 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingMOS-Pro: An Comprehensive Benchmark for Singing Quality Assessment
Oct 02, 2025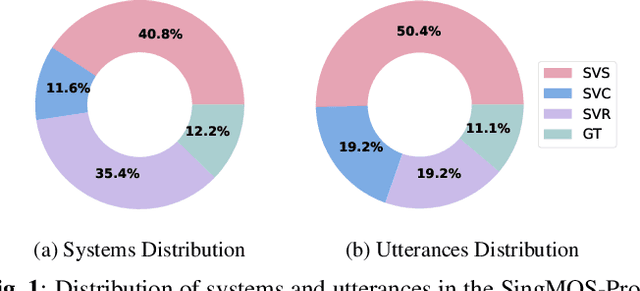

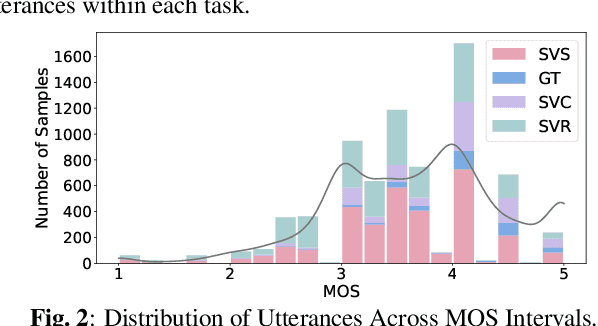

Singing voice generation progresses rapidly, yet evaluating singing quality remains a critical challenge. Human subjective assessment, typically in the form of listening tests, is costly and time consuming, while existing objective metrics capture only limited perceptual aspects. In this work, we introduce SingMOS-Pro, a dataset for automatic singing quality assessment. Building on our preview version SingMOS, which provides only overall ratings, SingMOS-Pro expands annotations of the additional part to include lyrics, melody, and overall quality, offering broader coverage and greater diversity. The dataset contains 7,981 singing clips generated by 41 models across 12 datasets, spanning from early systems to recent advances. Each clip receives at least five ratings from professional annotators, ensuring reliability and consistency. Furthermore, we explore how to effectively utilize MOS data annotated under different standards and benchmark several widely used evaluation methods from related tasks on SingMOS-Pro, establishing strong baselines and practical references for future research. The dataset can be accessed at https://huggingface.co/datasets/TangRain/SingMOS-Pro.
RAG-QA Arena: Evaluating Domain Robustness for Long-form Retrieval Augmented Question Answering
Jul 19, 2024Question answering based on retrieval augmented generation (RAG-QA) is an important research topic in NLP and has a wide range of real-world applications. However, most existing datasets for this task are either constructed using a single source corpus or consist of short extractive answers, which fall short of evaluating large language model (LLM) based RAG-QA systems on cross-domain generalization. To address these limitations, we create Long-form RobustQA (LFRQA), a new dataset comprising human-written long-form answers that integrate short extractive answers from multiple documents into a single, coherent narrative, covering 26K queries and large corpora across seven different domains. We further propose RAG-QA Arena by directly comparing model-generated answers against LFRQA's answers using LLMs as evaluators. We show via extensive experiments that RAG-QA Arena and human judgments on answer quality are highly correlated. Moreover, only 41.3% of the most competitive LLM's answers are preferred to LFRQA's answers, demonstrating RAG-QA Arena as a challenging evaluation platform for future research.
Tokenization Consistency Matters for Generative Models on Extractive NLP Tasks
Dec 19, 2022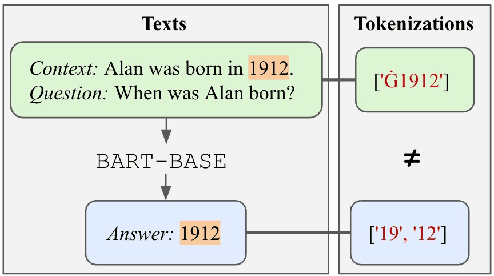
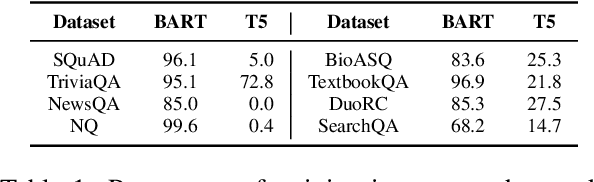
