 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Efficient Learning with Online Expert Correction for Autonomous Catheter Steering in Endovascular Bifurcation Navigation
Feb 23, 2026Robot-assisted endovascular intervention offers a safe and effective solution for remote catheter manipulation, reducing radiation exposure while enabling precise navigation. Reinforcement learning (RL) has recently emerged as a promising approach for autonomous catheter steering; however, conventional methods suffer from sparse reward design and reliance on static vascular models, limiting their sample efficiency and generalization to intraoperative variations. To overcome these challenges, this paper introduces a sample-efficient RL framework with online expert correction for autonomous catheter steering in endovascular bifurcation navigation. The proposed framework integrates three key components: (1) A segmentation-based pose estimation module for accurate real-time state feedback, (2) A fuzzy controller for bifurcation-aware orientation adjustment, and (3) A structured reward generator incorporating expert priors to guide policy learning. By leveraging online expert correction, the framework reduces exploration inefficiency and enhances policy robustness in complex vascular structures. Experimental validation on a robotic platform using a transparent vascular phantom demonstrates that the proposed approach achieves convergence in 123 training episodes -- a 25.9% reduction compared to the baseline Soft Actor-Critic (SAC) algorithm -- while reducing average positional error to 83.8% of the baseline. These results indicate that combining sample-efficient RL with online expert correction enables reliable and accurate catheter steering, particularly in anatomically challenging bifurcation scenarios critical for endovascular navigation.
Vision-Based Reasoning with Topology-Encoded Graphs for Anatomical Path Disambiguation in Robot-Assisted Endovascular Navigation
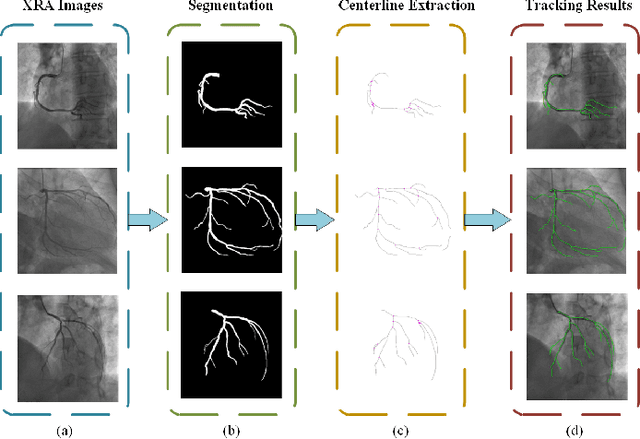
Feb 23, 2026Robotic-assisted percutaneous coronary intervention (PCI) is constrained by the inherent limitations of 2D Digital Subtraction Angiography (DSA). Unlike physicians, who can directly manipulate guidewires and integrate tactile feedback with their prior anatomical knowledge, teleoperated robotic systems must rely solely on 2D projections. This mode of operation, simultaneously lacking spatial context and tactile sensation, may give rise to projection-induced ambiguities at vascular bifurcations. To address this challenge, we propose a two-stage framework (SCAR-UNet-GAT) for real-time robotic path planning. In the first stage, SCAR-UNet, a spatial-coordinate-attention-regularized U-Net, is employed for accurate coronary vessel segmentation. The integration of multi-level attention mechanisms enhances the delineation of thin, tortuous vessels and improves robustness against imaging noise. From the resulting binary masks, vessel centerlines and bifurcation points are extracted, and geometric descriptors (e.g., branch diameter, intersection angles) are fused with local DSA patches to construct node features. In the second stage, a Graph Attention Network (GAT) reasons over the vessel graph to identify anatomically consistent and clinically feasible trajectories, effectively distinguishing true bifurcations from projection-induced false crossings. On a clinical DSA dataset, SCAR-UNet achieved a Dice coefficient of 93.1%. For path disambiguation, the proposed GAT-based method attained a success rate of 95.0% and a target-arrival success rate of 90.0%, substantially outperforming conventional shortest-path planning (60.0% and 55.0%) and heuristic-based planning (75.0% and 70.0%). Validation on a robotic platform further confirmed the practical feasibility and robustness of the proposed framework.
