 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixEHR-Nest: Identifying Subphenotypes within Electronic Health Records through Hierarchical Guided-Topic Modeling
Oct 17, 2024



Automatic subphenotyping from electronic health records (EHRs)provides numerous opportunities to understand diseases with unique subgroups and enhance personalized medicine for patients. However, existing machine learning algorithms either focus on specific diseases for better interpretability or produce coarse-grained phenotype topics without considering nuanced disease patterns. In this study, we propose a guided topic model, MixEHR-Nest, to infer sub-phenotype topics from thousands of disease using multi-modal EHR data. Specifically, MixEHR-Nest detects multiple subtopics from each phenotype topic, whose prior is guided by the expert-curated phenotype concepts such as Phenotype Codes (PheCodes) or Clinical Classification Software (CCS) codes. We evaluated MixEHR-Nest on two EHR datasets: (1) the MIMIC-III dataset consisting of over 38 thousand patients from intensive care unit (ICU) from Beth Israel Deaconess Medical Center (BIDMC) in Boston, USA; (2) the healthcare administrative database PopHR, comprising 1.3 million patients from Montreal, Canada. Experimental results demonstrate that MixEHR-Nest can identify subphenotypes with distinct patterns within each phenotype, which are predictive for disease progression and severity. Consequently, MixEHR-Nest distinguishes between type 1 and type 2 diabetes by inferring subphenotypes using CCS codes, which do not differentiate these two subtype concepts. Additionally, MixEHR-Nest not only improved the prediction accuracy of short-term mortality of ICU patients and initial insulin treatment in diabetic patients but also revealed the contributions of subphenotypes. For longitudinal analysis, MixEHR-Nest identified subphenotypes of distinct age prevalence under the same phenotypes, such as asthma, leukemia, epilepsy, and depression. The MixEHR-Nest software is available at GitHub: https://github.com/li-lab-mcgill/MixEHR-Nest.
Navigating the Digital World as Humans Do: Universal Visual Grounding for GUI Agents
Oct 07, 2024



Multimodal large language models (MLLMs) are transforming the capabilities of graphical user interface (GUI) agents, facilitating their transition from controlled simulations to complex, real-world applications across various platforms. However, the effectiveness of these agents hinges on the robustness of their grounding capability. Current GUI agents predominantly utilize text-based representations such as HTML or accessibility trees, which, despite their utility, often introduce noise, incompleteness, and increased computational overhead. In this paper, we advocate a human-like embodiment for GUI agents that perceive the environment entirely visually and directly take pixel-level operations on the GUI. The key is visual grounding models that can accurately map diverse referring expressions of GUI elements to their coordinates on the GUI across different platforms. We show that a simple recipe, which includes web-based synthetic data and slight adaptation of the LLaVA architecture, is surprisingly effective for training such visual grounding models. We collect the largest dataset for GUI visual grounding so far, containing 10M GUI elements and their referring expressions over 1.3M screenshots, and use it to train UGround, a strong universal visual grounding model for GUI agents. Empirical results on six benchmarks spanning three categories (grounding, offline agent, and online agent) show that 1) UGround substantially outperforms existing visual grounding models for GUI agents, by up to 20% absolute, and 2) agents with UGround outperform state-of-the-art agents, despite the fact that existing agents use additional text-based input while ours only uses visual perception. These results provide strong support for the feasibility and promises of GUI agents that navigate the digital world as humans do.
Investigating Vision Foundational Models for Tactile Representation Learning
Apr 30, 2023



Tactile representation learning (TRL) equips robots with the ability to leverage touch information, boosting performance in tasks such as environment perception and object manipulation. However, the heterogeneity of tactile sensors results in many sensor- and task-specific learning approaches. This limits the efficacy of existing tactile datasets, and the subsequent generalisability of any learning outcome. In this work, we investigate the applicability of vision foundational models to sensor-agnostic TRL, via a simple yet effective transformation technique to feed the heterogeneous sensor readouts into the model. Our approach recasts TRL as a computer vision (CV) problem, which permits the application of various CV techniques for tackling TRL-specific challenges. We evaluate our approach on multiple benchmark tasks, using datasets collected from four different tactile sensors. Empirically, we demonstrate significant improvements in task performance, model robustness, as well as cross-sensor and cross-task knowledge transferability with limited data requirements.
