 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELEC: Efficient Large Language Model-Empowered Click-Through Rate Prediction
Sep 09, 2025Click-through rate (CTR) prediction plays an important role in online advertising systems. On the one hand, traditional CTR prediction models capture the collaborative signals in tabular data via feature interaction modeling, but they lose semantics in text. On the other hand, Large Language Models (LLMs) excel in understanding the context and meaning behind text, but they face challenges in capturing collaborative signals and they have long inference latency. In this paper, we aim to leverage the benefits of both types of models and pursue collaboration, semantics and efficiency. We present ELEC, which is an Efficient LLM-Empowered CTR prediction framework. We first adapt an LLM for the CTR prediction task. In order to leverage the ability of the LLM but simultaneously keep efficiency, we utilize the pseudo-siamese network which contains a gain network and a vanilla network. We inject the high-level representation vector generated by the LLM into a collaborative CTR model to form the gain network such that it can take advantage of both tabular modeling and textual modeling. However, its reliance on the LLM limits its efficiency. We then distill the knowledge from the gain network to the vanilla network on both the score level and the representation level, such that the vanilla network takes only tabular data as input, but can still generate comparable performance as the gain network. Our approach is model-agnostic. It allows for the integration with various existing LLMs and collaborative CTR models. Experiments on real-world datasets demonstrate the effectiveness and efficiency of ELEC for CTR prediction.
FedUD: Exploiting Unaligned Data for Cross-Platform Federated Click-Through Rate Prediction
Jul 26, 2024



Click-through rate (CTR) prediction plays an important role in online advertising platforms. Most existing methods use data from the advertising platform itself for CTR prediction. As user behaviors also exist on many other platforms, e.g., media platforms, it is beneficial to further exploit such complementary information for better modeling user interest and for improving CTR prediction performance. However, due to privacy concerns, data from different platforms cannot be uploaded to a server for centralized model training. Vertical federated learning (VFL) provides a possible solution which is able to keep the raw data on respective participating parties and learn a collaborative model in a privacy-preserving way. However, traditional VFL methods only utilize aligned data with common keys across parties, which strongly restricts their application scope. In this paper, we propose FedUD, which is able to exploit unaligned data, in addition to aligned data, for more accurate federated CTR prediction. FedUD contains two steps. In the first step, FedUD utilizes aligned data across parties like traditional VFL, but it additionally includes a knowledge distillation module. This module distills useful knowledge from the guest party's high-level representations and guides the learning of a representation transfer network. In the second step, FedUD applies the learned knowledge to enrich the representations of the host party's unaligned data such that both aligned and unaligned data can contribute to federated model training. Experiments on two real-world datasets demonstrate the superior performance of FedUD for federated CTR prediction.
Linguistics from a topological viewpoint
Mar 16, 2024


Typological databases in linguistics are usually categorical-valued. As a result, it is difficult to have a clear visualization of the data. In this paper, we describe a workflow to analyze the topological shapes of South American languages by applying multiple correspondence analysis technique and topological data analysis methods.
Efficient Bottom-Up Synthesis for Programs with Local Variables
Nov 07, 2023

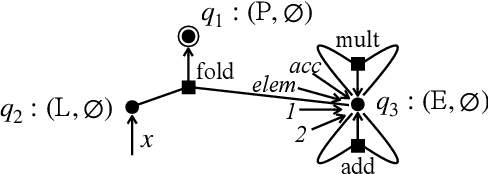
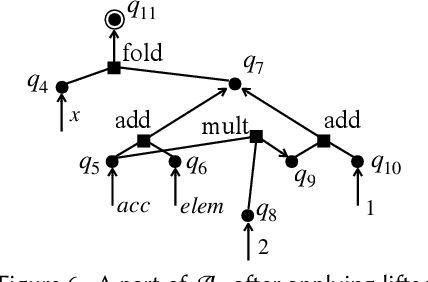
We propose a new synthesis algorithm that can efficiently search programs with local variables (e.g., those introduced by lambdas). Prior bottom-up synthesis algorithms are not able to evaluate programs with free local variables, and therefore cannot effectively reduce the search space of such programs (e.g., using standard observational equivalence reduction techniques), making synthesis slow. Our algorithm can reduce the space of programs with local variables. The key idea, dubbed lifted interpretation, is to lift up the program interpretation process, from evaluating one program at a time to simultaneously evaluating all programs from a grammar. Lifted interpretation provides a mechanism to systematically enumerate all binding contexts for local variables, thereby enabling us to evaluate and reduce the space of programs with local variables. Our ideas are instantiated in the domain of web automation. The resulting tool, Arborist, can automate a significantly broader range of challenging tasks more efficiently than state-of-the-art techniques including WebRobot and Helena.
