 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Your LLM Secretly a World Model of the Internet? Model-Based Planning for Web Agents
Nov 10, 2024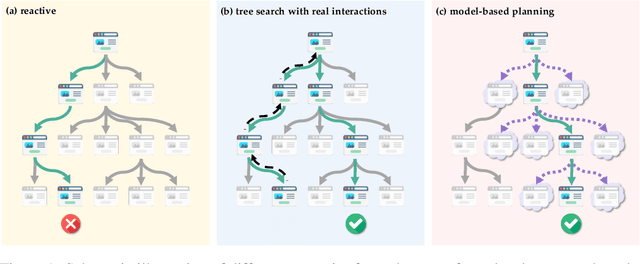

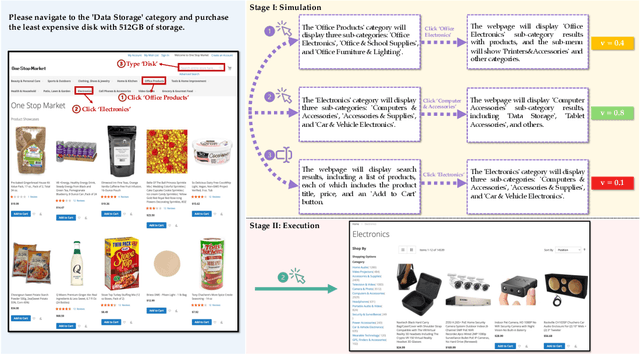

Language agents have demonstrated promising capabilities in automating web-based tasks, though their current reactive approaches still underperform largely compared to humans. While incorporating advanced planning algorithms, particularly tree search methods, could enhance these agents' performance, implementing tree search directly on live websites poses significant safety risks and practical constraints due to irreversible actions such as confirming a purchase. In this paper, we introduce a novel paradigm that augments language agents with model-based planning, pioneering the innovative use of large language models (LLMs) as world models in complex web environments. Our method, WebDreamer, builds on the key insight that LLMs inherently encode comprehensive knowledge about website structures and functionalities. Specifically, WebDreamer uses LLMs to simulate outcomes for each candidate action (e.g., "what would happen if I click this button?") using natural language descriptions, and then evaluates these imagined outcomes to determine the optimal action at each step. Empirical results on two representative web agent benchmarks with online interaction -- VisualWebArena and Mind2Web-live -- demonstrate that WebDreamer achieves substantial improvements over reactive baselines. By establishing the viability of LLMs as world models in web environments, this work lays the groundwork for a paradigm shift in automated web interaction. More broadly, our findings open exciting new avenues for future research into 1) optimizing LLMs specifically for world modeling in complex, dynamic environments, and 2) model-based speculative planning for language agents.
De-amplifying Bias from Differential Privacy in Language Model Fine-tuning
Feb 07, 2024



Fairness and privacy are two important values machine learning (ML) practitioners often seek to operationalize in models. Fairness aims to reduce model bias for social/demographic sub-groups. Privacy via differential privacy (DP) mechanisms, on the other hand, limits the impact of any individual's training data on the resulting model. The trade-offs between privacy and fairness goals of trustworthy ML pose a challenge to those wishing to address both. We show that DP amplifies gender, racial, and religious bias when fine-tuning large language models (LLMs), producing models more biased than ones fine-tuned without DP. We find the cause of the amplification to be a disparity in convergence of gradients across sub-groups. Through the case of binary gender bias, we demonstrate that Counterfactual Data Augmentation (CDA), a known method for addressing bias, also mitigates bias amplification by DP. As a consequence, DP and CDA together can be used to fine-tune models while maintaining both fairness and privacy.
LMPriors: Pre-Trained Language Models as Task-Specific Priors
Oct 22, 2022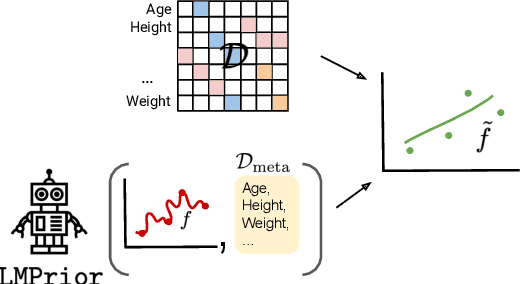
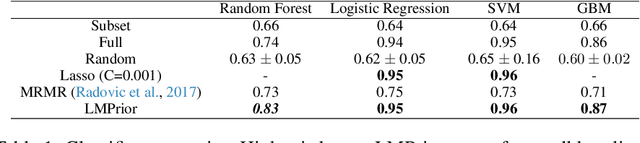


Particularly in low-data regimes, an outstanding challenge in machine learning is developing principled techniques for augmenting our models with suitable priors. This is to encourage them to learn in ways that are compatible with our understanding of the world. But in contrast to generic priors such as shrinkage or sparsity, we draw inspiration from the recent successes of large-scale language models (LMs) to construct task-specific priors distilled from the rich knowledge of LMs. Our method, Language Model Priors (LMPriors), incorporates auxiliary natural language metadata about the task -- such as variable names and descriptions -- to encourage downstream model outputs to be consistent with the LM's common-sense reasoning based on the metadata. Empirically, we demonstrate that LMPriors improve model performance in settings where such natural language descriptions are available, and perform well on several tasks that benefit from such prior knowledge, such as feature selection, causal inference, and safe reinforcement learning.