 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalkGPT: Grounded Vision-Language Conversation with Depth-Aware Segmentation for Pedestrian Navigation
Mar 11, 2026Ensuring accessible pedestrian navigation requires reasoning about both semantic and spatial aspects of complex urban scenes, a challenge that existing Large Vision-Language Models (LVLMs) struggle to meet. Although these models can describe visual content, their lack of explicit grounding leads to object hallucinations and unreliable depth reasoning, limiting their usefulness for accessibility guidance. We introduce WalkGPT, a pixel-grounded LVLM for the new task of Grounded Navigation Guide, unifying language reasoning and segmentation within a single architecture for depth-aware accessibility guidance. Given a pedestrian-view image and a navigation query, WalkGPT generates a conversational response with segmentation masks that delineate accessible and harmful features, along with relative depth estimation. The model incorporates a Multi-Scale Query Projector (MSQP) that shapes the final image tokens by aggregating them along text tokens across spatial hierarchies, and a Calibrated Text Projector (CTP), guided by a proposed Region Alignment Loss, that maps language embeddings into segmentation-aware representations. These components enable fine-grained grounding and depth inference without user-provided cues or anchor points, allowing the model to generate complete and realistic navigation guidance. We also introduce PAVE, a large-scale benchmark of 41k pedestrian-view images paired with accessibility-aware questions and depth-grounded answers. Experiments show that WalkGPT achieves strong grounded reasoning and segmentation performance. The source code and dataset are available on the \href{https://sites.google.com/view/walkgpt-26/home}{project website}.
Attention Smoothing Is All You Need For Unlearning
Mar 01, 2026Large Language Models are prone to memorizing sensitive, copyrighted, or hazardous content, posing significant privacy and legal concerns. Retraining from scratch is computationally infeasible, whereas current unlearning methods exhibit unstable trade-offs between forgetting and utility, frequently producing incoherent outputs on forget prompts and failing to generalize due to the persistence of lexical-level and semantic-level associations in attention. We propose Attention Smoothing Unlearning (ASU), a principled framework that casts unlearning as self-distillation from a forget-teacher derived from the model's own attention. By increasing the softmax temperature, ASU flattens attention distributions and directly suppresses the lexical-level and semantic-level associations responsible for reconstructing memorized knowledge. This results in a bounded optimization objective that erases factual information yet maintains coherence in responses to forget prompts. Empirical evaluation on TOFU, MUSE, and WMDP, along with real-world and continual unlearning scenarios across question answering and text completion, demonstrates that ASU outperforms the baselines for most unlearning scenarios, delivering robust unlearning with minimal loss of model utility.
FluenceFormer: Transformer-Driven Multi-Beam Fluence Map Regression for Radiotherapy Planning
Dec 27, 2025Fluence map prediction is central to automated radiotherapy planning but remains an ill-posed inverse problem due to the complex relationship between volumetric anatomy and beam-intensity modulation. Convolutional methods in prior work often struggle to capture long-range dependencies, which can lead to structurally inconsistent or physically unrealizable plans. We introduce \textbf{FluenceFormer}, a backbone-agnostic transformer framework for direct, geometry-aware fluence regression. The model uses a unified two-stage design: Stage~1 predicts a global dose prior from anatomical inputs, and Stage~2 conditions this prior on explicit beam geometry to regress physically calibrated fluence maps. Central to the approach is the \textbf{Fluence-Aware Regression (FAR)} loss, a physics-informed objective that integrates voxel-level fidelity, gradient smoothness, structural consistency, and beam-wise energy conservation. We evaluate the generality of the framework across multiple transformer backbones, including Swin UNETR, UNETR, nnFormer, and MedFormer, using a prostate IMRT dataset. FluenceFormer with Swin UNETR achieves the strongest performance among the evaluated models and improves over existing benchmark CNN and single-stage methods, reducing Energy Error to $\mathbf{4.5\%}$ and yielding statistically significant gains in structural fidelity ($p < 0.05$).