Toward Trustworthy Evaluation of Sustainability Rating Methodologies: A Human-AI Collaborative Framework for Benchmark Dataset Construction
Feb 19, 2026Sustainability or ESG rating agencies use company disclosures and external data to produce scores or ratings that assess the environmental, social, and governance performance of a company. However, sustainability ratings across agencies for a single company vary widely, limiting their comparability, credibility, and relevance to decision-making. To harmonize the rating results, we propose adopting a universal human-AI collaboration framework to generate trustworthy benchmark datasets for evaluating sustainability rating methodologies. The framework comprises two complementary parts: STRIDE (Sustainability Trust Rating & Integrity Data Equation) provides principled criteria and a scoring system that guide the construction of firm-level benchmark datasets using large language models (LLMs), and SR-Delta, a discrepancy-analysis procedural framework that surfaces insights for potential adjustments. The framework enables scalable and comparable assessment of sustainability rating methodologies. We call on the broader AI community to adopt AI-powered approaches to strengthen and advance sustainability rating methodologies that support and enforce urgent sustainability agendas.
Deep-Learning-Based Control of a Decoupled Two-Segment Continuum Robot for Endoscopic Submucosal Dissection
Feb 03, 2026Manual endoscopic submucosal dissection (ESD) is technically demanding, and existing single-segment robotic tools offer limited dexterity. These limitations motivate the development of more advanced solutions. To address this, DESectBot, a novel dual segment continuum robot with a decoupled structure and integrated surgical forceps, enabling 6 degrees of freedom (DoFs) tip dexterity for improved lesion targeting in ESD, was developed in this work. Deep learning controllers based on gated recurrent units (GRUs) for simultaneous tip position and orientation control, effectively handling the nonlinear coupling between continuum segments, were proposed. The GRU controller was benchmarked against Jacobian based inverse kinematics, model predictive control (MPC), a feedforward neural network (FNN), and a long short-term memory (LSTM) network. In nested-rectangle and Lissajous trajectory tracking tasks, the GRU achieved the lowest position/orientation RMSEs: 1.11 mm/ 4.62° and 0.81 mm/ 2.59°, respectively. For orientation control at a fixed position (four target poses), the GRU attained a mean RMSE of 0.14 mm and 0.72°, outperforming all alternatives. In a peg transfer task, the GRU achieved a 100% success rate (120 success/120 attempts) with an average transfer time of 11.8s, the STD significantly outperforms novice-controlled systems. Additionally, an ex vivo ESD demonstration grasping, elevating, and resecting tissue as the scalpel completed the cut confirmed that DESectBot provides sufficient stiffness to divide thick gastric mucosa and an operative workspace adequate for large lesions.These results confirm that GRU-based control significantly enhances precision, reliability, and usability in ESD surgical training scenarios.
TRUST-VL: An Explainable News Assistant for General Multimodal Misinformation Detection
Sep 04, 2025Multimodal misinformation, encompassing textual, visual, and cross-modal distortions, poses an increasing societal threat that is amplified by generative AI. Existing methods typically focus on a single type of distortion and struggle to generalize to unseen scenarios. In this work, we observe that different distortion types share common reasoning capabilities while also requiring task-specific skills. We hypothesize that joint training across distortion types facilitates knowledge sharing and enhances the model's ability to generalize. To this end, we introduce TRUST-VL, a unified and explainable vision-language model for general multimodal misinformation detection. TRUST-VL incorporates a novel Question-Aware Visual Amplifier module, designed to extract task-specific visual features. To support training, we also construct TRUST-Instruct, a large-scale instruction dataset containing 198K samples featuring structured reasoning chains aligned with human fact-checking workflows. Extensive experiments on both in-domain and zero-shot benchmarks demonstrate that TRUST-VL achieves state-of-the-art performance, while also offering strong generalization and interpretability.
