 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHearables: Ear EEG Based Driver Fatigue Detection
Jan 16, 2023



Ear EEG based driver fatigue monitoring systems have the potential to provide a seamless, efficient, and feasibly deployable alternative to existing scalp EEG based systems, which are often cumbersome and impractical. However, the feasibility of detecting the relevant delta, theta, alpha, and beta band EEG activity through the ear EEG is yet to be investigated. Through measurements of scalp and ear EEG on ten subjects during a simulated, monotonous driving experiment, this study provides statistical analysis of characteristic ear EEG changes that are associated with the transition from alert to mentally fatigued states, and subsequent testing of a machine learning based automatic fatigue detection model. Novel numerical evidence is provided to support the feasibility of detection of mental fatigue with ear EEG that is in agreement with widely reported scalp EEG findings. This study paves the way for the development of ultra-wearable and readily deployable hearables based driver fatigue monitoring systems.
Support-weighted Adversarial Imitation Learning
Feb 20, 2020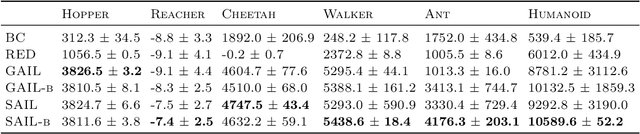
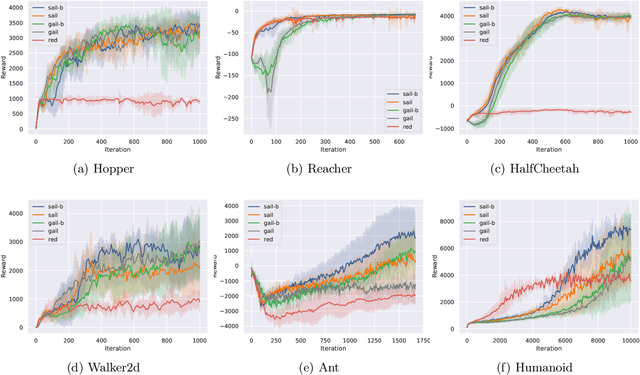


Adversarial Imitation Learning (AIL) is a broad family of imitation learning methods designed to mimic expert behaviors from demonstrations. While AIL has shown state-of-the-art performance on imitation learning with only small number of demonstrations, it faces several practical challenges such as potential training instability and implicit reward bias. To address the challenges, we propose Support-weighted Adversarial Imitation Learning (SAIL), a general framework that extends a given AIL algorithm with information derived from support estimation of the expert policies. SAIL improves the quality of the reinforcement signals by weighing the adversarial reward with a confidence score from support estimation of the expert policy. We also show that SAIL is always at least as efficient as the underlying AIL algorithm that SAIL uses for learning the adversarial reward. Empirically, we show that the proposed method achieves better performance and training stability than baseline methods on a wide range of benchmark control tasks.
Random Expert Distillation: Imitation Learning via Expert Policy Support Estimation
May 16, 2019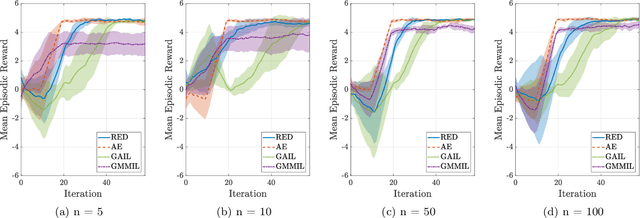

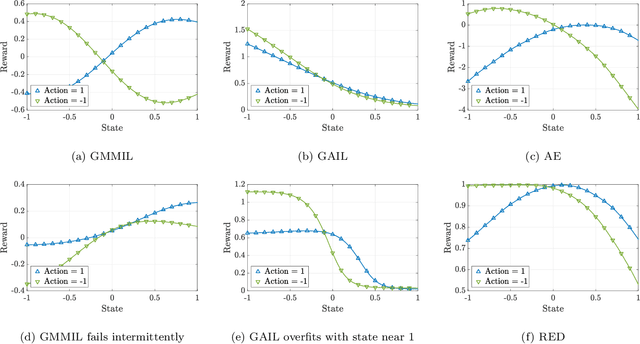
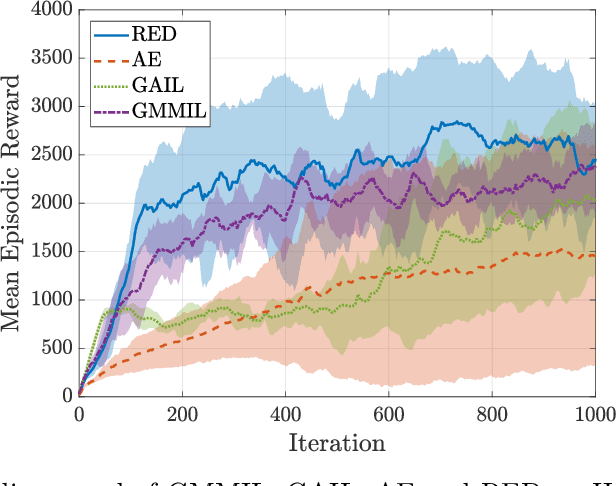
We consider the problem of imitation learning from a finite set of expert trajectories, without access to reinforcement signals. The classical approach of extracting the expert's reward function via inverse reinforcement learning, followed by reinforcement learning is indirect and may be computationally expensive. Recent generative adversarial methods based on matching the policy distribution between the expert and the agent could be unstable during training. We propose a new framework for imitation learning by estimating the support of the expert policy to compute a fixed reward function, which allows us to re-frame imitation learning within the standard reinforcement learning setting. We demonstrate the efficacy of our reward function on both discrete and continuous domains, achieving comparable or better performance than the state of the art under different reinforcement learning algorithms.