Fluence Map Prediction with Deep Learning: A Transformer-based Approach
Nov 10, 2025Accurate fluence map prediction is essential in intensity-modulated radiation therapy (IMRT) to maximize tumor coverage while minimizing dose to healthy tissues. Conventional optimization is time-consuming and dependent on planner expertise. This study presents a deep learning framework that accelerates fluence map generation while maintaining clinical quality. An end-to-end 3D Swin-UNETR network was trained to predict nine-beam fluence maps directly from volumetric CT images and anatomical contours using 99 prostate IMRT cases (79 for training and 20 for testing). The transformer-based model employs hierarchical self-attention to capture both local anatomical structures and long-range spatial dependencies. Predicted fluence maps were imported into the Eclipse Treatment Planning System for dose recalculation, and model performance was evaluated using beam-wise fluence correlation, spatial gamma analysis, and dose-volume histogram (DVH) metrics. The proposed model achieved an average R^2 of 0.95 +/- 0.02, MAE of 0.035 +/- 0.008, and gamma passing rate of 85 +/- 10 percent (3 percent / 3 mm) on the test set, with no significant differences observed in DVH parameters between predicted and clinical plans. The Swin-UNETR framework enables fully automated, inverse-free fluence map prediction directly from anatomical inputs, enhancing spatial coherence, accuracy, and efficiency while offering a scalable and consistent solution for automated IMRT plan generation.
Automatic Calibration for Membership Inference Attack on Large Language Models
May 06, 2025



Membership Inference Attacks (MIAs) have recently been employed to determine whether a specific text was part of the pre-training data of Large Language Models (LLMs). However, existing methods often misinfer non-members as members, leading to a high false positive rate, or depend on additional reference models for probability calibration, which limits their practicality. To overcome these challenges, we introduce a novel framework called Automatic Calibration Membership Inference Attack (ACMIA), which utilizes a tunable temperature to calibrate output probabilities effectively. This approach is inspired by our theoretical insights into maximum likelihood estimation during the pre-training of LLMs. We introduce ACMIA in three configurations designed to accommodate different levels of model access and increase the probability gap between members and non-members, improving the reliability and robustness of membership inference. Extensive experiments on various open-source LLMs demonstrate that our proposed attack is highly effective, robust, and generalizable, surpassing state-of-the-art baselines across three widely used benchmarks. Our code is available at: \href{https://github.com/Salehzz/ACMIA}{\textcolor{blue}{Github}}.
BiPVL-Seg: Bidirectional Progressive Vision-Language Fusion with Global-Local Alignment for Medical Image Segmentation
Mar 30, 2025



Medical image segmentation typically relies solely on visual data, overlooking the rich textual information clinicians use for diagnosis. Vision-language models attempt to bridge this gap, but existing approaches often process visual and textual features independently, resulting in weak cross-modal alignment. Simple fusion techniques fail due to the inherent differences between spatial visual features and sequential text embeddings. Additionally, medical terminology deviates from general language, limiting the effectiveness of off-the-shelf text encoders and further hindering vision-language alignment. We propose BiPVL-Seg, an end-to-end framework that integrates vision-language fusion and embedding alignment through architectural and training innovations, where both components reinforce each other to enhance medical image segmentation. BiPVL-Seg introduces bidirectional progressive fusion in the architecture, which facilitates stage-wise information exchange between vision and text encoders. Additionally, it incorporates global-local contrastive alignment, a training objective that enhances the text encoder's comprehension by aligning text and vision embeddings at both class and concept levels. Extensive experiments on diverse medical imaging benchmarks across CT and MR modalities demonstrate BiPVL-Seg's superior performance when compared with state-of-the-art methods in complex multi-class segmentation. Source code is available in this GitHub repository.