Robust Meta-Representation Learning via Global Label Inference and Classification
Dec 22, 2022Few-shot learning (FSL) is a central problem in meta-learning, where learners must efficiently learn from few labeled examples. Within FSL, feature pre-training has recently become an increasingly popular strategy to significantly improve generalization performance. However, the contribution of pre-training is often overlooked and understudied, with limited theoretical understanding of its impact on meta-learning performance. Further, pre-training requires a consistent set of global labels shared across training tasks, which may be unavailable in practice. In this work, we address the above issues by first showing the connection between pre-training and meta-learning. We discuss why pre-training yields more robust meta-representation and connect the theoretical analysis to existing works and empirical results. Secondly, we introduce Meta Label Learning (MeLa), a novel meta-learning algorithm that learns task relations by inferring global labels across tasks. This allows us to exploit pre-training for FSL even when global labels are unavailable or ill-defined. Lastly, we introduce an augmented pre-training procedure that further improves the learned meta-representation. Empirically, MeLa outperforms existing methods across a diverse range of benchmarks, in particular under a more challenging setting where the number of training tasks is limited and labels are task-specific. We also provide extensive ablation study to highlight its key properties.
Schedule-Robust Online Continual Learning
Oct 11, 2022
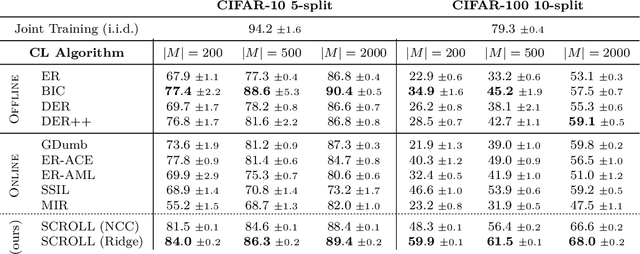
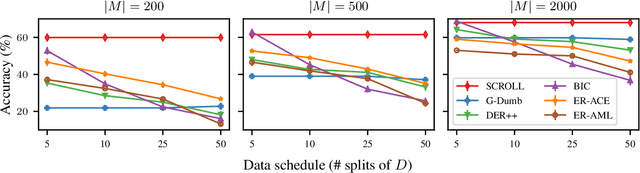
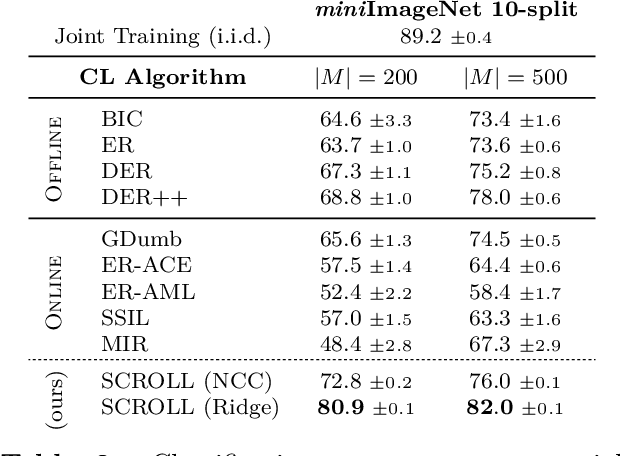
A continual learning (CL) algorithm learns from a non-stationary data stream. The non-stationarity is modeled by some schedule that determines how data is presented over time. Most current methods make strong assumptions on the schedule and have unpredictable performance when such requirements are not met. A key challenge in CL is thus to design methods robust against arbitrary schedules over the same underlying data, since in real-world scenarios schedules are often unknown and dynamic. In this work, we introduce the notion of schedule-robustness for CL and a novel approach satisfying this desirable property in the challenging online class-incremental setting. We also present a new perspective on CL, as the process of learning a schedule-robust predictor, followed by adapting the predictor using only replay data. Empirically, we demonstrate that our approach outperforms existing methods on CL benchmarks for image classification by a large margin.