DiLogics: Creating Web Automation Programs With Diverse Logics
Aug 18, 2023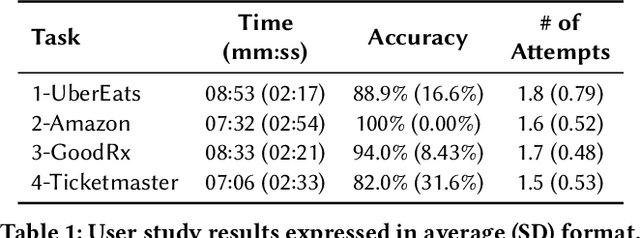
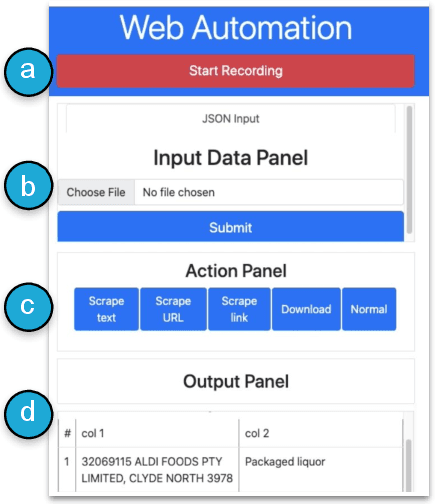
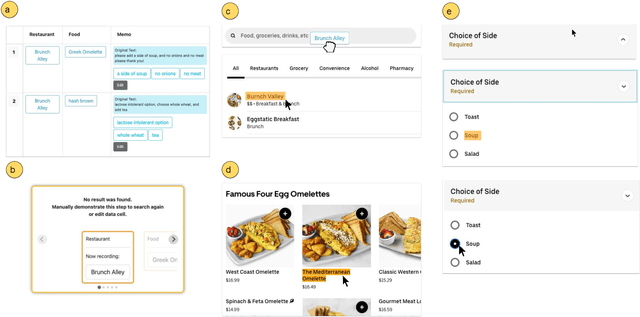
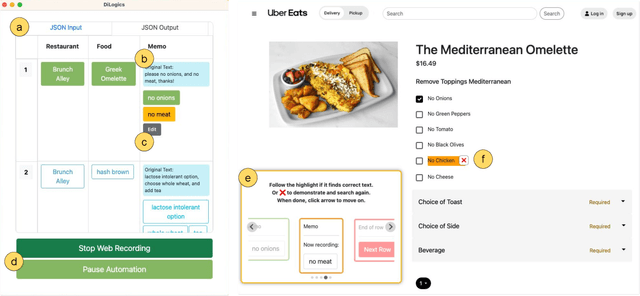
Knowledge workers frequently encounter repetitive web data entry tasks, like updating records or placing orders. Web automation increases productivity, but translating tasks to web actions accurately and extending to new specifications is challenging. Existing tools can automate tasks that perform the same logical trace of UI actions (e.g., input text in each field in order), but do not support tasks requiring different executions based on varied input conditions. We present DiLogics, a programming-by-demonstration system that utilizes NLP to assist users in creating web automation programs that handle diverse specifications. DiLogics first semantically segments input data to structured task steps. By recording user demonstrations for each step, DiLogics generalizes the web macros to novel but semantically similar task requirements. Our evaluation showed that non-experts can effectively use DiLogics to create automation programs that fulfill diverse input instructions. DiLogics provides an efficient, intuitive, and expressive method for developing web automation programs satisfying diverse specifications.
