 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalkGPT: Grounded Vision-Language Conversation with Depth-Aware Segmentation for Pedestrian Navigation
Mar 11, 2026Ensuring accessible pedestrian navigation requires reasoning about both semantic and spatial aspects of complex urban scenes, a challenge that existing Large Vision-Language Models (LVLMs) struggle to meet. Although these models can describe visual content, their lack of explicit grounding leads to object hallucinations and unreliable depth reasoning, limiting their usefulness for accessibility guidance. We introduce WalkGPT, a pixel-grounded LVLM for the new task of Grounded Navigation Guide, unifying language reasoning and segmentation within a single architecture for depth-aware accessibility guidance. Given a pedestrian-view image and a navigation query, WalkGPT generates a conversational response with segmentation masks that delineate accessible and harmful features, along with relative depth estimation. The model incorporates a Multi-Scale Query Projector (MSQP) that shapes the final image tokens by aggregating them along text tokens across spatial hierarchies, and a Calibrated Text Projector (CTP), guided by a proposed Region Alignment Loss, that maps language embeddings into segmentation-aware representations. These components enable fine-grained grounding and depth inference without user-provided cues or anchor points, allowing the model to generate complete and realistic navigation guidance. We also introduce PAVE, a large-scale benchmark of 41k pedestrian-view images paired with accessibility-aware questions and depth-grounded answers. Experiments show that WalkGPT achieves strong grounded reasoning and segmentation performance. The source code and dataset are available on the \href{https://sites.google.com/view/walkgpt-26/home}{project website}.
Attention Smoothing Is All You Need For Unlearning
Mar 01, 2026Large Language Models are prone to memorizing sensitive, copyrighted, or hazardous content, posing significant privacy and legal concerns. Retraining from scratch is computationally infeasible, whereas current unlearning methods exhibit unstable trade-offs between forgetting and utility, frequently producing incoherent outputs on forget prompts and failing to generalize due to the persistence of lexical-level and semantic-level associations in attention. We propose Attention Smoothing Unlearning (ASU), a principled framework that casts unlearning as self-distillation from a forget-teacher derived from the model's own attention. By increasing the softmax temperature, ASU flattens attention distributions and directly suppresses the lexical-level and semantic-level associations responsible for reconstructing memorized knowledge. This results in a bounded optimization objective that erases factual information yet maintains coherence in responses to forget prompts. Empirical evaluation on TOFU, MUSE, and WMDP, along with real-world and continual unlearning scenarios across question answering and text completion, demonstrates that ASU outperforms the baselines for most unlearning scenarios, delivering robust unlearning with minimal loss of model utility.
Owen-based Semantics and Hierarchy-Aware Explanation (O-Shap)
Feb 19, 2026Shapley value-based methods have become foundational in explainable artificial intelligence (XAI), offering theoretically grounded feature attributions through cooperative game theory. However, in practice, particularly in vision tasks, the assumption of feature independence breaks down, as features (i.e., pixels) often exhibit strong spatial and semantic dependencies. To address this, modern SHAP implementations now include the Owen value, a hierarchical generalization of the Shapley value that supports group attributions. While the Owen value preserves the foundations of Shapley values, its effectiveness critically depends on how feature groups are defined. We show that commonly used segmentations (e.g., axis-aligned or SLIC) violate key consistency properties, and propose a new segmentation approach that satisfies the $T$-property to ensure semantic alignment across hierarchy levels. This hierarchy enables computational pruning while improving attribution accuracy and interpretability. Experiments on image and tabular datasets demonstrate that O-Shap outperforms baseline SHAP variants in attribution precision, semantic coherence, and runtime efficiency, especially when structure matters.
Attention Retention for Continual Learning with Vision Transformers
Feb 05, 2026Continual learning (CL) empowers AI systems to progressively acquire knowledge from non-stationary data streams. However, catastrophic forgetting remains a critical challenge. In this work, we identify attention drift in Vision Transformers as a primary source of catastrophic forgetting, where the attention to previously learned visual concepts shifts significantly after learning new tasks. Inspired by neuroscientific insights into the selective attention in the human visual system, we propose a novel attention-retaining framework to mitigate forgetting in CL. Our method constrains attention drift by explicitly modifying gradients during backpropagation through a two-step process: 1) extracting attention maps of the previous task using a layer-wise rollout mechanism and generating instance-adaptive binary masks, and 2) when learning a new task, applying these masks to zero out gradients associated with previous attention regions, thereby preventing disruption of learned visual concepts. For compatibility with modern optimizers, the gradient masking process is further enhanced by scaling parameter updates proportionally to maintain their relative magnitudes. Experiments and visualizations demonstrate the effectiveness of our method in mitigating catastrophic forgetting and preserving visual concepts. It achieves state-of-the-art performance and exhibits robust generalizability across diverse CL scenarios.
Automatic Calibration for Membership Inference Attack on Large Language Models
May 06, 2025