The Role of Global Labels in Few-Shot Classification and How to Infer Them
Aug 09, 2021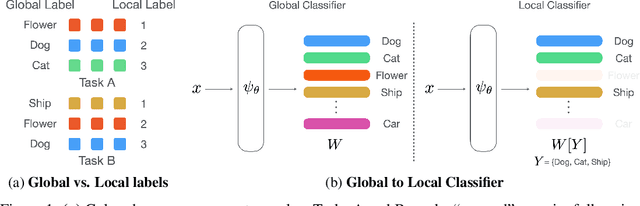
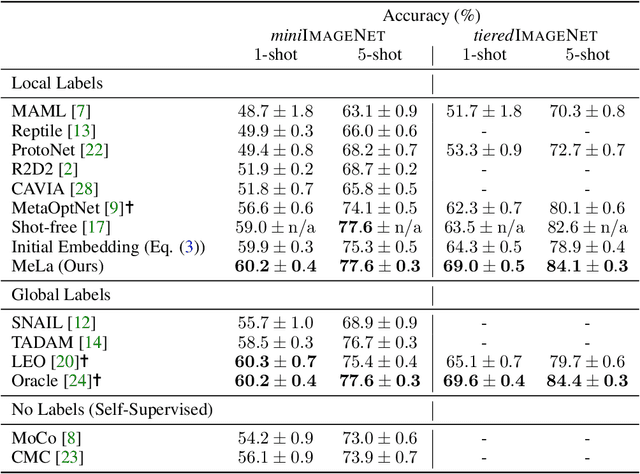


Few-shot learning (FSL) is a central problem in meta-learning, where learners must quickly adapt to new tasks given limited training data. Surprisingly, recent works have outperformed meta-learning methods tailored to FSL by casting it as standard supervised learning to jointly classify all classes shared across tasks. However, this approach violates the standard FSL setting by requiring global labels shared across tasks, which are often unavailable in practice. In this paper, we show why solving FSL via standard classification is theoretically advantageous. This motivates us to propose Meta Label Learning (MeLa), a novel algorithm that infers global labels and obtains robust few-shot models via standard classification. Empirically, we demonstrate that MeLa outperforms meta-learning competitors and is comparable to the oracle setting where ground truth labels are given. We provide extensive ablation studies to highlight the key properties of the proposed strategy.
Support-weighted Adversarial Imitation Learning
Feb 20, 2020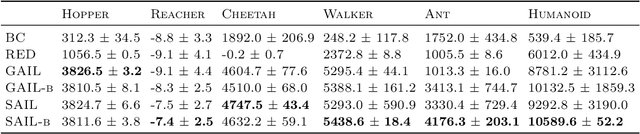
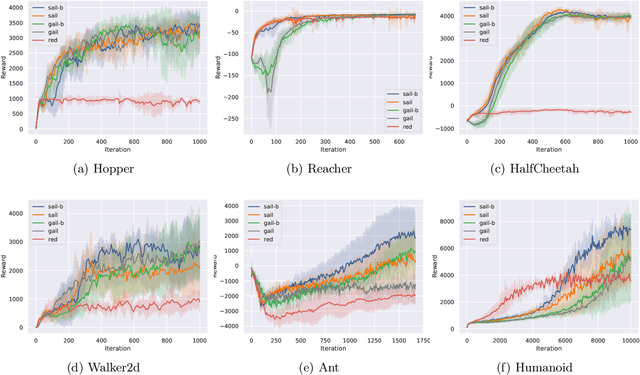


Adversarial Imitation Learning (AIL) is a broad family of imitation learning methods designed to mimic expert behaviors from demonstrations. While AIL has shown state-of-the-art performance on imitation learning with only small number of demonstrations, it faces several practical challenges such as potential training instability and implicit reward bias. To address the challenges, we propose Support-weighted Adversarial Imitation Learning (SAIL), a general framework that extends a given AIL algorithm with information derived from support estimation of the expert policies. SAIL improves the quality of the reinforcement signals by weighing the adversarial reward with a confidence score from support estimation of the expert policy. We also show that SAIL is always at least as efficient as the underlying AIL algorithm that SAIL uses for learning the adversarial reward. Empirically, we show that the proposed method achieves better performance and training stability than baseline methods on a wide range of benchmark control tasks.