Contrastive Learning for Conversion Rate Prediction
Jul 12, 2023



Conversion rate (CVR) prediction plays an important role in advertising systems. Recently, supervised deep neural network-based models have shown promising performance in CVR prediction. However, they are data hungry and require an enormous amount of training data. In online advertising systems, although there are millions to billions of ads, users tend to click only a small set of them and to convert on an even smaller set. This data sparsity issue restricts the power of these deep models. In this paper, we propose the Contrastive Learning for CVR prediction (CL4CVR) framework. It associates the supervised CVR prediction task with a contrastive learning task, which can learn better data representations exploiting abundant unlabeled data and improve the CVR prediction performance. To tailor the contrastive learning task to the CVR prediction problem, we propose embedding masking (EM), rather than feature masking, to create two views of augmented samples. We also propose a false negative elimination (FNE) component to eliminate samples with the same feature as the anchor sample, to account for the natural property in user behavior data. We further propose a supervised positive inclusion (SPI) component to include additional positive samples for each anchor sample, in order to make full use of sparse but precious user conversion events. Experimental results on two real-world conversion datasets demonstrate the superior performance of CL4CVR. The source code is available at https://github.com/DongRuiHust/CL4CVR.
STREET: A Multi-Task Structured Reasoning and Explanation Benchmark
Feb 13, 2023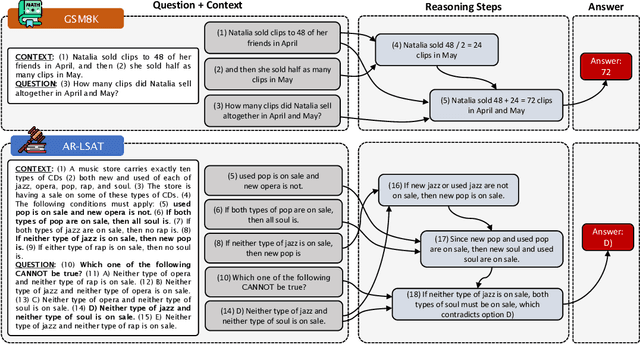
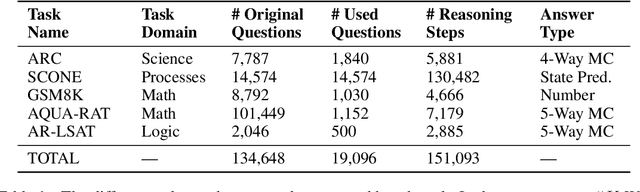
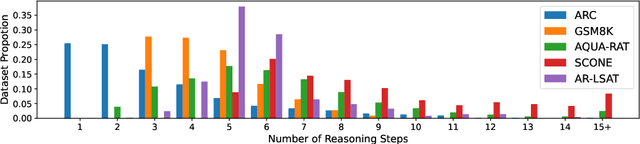
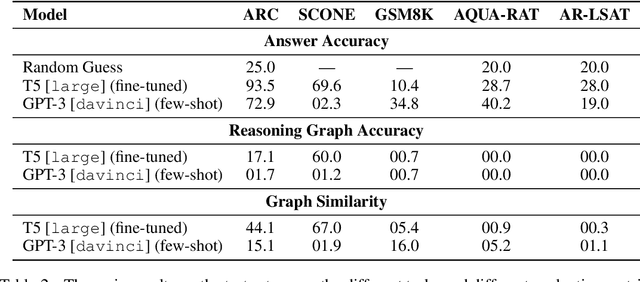
We introduce STREET, a unified multi-task and multi-domain natural language reasoning and explanation benchmark. Unlike most existing question-answering (QA) datasets, we expect models to not only answer questions, but also produce step-by-step structured explanations describing how premises in the question are used to produce intermediate conclusions that can prove the correctness of a certain answer. We perform extensive evaluation with popular language models such as few-shot prompting GPT-3 and fine-tuned T5. We find that these models still lag behind human performance when producing such structured reasoning steps. We believe this work will provide a way for the community to better train and test systems on multi-step reasoning and explanations in natural language.
