 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupport-weighted Adversarial Imitation Learning
Paper and Code
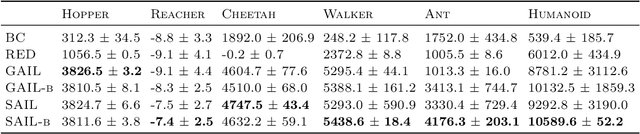
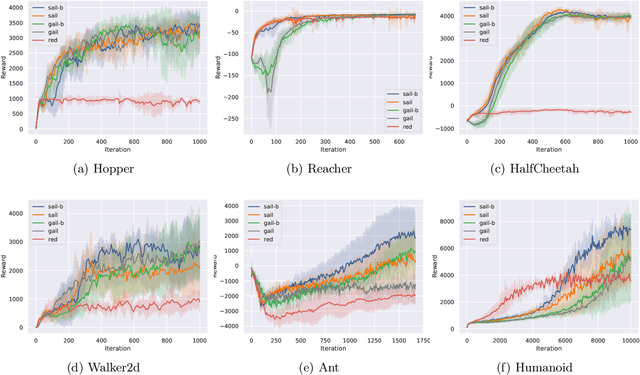


Adversarial Imitation Learning (AIL) is a broad family of imitation learning methods designed to mimic expert behaviors from demonstrations. While AIL has shown state-of-the-art performance on imitation learning with only small number of demonstrations, it faces several practical challenges such as potential training instability and implicit reward bias. To address the challenges, we propose Support-weighted Adversarial Imitation Learning (SAIL), a general framework that extends a given AIL algorithm with information derived from support estimation of the expert policies. SAIL improves the quality of the reinforcement signals by weighing the adversarial reward with a confidence score from support estimation of the expert policy. We also show that SAIL is always at least as efficient as the underlying AIL algorithm that SAIL uses for learning the adversarial reward. Empirically, we show that the proposed method achieves better performance and training stability than baseline methods on a wide range of benchmark control tasks.