A Novel Coronary Artery Registration Method Based on Super-pixel Particle Swarm Optimization
May 30, 2025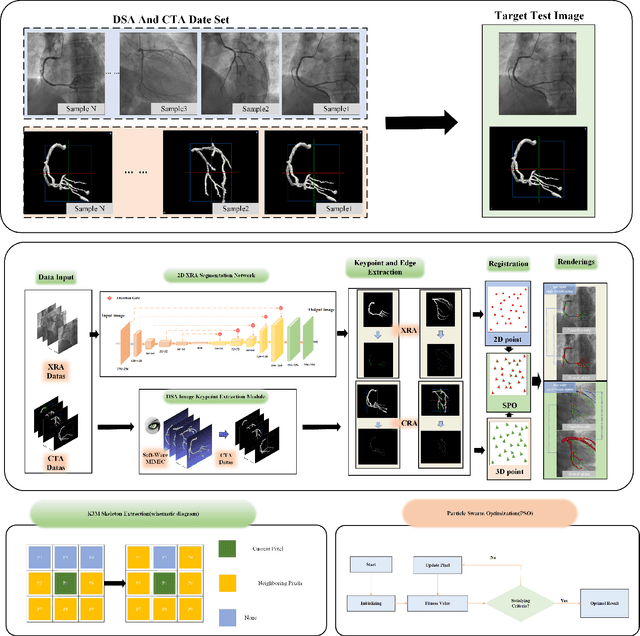
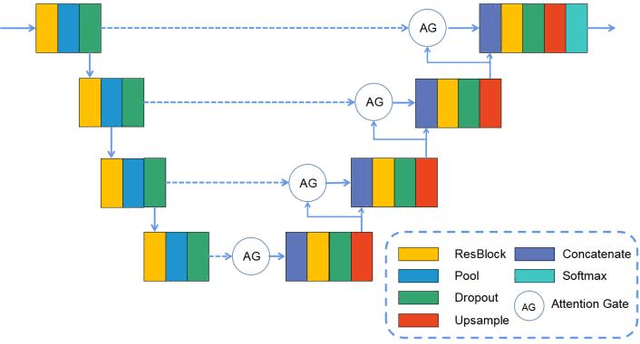
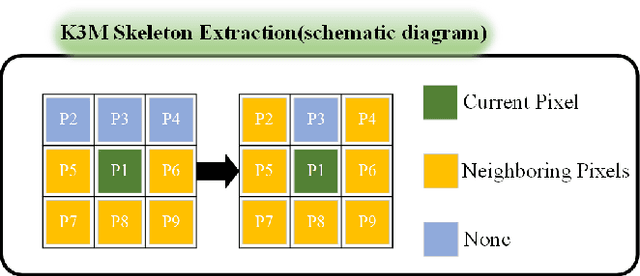
Percutaneous Coronary Intervention (PCI) is a minimally invasive procedure that improves coronary blood flow and treats coronary artery disease. Although PCI typically requires 2D X-ray angiography (XRA) to guide catheter placement at real-time, computed tomography angiography (CTA) may substantially improve PCI by providing precise information of 3D vascular anatomy and status. To leverage real-time XRA and detailed 3D CTA anatomy for PCI, accurate multimodal image registration of XRA and CTA is required, to guide the procedure and avoid complications. This is a challenging process as it requires registration of images from different geometrical modalities (2D -> 3D and vice versa), with variations in contrast and noise levels. In this paper, we propose a novel multimodal coronary artery image registration method based on a swarm optimization algorithm, which effectively addresses challenges such as large deformations, low contrast, and noise across these imaging modalities. Our algorithm consists of two main modules: 1) preprocessing of XRA and CTA images separately, and 2) a registration module based on feature extraction using the Steger and Superpixel Particle Swarm Optimization algorithms. Our technique was evaluated on a pilot dataset of 28 pairs of XRA and CTA images from 10 patients who underwent PCI. The algorithm was compared with four state-of-the-art (SOTA) methods in terms of registration accuracy, robustness, and efficiency. Our method outperformed the selected SOTA baselines in all aspects. Experimental results demonstrate the significant effectiveness of our algorithm, surpassing the previous benchmarks and proposes a novel clinical approach that can potentially have merit for improving patient outcomes in coronary artery disease.