Improving Cross-task Generalization of Unified Table-to-text Models with Compositional Task Configurations
Dec 17, 2022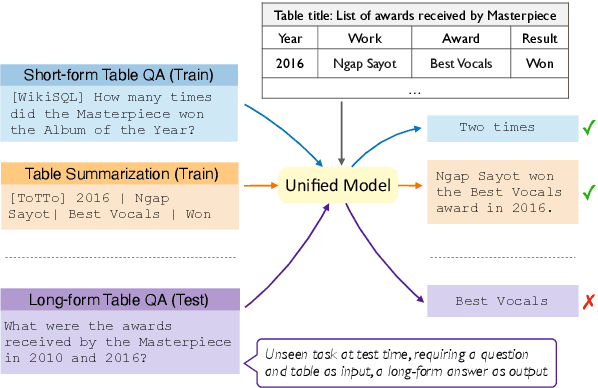
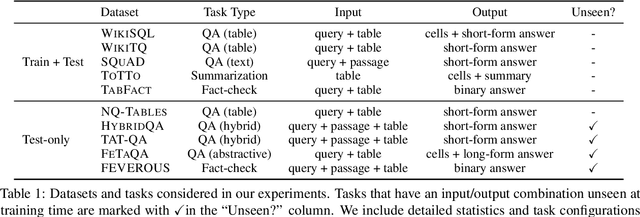
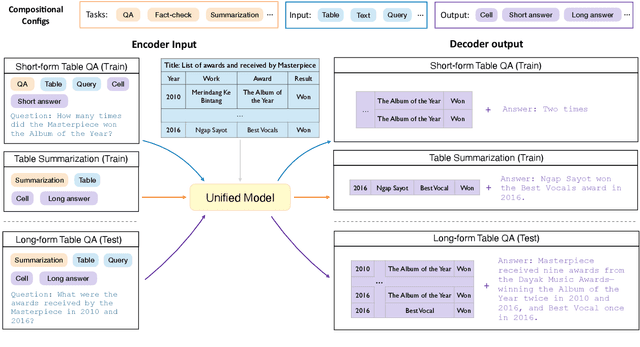

There has been great progress in unifying various table-to-text tasks using a single encoder-decoder model trained via multi-task learning (Xie et al., 2022). However, existing methods typically encode task information with a simple dataset name as a prefix to the encoder. This not only limits the effectiveness of multi-task learning, but also hinders the model's ability to generalize to new domains or tasks that were not seen during training, which is crucial for real-world applications. In this paper, we propose compositional task configurations, a set of prompts prepended to the encoder to improve cross-task generalization of unified models. We design the task configurations to explicitly specify the task type, as well as its input and output types. We show that this not only allows the model to better learn shared knowledge across different tasks at training, but also allows us to control the model by composing new configurations that apply novel input-output combinations in a zero-shot manner. We demonstrate via experiments over ten table-to-text tasks that our method outperforms the UnifiedSKG baseline by noticeable margins in both in-domain and zero-shot settings, with average improvements of +0.5 and +12.6 from using a T5-large backbone, respectively.
Entailment Tree Explanations via Iterative Retrieval-Generation Reasoner
May 18, 2022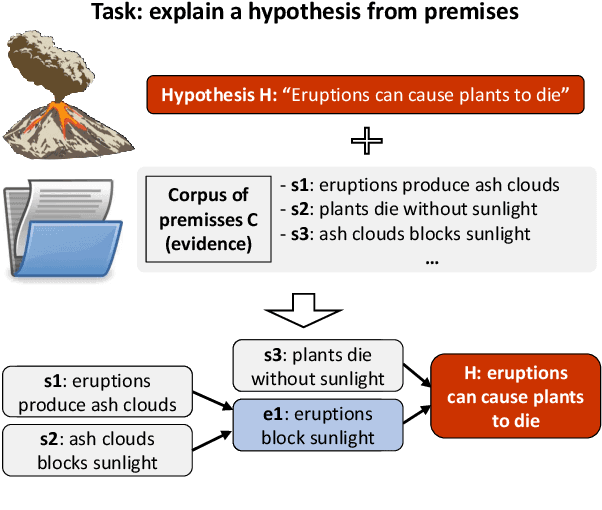
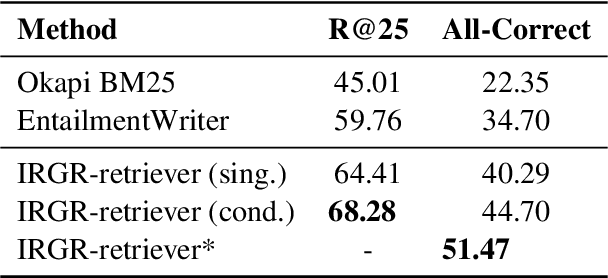
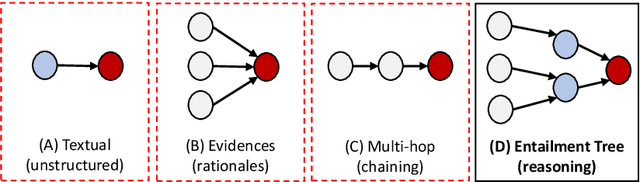
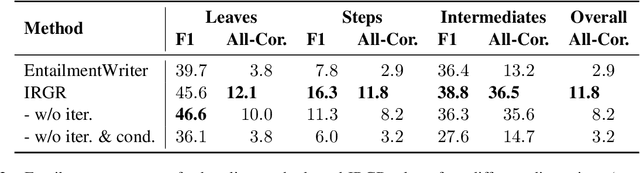
Large language models have achieved high performance on various question answering (QA) benchmarks, but the explainability of their output remains elusive. Structured explanations, called entailment trees, were recently suggested as a way to explain and inspect a QA system's answer. In order to better generate such entailment trees, we propose an architecture called Iterative Retrieval-Generation