MulModSeg: Enhancing Unpaired Multi-Modal Medical Image Segmentation with Modality-Conditioned Text Embedding and Alternating Training
Nov 23, 2024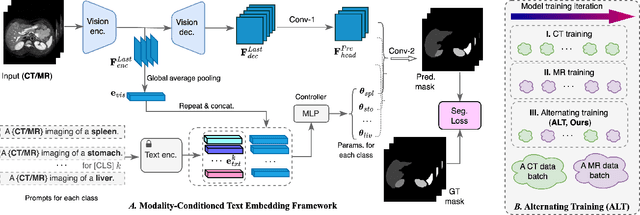
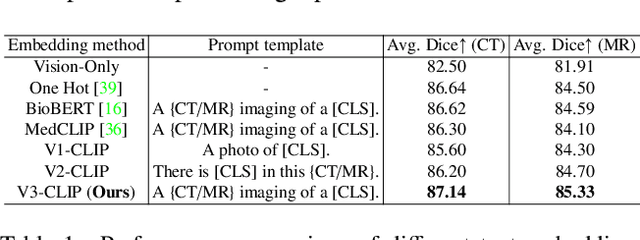
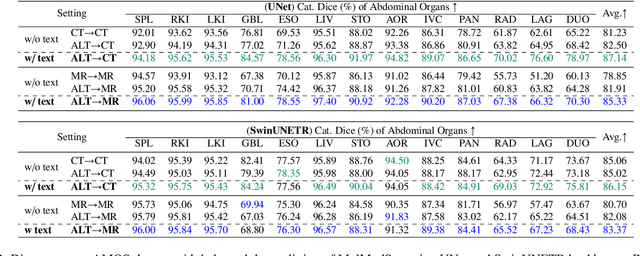
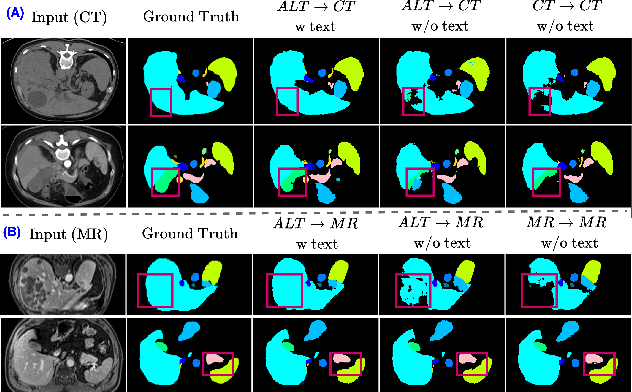
In the diverse field of medical imaging, automatic segmentation has numerous applications and must handle a wide variety of input domains, such as different types of Computed Tomography (CT) scans and Magnetic Resonance (MR) images. This heterogeneity challenges automatic segmentation algorithms to maintain consistent performance across different modalities due to the requirement for spatially aligned and paired images. Typically, segmentation models are trained using a single modality, which limits their ability to generalize to other types of input data without employing transfer learning techniques. Additionally, leveraging complementary information from different modalities to enhance segmentation precision often necessitates substantial modifications to popular encoder-decoder designs, such as introducing multiple branched encoding or decoding paths for each modality. In this work, we propose a simple Multi-Modal Segmentation (MulModSeg) strategy to enhance medical image segmentation across multiple modalities, specifically CT and MR. It incorporates two key designs: a modality-conditioned text embedding framework via a frozen text encoder that adds modality awareness to existing segmentation frameworks without significant structural modifications or computational overhead, and an alternating training procedure that facilitates the integration of essential features from unpaired CT and MR inputs. Through extensive experiments with both Fully Convolutional Network and Transformer-based backbones, MulModSeg consistently outperforms previous methods in segmenting abdominal multi-organ and cardiac substructures for both CT and MR modalities. The code is available in this {\href{https://github.com/ChengyinLee/MulModSeg_2024}{link}}.