A Structured Prediction Approach for Conditional Meta-Learning
Feb 20, 2020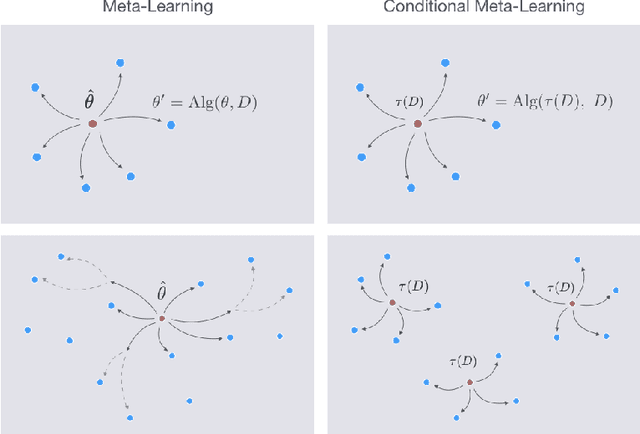
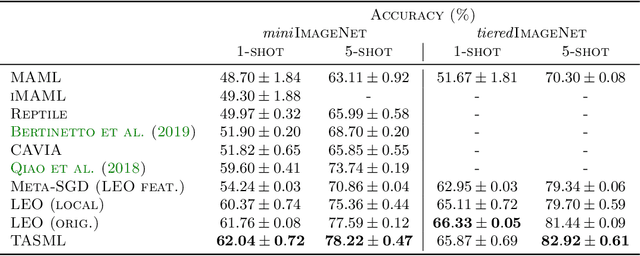
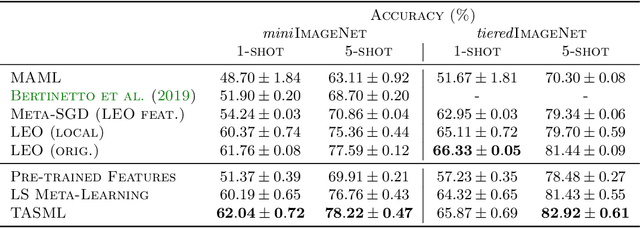

Optimization-based meta-learning algorithms are a powerful class of methods for learning-to-learn applications such as few-shot learning. They tackle the limited availability of training data by leveraging the experience gained from previously observed tasks. However, when the complexity of the tasks distribution cannot be captured by a single set of shared meta-parameters, existing methods may fail to fully adapt to a target task. We address this issue with a novel perspective on conditional meta-learning based on structured prediction. We propose task-adaptive structured meta-learning (TASML), a principled estimator that weighs meta-training data conditioned on the target task to design tailored meta-learning objectives. In addition, we introduce algorithmic improvements to tackle key computational limitations of existing methods. Experimentally, we show that TASML outperforms state-of-the-art methods on benchmark datasets both in terms of accuracy and efficiency. An ablation study quantifies the individual contribution of model components and suggests useful practices for meta-learning.