Reasoner (IRGR). Our model is able to explain a given hypothesis by systematically generating a step-by-step explanation from textual premises. The IRGR model iteratively searches for suitable premises, constructing a single entailment step at a time. Contrary to previous approaches, our method combines generation steps and retrieval of premises, allowing the model to leverage intermediate conclusions, and mitigating the input size limit of baseline encoder-decoder models. We conduct experiments using the EntailmentBank dataset, where we outperform existing benchmarks on premise retrieval and entailment tree generation, with around 300% gain in overall correctness.
Deep Learning for Radio Resource Allocation with Diverse Quality-of-Service Requirements in 5G
Mar 29, 2020
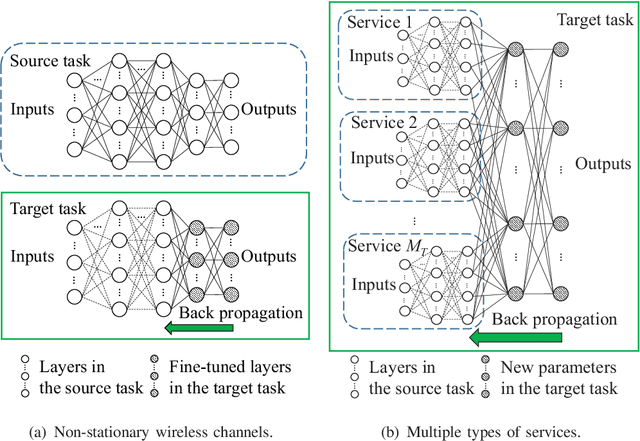


To accommodate diverse Quality-of-Service (QoS) requirements in the 5th generation cellular networks, base stations need real-time optimization of radio resources in time-varying network conditions. This brings high computing overheads and long processing delays. In this work, we develop a deep learning framework to approximate the optimal resource allocation policy that minimizes the total power consumption of a base station by optimizing bandwidth and transmit power allocation. We find that a fully-connected neural network (NN) cannot fully guarantee the QoS requirements due to the approximation errors and quantization errors of the numbers of subcarriers. To tackle this problem, we propose a cascaded structure of NNs, where the first NN approximates the optimal bandwidth allocation, and the second NN outputs the transmit power required to satisfy the QoS requirement with given bandwidth allocation. Considering that the distribution of wireless channels and the types of services in the wireless networks are non-stationary, we apply deep transfer learning to update NNs in non-stationary wireless networks. Simulation results validate that the cascaded NNs outperform the fully connected NN in terms of QoS guarantee. In addition, deep transfer learning can reduce the number of training samples required to train the NNs remarkably.