 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Your LLM Secretly a World Model of the Internet? Model-Based Planning for Web Agents
Nov 10, 2024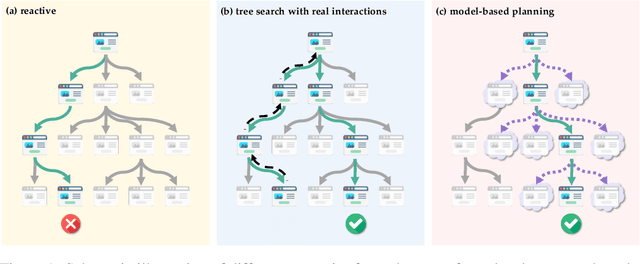

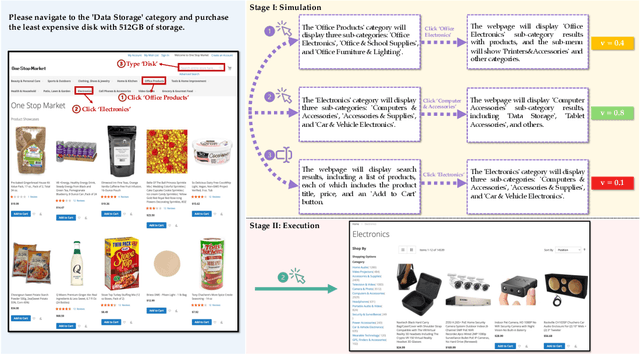

Language agents have demonstrated promising capabilities in automating web-based tasks, though their current reactive approaches still underperform largely compared to humans. While incorporating advanced planning algorithms, particularly tree search methods, could enhance these agents' performance, implementing tree search directly on live websites poses significant safety risks and practical constraints due to irreversible actions such as confirming a purchase. In this paper, we introduce a novel paradigm that augments language agents with model-based planning, pioneering the innovative use of large language models (LLMs) as world models in complex web environments. Our method, WebDreamer, builds on the key insight that LLMs inherently encode comprehensive knowledge about website structures and functionalities. Specifically, WebDreamer uses LLMs to simulate outcomes for each candidate action (e.g., "what would happen if I click this button?") using natural language descriptions, and then evaluates these imagined outcomes to determine the optimal action at each step. Empirical results on two representative web agent benchmarks with online interaction -- VisualWebArena and Mind2Web-live -- demonstrate that WebDreamer achieves substantial improvements over reactive baselines. By establishing the viability of LLMs as world models in web environments, this work lays the groundwork for a paradigm shift in automated web interaction. More broadly, our findings open exciting new avenues for future research into 1) optimizing LLMs specifically for world modeling in complex, dynamic environments, and 2) model-based speculative planning for language agents.
Navigating the Digital World as Humans Do: Universal Visual Grounding for GUI Agents
Oct 07, 2024



Multimodal large language models (MLLMs) are transforming the capabilities of graphical user interface (GUI) agents, facilitating their transition from controlled simulations to complex, real-world applications across various platforms. However, the effectiveness of these agents hinges on the robustness of their grounding capability. Current GUI agents predominantly utilize text-based representations such as HTML or accessibility trees, which, despite their utility, often introduce noise, incompleteness, and increased computational overhead. In this paper, we advocate a human-like embodiment for GUI agents that perceive the environment entirely visually and directly take pixel-level operations on the GUI. The key is visual grounding models that can accurately map diverse referring expressions of GUI elements to their coordinates on the GUI across different platforms. We show that a simple recipe, which includes web-based synthetic data and slight adaptation of the LLaVA architecture, is surprisingly effective for training such visual grounding models. We collect the largest dataset for GUI visual grounding so far, containing 10M GUI elements and their referring expressions over 1.3M screenshots, and use it to train UGround, a strong universal visual grounding model for GUI agents. Empirical results on six benchmarks spanning three categories (grounding, offline agent, and online agent) show that 1) UGround substantially outperforms existing visual grounding models for GUI agents, by up to 20% absolute, and 2) agents with UGround outperform state-of-the-art agents, despite the fact that existing agents use additional text-based input while ours only uses visual perception. These results provide strong support for the feasibility and promises of GUI agents that navigate the digital world as humans do.
Noise-Aware Training of Layout-Aware Language Models
Mar 30, 2024A visually rich document (VRD) utilizes visual features along with linguistic cues to disseminate information. Training a custom extractor that identifies named entities from a document requires a large number of instances of the target document type annotated at textual and visual modalities. This is an expensive bottleneck in enterprise scenarios, where we want to train custom extractors for thousands of different document types in a scalable way. Pre-training an extractor model on unlabeled instances of the target document type, followed by a fine-tuning step on human-labeled instances does not work in these scenarios, as it surpasses the maximum allowable training time allocated for the extractor. We address this scenario by proposing a Noise-Aware Training method or NAT in this paper. Instead of acquiring expensive human-labeled documents, NAT utilizes weakly labeled documents to train an extractor in a scalable way. To avoid degradation in the model's quality due to noisy, weakly labeled samples, NAT estimates the confidence of each training sample and incorporates it as uncertainty measure during training. We train multiple state-of-the-art extractor models using NAT. Experiments on a number of publicly available and in-house datasets show that NAT-trained models are not only robust in performance -- it outperforms a transfer-learning baseline by up to 6% in terms of macro-F1 score, but it is also more label-efficient -- it reduces the amount of human-effort required to obtain comparable performance by up to 73%.