Membership Inference Attacks (MIAs) have recently been employed to determine whether a specific text was part of the pre-training data of Large Language Models (LLMs). However, existing methods often misinfer non-members as members, leading to a high false positive rate, or depend on additional reference models for probability calibration, which limits their practicality. To overcome these challenges, we introduce a novel framework called Automatic Calibration Membership Inference Attack (ACMIA), which utilizes a tunable temperature to calibrate output probabilities effectively. This approach is inspired by our theoretical insights into maximum likelihood estimation during the pre-training of LLMs. We introduce ACMIA in three configurations designed to accommodate different levels of model access and increase the probability gap between members and non-members, improving the reliability and robustness of membership inference. Extensive experiments on various open-source LLMs demonstrate that our proposed attack is highly effective, robust, and generalizable, surpassing state-of-the-art baselines across three widely used benchmarks. Our code is available at: \href{https://github.com/Salehzz/ACMIA}{\textcolor{blue}{Github}}.
Exploring The Neural Burden In Pruned Models: An Insight Inspired By Neuroscience
Jul 27, 2024Vision Transformer and its variants have been adopted in many visual tasks due to their powerful capabilities, which also bring significant challenges in computation and storage. Consequently, researchers have introduced various compression methods in recent years, among which the pruning techniques are widely used to remove a significant fraction of the network. Therefore, these methods can reduce significant percent of the FLOPs, but often lead to a decrease in model performance. To investigate the underlying causes, we focus on the pruning methods specifically belonging to the pruning-during-training category, then drew inspiration from neuroscience and propose a new concept for artificial neural network models named Neural Burden. We investigate its impact in the model pruning process, and subsequently explore a simple yet effective approach to mitigate the decline in model performance, which can be applied to any pruning-during-training technique. Extensive experiments indicate that the neural burden phenomenon indeed exists, and show the potential of our method. We hope that our findings can provide valuable insights for future research. Code will be made publicly available after this paper is published.
Learning to Poison Large Language Models During Instruction Tuning
Feb 21, 2024



The advent of Large Language Models (LLMs) has marked significant achievements in language processing and reasoning capabilities. Despite their advancements, LLMs face vulnerabilities to data poisoning attacks, where adversaries insert backdoor triggers into training data to manipulate outputs for malicious purposes. This work further identifies additional security risks in LLMs by designing a new data poisoning attack tailored to exploit the instruction tuning process. We propose a novel gradient-guided backdoor trigger learning approach to identify adversarial triggers efficiently, ensuring an evasion of detection by conventional defenses while maintaining content integrity. Through experimental validation across various LLMs and tasks, our strategy demonstrates a high success rate in compromising model outputs; poisoning only 1\% of 4,000 instruction tuning samples leads to a Performance Drop Rate (PDR) of around 80\%. Our work highlights the need for stronger defenses against data poisoning attack, offering insights into safeguarding LLMs against these more sophisticated attacks. The source code can be found on this GitHub repository: https://github.com/RookieZxy/GBTL/blob/main/README.md.
Hijacking Large Language Models via Adversarial In-Context Learning
Nov 16, 2023