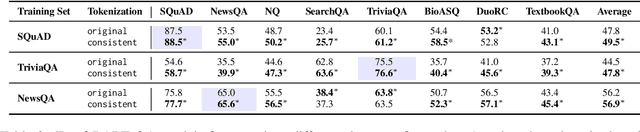
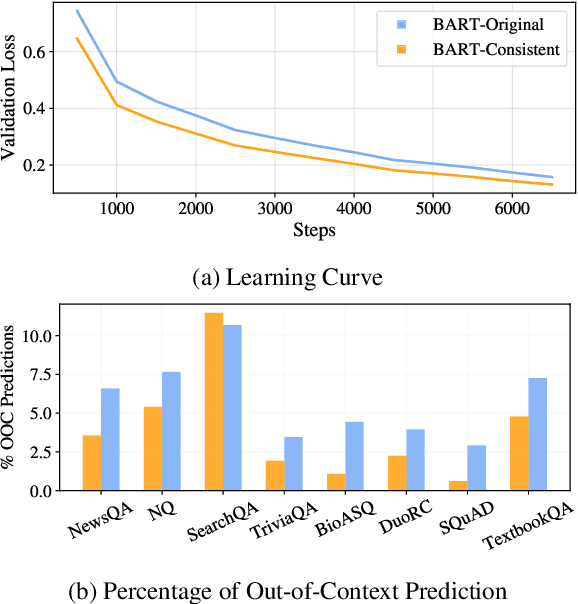
Generative models have been widely applied to solve extractive tasks, where parts of the input is extracted to form the desired output, and achieved significant success. For example, in extractive question answering (QA), generative models have constantly yielded state-of-the-art results. In this work, we identify the issue of tokenization inconsistency that is commonly neglected in training these models. This issue damages the extractive nature of these tasks after the input and output are tokenized inconsistently by the tokenizer, and thus leads to performance drop as well as hallucination. We propose a simple yet effective fix to this issue and conduct a case study on extractive QA. We show that, with consistent tokenization, the model performs better in both in-domain and out-of-domain datasets, with a notable average of +1.7 F2 gain when a BART model is trained on SQuAD and evaluated on 8 QA datasets. Further, the model converges faster, and becomes less likely to generate out-of-context answers. With these findings, we would like to call for more attention on how tokenization should be done when solving extractive tasks and recommend applying consistent tokenization during training.
Improving Cross-task Generalization of Unified Table-to-text Models with Compositional Task Configurations
Dec 17, 2022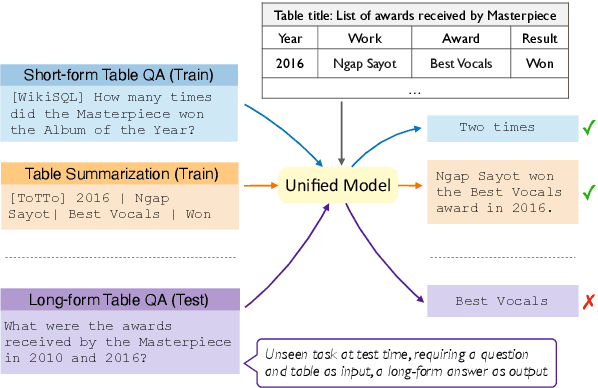
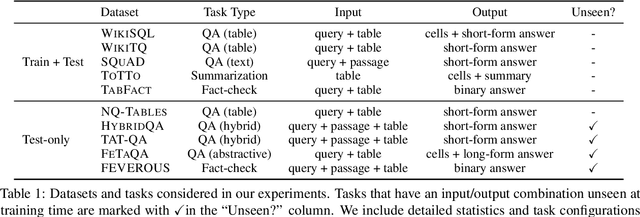
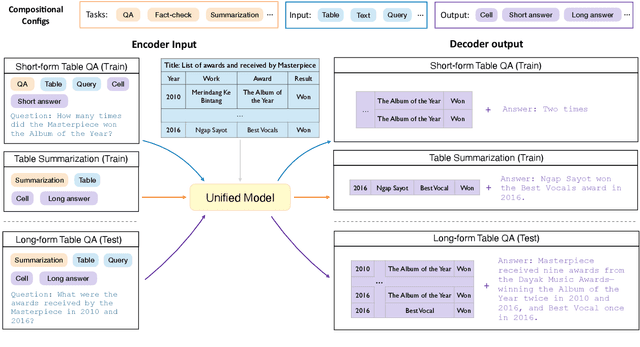

There has been great progress in unifying various table-to-text tasks using a single encoder-decoder model trained via multi-task learning (Xie et al., 2022). However, existing methods typically encode task information with a simple dataset name as a prefix to the encoder. This not only limits the effectiveness of multi-task learning, but also hinders the model's ability to generalize to new domains or tasks that were not seen during training, which is crucial for real-world applications. In this paper, we propose compositional task configurations, a set of prompts prepended to the encoder to improve cross-task generalization of unified models. We design the task configurations to explicitly specify the task type, as well as its input and output types. We show that this not only allows the model to better learn shared knowledge across different tasks at training, but also allows us to control the model by composing new configurations that apply novel input-output combinations in a zero-shot manner. We demonstrate via experiments over ten table-to-text tasks that our method outperforms the UnifiedSKG baseline by noticeable margins in both in-domain and zero-shot settings, with average improvements of +0.5 and +12.6 from using a T5-large backbone, respectively.