration compared to baselines.
Trajectory Prediction using Equivariant Continuous Convolution
Oct 21, 2020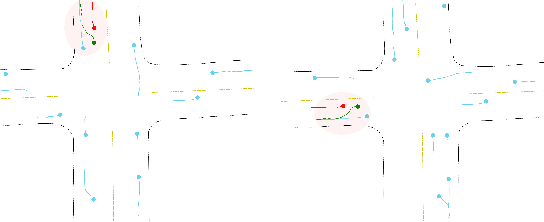
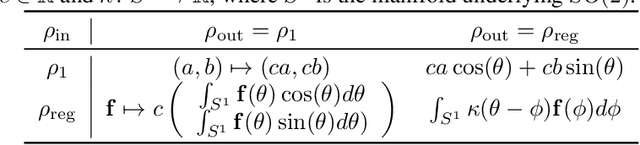
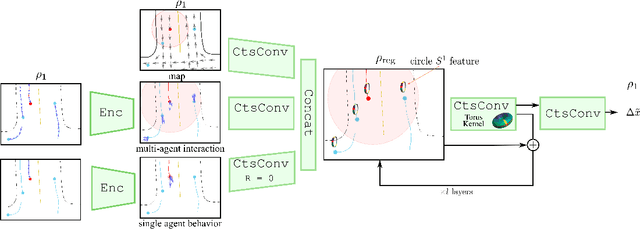
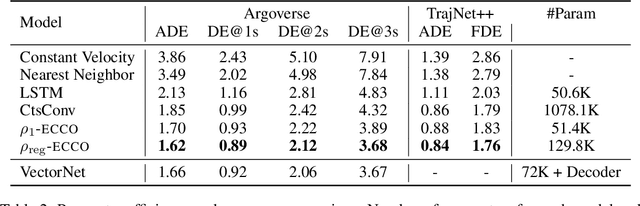
Trajectory prediction is a critical part of many AI applications, for example, the safe operation of autonomous vehicles. However, current methods are prone to making inconsistent and physically unrealistic predictions. We leverage insights from fluid dynamics to overcome this limitation by considering internal symmetry in trajectories. We propose a novel model, Equivariant Continous COnvolution (ECCO) for improved trajectory prediction. ECCO uses rotationally-equivariant continuous convolutions to embed the symmetries of the system. On two real-world vehicle and pedestrian trajectory datasets, ECCO attains competitive accuracy with significantly fewer parameters. It is also more sample efficient, generalizing automatically from few data points in any orientation. Lastly, ECCO improves generalization with equivariance, resulting in more physically consistent predictions. Our method provides a fresh perspective towards increasing trust and transparency in deep learning models.