In-context learning (ICL) has emerged as a powerful paradigm leveraging LLMs for specific tasks by utilizing labeled examples as demonstrations in the precondition prompts. Despite its promising performance, ICL suffers from instability with the choice and arrangement of examples. Additionally, crafted adversarial attacks pose a notable threat to the robustness of ICL. However, existing attacks are either easy to detect, rely on external models, or lack specificity towards ICL. To address these issues, this work introduces a novel transferable attack for ICL, aiming to hijack LLMs to generate the targeted response. The proposed LLM hijacking attack leverages a gradient-based prompt search method to learn and append imperceptible adversarial suffixes to the in-context demonstrations. Extensive experimental results on various tasks and datasets demonstrate the effectiveness of our LLM hijacking attack, resulting in a distracted attention towards adversarial tokens, consequently leading to the targeted unwanted outputs.
Efficient Bottom-Up Synthesis for Programs with Local Variables
Nov 07, 2023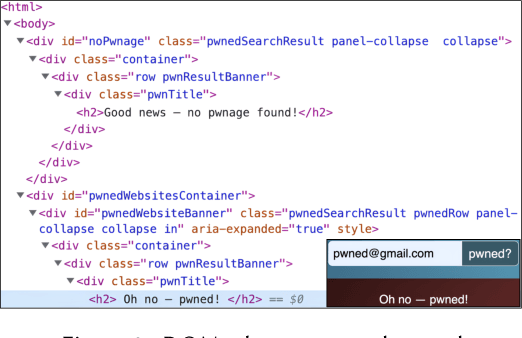

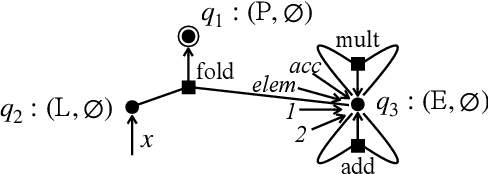
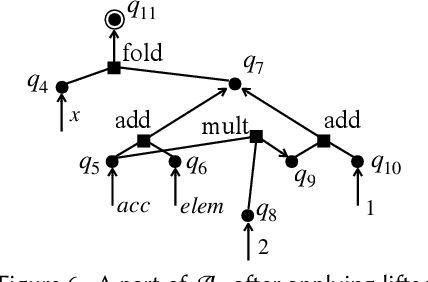
We propose a new synthesis algorithm that can efficiently search programs with local variables (e.g., those introduced by lambdas). Prior bottom-up synthesis algorithms are not able to evaluate programs with free local variables, and therefore cannot effectively reduce the search space of such programs (e.g., using standard observational equivalence reduction techniques), making synthesis slow. Our algorithm can reduce the space of programs with local variables. The key idea, dubbed lifted interpretation, is to lift up the program interpretation process, from evaluating one program at a time to simultaneously evaluating all programs from a grammar. Lifted interpretation provides a mechanism to systematically enumerate all binding contexts for local variables, thereby enabling us to evaluate and reduce the space of programs with local variables. Our ideas are instantiated in the domain of web automation. The resulting tool, Arborist, can automate a significantly broader range of challenging tasks more efficiently than state-of-the-art techniques including WebRobot and Helena.
DGP-Net: Dense Graph Prototype Network for Few-Shot SAR Target Recognition
Feb 19, 2023



The inevitable feature deviation of synthetic aperture radar (SAR) image due to the special imaging principle (depression angle variation) leads to poor recognition accuracy, especially in few-shot learning (FSL). To deal with this problem, we propose a dense graph prototype network (DGP-Net) to eliminate the feature deviation by learning potential features, and classify by learning feature distribution. The role of the prototype in this model is to solve the problem of large distance between congeneric samples taken due to the contingency of single sampling in FSL, and enhance the robustness of the model. Experimental results on the MSTAR dataset show that the DGP-Net has good classification results for SAR images with different depression angles and the recognition accuracy of it is higher than typical FSL methods.