Random Expert Distillation: Imitation Learning via Expert Policy Support Estimation
May 16, 2019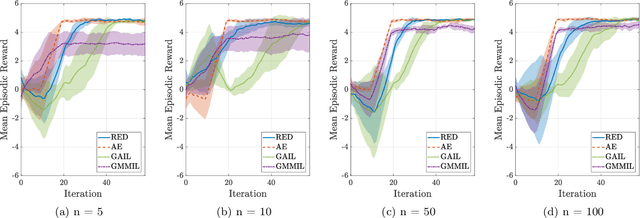

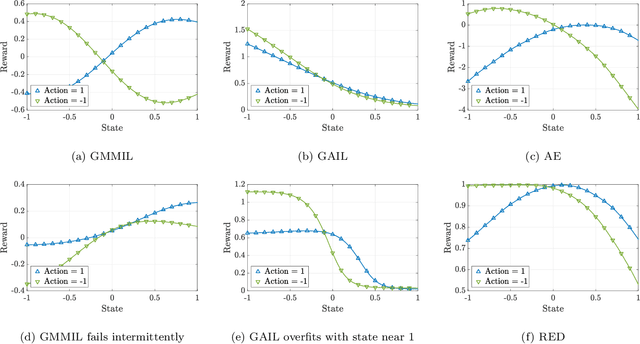
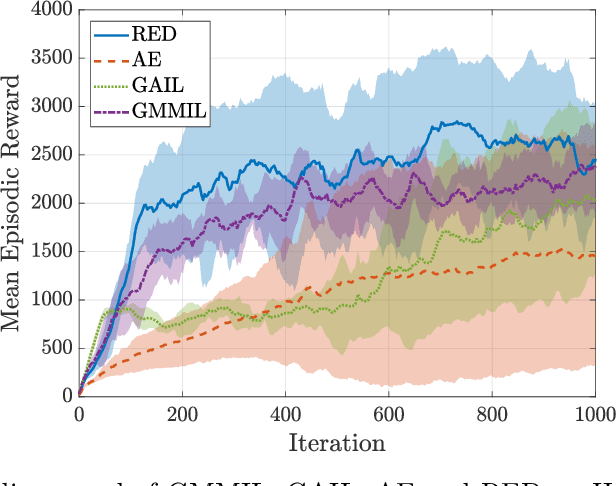
We consider the problem of imitation learning from a finite set of expert trajectories, without access to reinforcement signals. The classical approach of extracting the expert's reward function via inverse reinforcement learning, followed by reinforcement learning is indirect and may be computationally expensive. Recent generative adversarial methods based on matching the policy distribution between the expert and the agent could be unstable during training. We propose a new framework for imitation learning by estimating the support of the expert policy to compute a fixed reward function, which allows us to re-frame imitation learning within the standard reinforcement learning setting. We demonstrate the efficacy of our reward function on both discrete and continuous domains, achieving comparable or better performance than the state of the art under different reinforcement learning algorithms.
Real-Time Workload Classification during Driving using HyperNetworks
Oct 07, 2018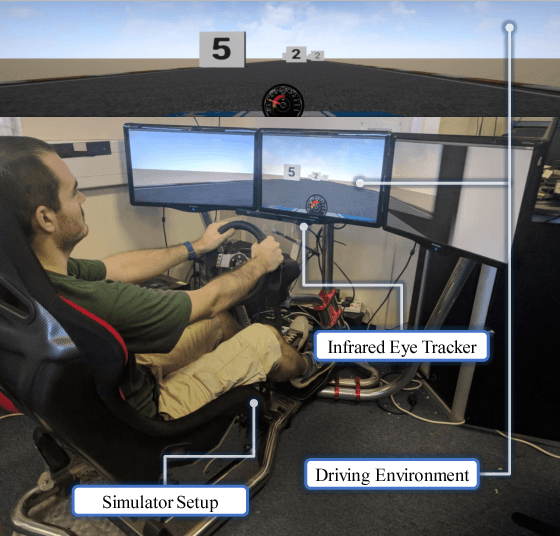


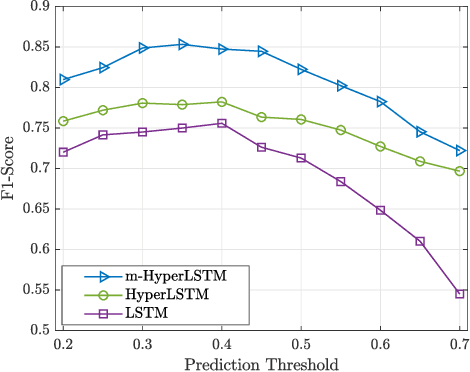
Classifying human cognitive states from behavioral and physiological signals is a challenging problem with important applications in robotics. The problem is challenging due to the data variability among individual users, and sensor artefacts. In this work, we propose an end-to-end framework for real-time cognitive workload classification with mixture Hyper Long Short Term Memory Networks, a novel variant of HyperNetworks. Evaluating the proposed approach on an eye-gaze pattern dataset collected from simulated driving scenarios of different cognitive demands, we show that the proposed framework outperforms previous baseline methods and achieves 83.9\% precision and 87.8\% recall during test. We also demonstrate the merit of our proposed architecture by showing improved performance over other LSTM-based methods.