Advancing Embodied Intelligence in Robotic-Assisted Endovascular Procedures: A Systematic Review of AI Solutions
Apr 21, 2025Endovascular procedures have revolutionized the treatment of vascular diseases thanks to minimally invasive solutions that significantly reduce patient recovery time and enhance clinical outcomes. However, the precision and dexterity required during these procedures poses considerable challenges for interventionists. Robotic systems have emerged offering transformative solutions, addressing issues such as operator fatigue, radiation exposure, and the inherent limitations of human precision. The integration of Embodied Intelligence (EI) into these systems signifies a paradigm shift, enabling robots to navigate complex vascular networks and adapt to dynamic physiological conditions. Data-driven approaches, advanced computer vision, medical image analysis, and machine learning techniques, are at the forefront of this evolution. These methods augment procedural intelligence by facilitating real-time vessel segmentation, device tracking, and anatomical landmark detection. Reinforcement learning and imitation learning further refine navigation strategies and replicate experts' techniques. This review systematically examines the integration of EI principles into robotic technologies, in relation to endovascular procedures. We discuss recent advancements in intelligent perception and data-driven control, and their practical applications in robot-assisted endovascular procedures. By critically evaluating current limitations and emerging opportunities, this review establishes a framework for future developments, emphasizing the potential for greater autonomy and improved clinical outcomes. Emerging trends and specific areas of research, such as federated learning for medical data sharing, explainable AI for clinical decision support, and advanced human-robot collaboration paradigms, are also explored, offering insights into the future direction of this rapidly evolving field.
Ultrasound-Guided Robotic Blood Drawing and In Vivo Studies on Submillimetre Vessels of Rats
Apr 04, 2025Billions of vascular access procedures are performed annually worldwide, serving as a crucial first step in various clinical diagnostic and therapeutic procedures. For pediatric or elderly individuals, whose vessels are small in size (typically 2 to 3 mm in diameter for adults and less than 1 mm in children), vascular access can be highly challenging. This study presents an image-guided robotic system aimed at enhancing the accuracy of difficult vascular access procedures. The system integrates a 6-DoF robotic arm with a 3-DoF end-effector, ensuring precise navigation and needle insertion. Multi-modal imaging and sensing technologies have been utilized to endow the medical robot with precision and safety, while ultrasound imaging guidance is specifically evaluated in this study. To evaluate in vivo vascular access in submillimeter vessels, we conducted ultrasound-guided robotic blood drawing on the tail veins (with a diameter of 0.7 plus or minus 0.2 mm) of 40 rats. The results demonstrate that the system achieved a first-attempt success rate of 95 percent. The high first-attempt success rate in intravenous vascular access, even with small blood vessels, demonstrates the system's effectiveness in performing these procedures. This capability reduces the risk of failed attempts, minimizes patient discomfort, and enhances clinical efficiency.
Sim4EndoR: A Reinforcement Learning Centered Simulation Platform for Task Automation of Endovascular Robotics
Apr 04, 2025Robotic-assisted percutaneous coronary intervention (PCI) holds considerable promise for elevating precision and safety in cardiovascular procedures. Nevertheless, current systems heavily depend on human operators, resulting in variability and the potential for human error. To tackle these challenges, Sim4EndoR, an innovative reinforcement learning (RL) based simulation environment, is first introduced to bolster task-level autonomy in PCI. This platform offers a comprehensive and risk-free environment for the development, evaluation, and refinement of potential autonomous systems, enhancing data collection efficiency and minimizing the need for costly hardware trials. A notable aspect of the groundbreaking Sim4EndoR is its reward function, which takes into account the anatomical constraints of the vascular environment, utilizing the geometric characteristics of vessels to steer the learning process. By seamlessly integrating advanced physical simulations with neural network-driven policy learning, Sim4EndoR fosters efficient sim-to-real translation, paving the way for safer, more consistent robotic interventions in clinical practice, ultimately improving patient outcomes.
Mitigating GenAI-powered Evidence Pollution for Out-of-Context Multimodal Misinformation Detection
Jan 24, 2025While large generative artificial intelligence (GenAI) models have achieved significant success, they also raise growing concerns about online information security due to their potential misuse for generating deceptive content. Out-of-context (OOC) multimodal misinformation detection, which often retrieves Web evidence to identify the repurposing of images in false contexts, faces the issue of reasoning over GenAI-polluted evidence to derive accurate predictions. Existing works simulate GenAI-powered pollution at the claim level with stylistic rewriting to conceal linguistic cues, and ignore evidence-level pollution for such information-seeking applications. In this work, we investigate how polluted evidence affects the performance of existing OOC detectors, revealing a performance degradation of more than 9 percentage points. We propose two strategies, cross-modal evidence reranking and cross-modal claim-evidence reasoning, to address the challenges posed by polluted evidence. Extensive experiments on two benchmark datasets show that these strategies can effectively enhance the robustness of existing out-of-context detectors amidst polluted evidence.