Learning to Poison Large Language Models During Instruction Tuning
Feb 21, 2024



The advent of Large Language Models (LLMs) has marked significant achievements in language processing and reasoning capabilities. Despite their advancements, LLMs face vulnerabilities to data poisoning attacks, where adversaries insert backdoor triggers into training data to manipulate outputs for malicious purposes. This work further identifies additional security risks in LLMs by designing a new data poisoning attack tailored to exploit the instruction tuning process. We propose a novel gradient-guided backdoor trigger learning approach to identify adversarial triggers efficiently, ensuring an evasion of detection by conventional defenses while maintaining content integrity. Through experimental validation across various LLMs and tasks, our strategy demonstrates a high success rate in compromising model outputs; poisoning only 1\% of 4,000 instruction tuning samples leads to a Performance Drop Rate (PDR) of around 80\%. Our work highlights the need for stronger defenses against data poisoning attack, offering insights into safeguarding LLMs against these more sophisticated attacks. The source code can be found on this GitHub repository: https://github.com/RookieZxy/GBTL/blob/main/README.md.
MFABA: A More Faithful and Accelerated Boundary-based Attribution Method for Deep Neural Networks
Dec 21, 2023



To better understand the output of deep neural networks (DNN), attribution based methods have been an important approach for model interpretability, which assign a score for each input dimension to indicate its importance towards the model outcome. Notably, the attribution methods use the axioms of sensitivity and implementation invariance to ensure the validity and reliability of attribution results. Yet, the existing attribution methods present challenges for effective interpretation and efficient computation. In this work, we introduce MFABA, an attribution algorithm that adheres to axioms, as a novel method for interpreting DNN. Additionally, we provide the theoretical proof and in-depth analysis for MFABA algorithm, and conduct a large scale experiment. The results demonstrate its superiority by achieving over 101.5142 times faster speed than the state-of-the-art attribution algorithms. The effectiveness of MFABA is thoroughly evaluated through the statistical analysis in comparison to other methods, and the full implementation package is open-source at: https://github.com/LMBTough/MFABA
FedDRO: Federated Compositional Optimization for Distributionally Robust Learning
Nov 21, 2023

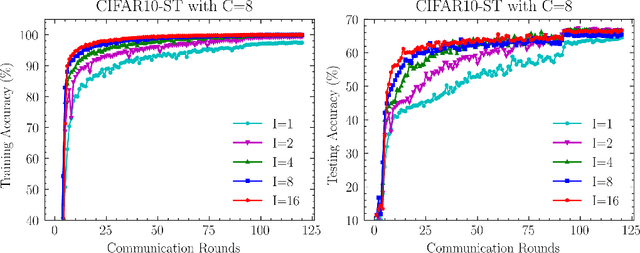
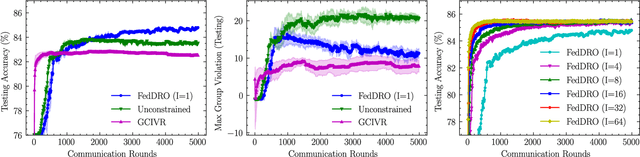
Recently, compositional optimization (CO) has gained popularity because of its applications in distributionally robust optimization (DRO) and many other machine learning problems. Large-scale and distributed availability of data demands the development of efficient federated learning (FL) algorithms for solving CO problems. Developing FL algorithms for CO is particularly challenging because of the compositional nature of the objective. Moreover, current state-of-the-art methods to solve such problems rely on large batch gradients (depending on the solution accuracy) not feasible for most practical settings. To address these challenges, in this work, we propose efficient FedAvg-type algorithms for solving non-convex CO in the FL setting. We first establish that vanilla FedAvg is not suitable to solve distributed CO problems because of the data heterogeneity in the compositional objective at each client which leads to the amplification of bias in the local compositional gradient estimates. To this end, we propose a novel FL framework FedDRO that utilizes the DRO problem structure to design a communication strategy that allows FedAvg to control the bias in the estimation of the compositional gradient. A key novelty of our work is to develop solution accuracy-independent algorithms that do not require large batch gradients (and function evaluations) for solving federated CO problems. We establish $\mathcal{O}(\epsilon^{-2})$ sample and $\mathcal{O}(\epsilon^{-3/2})$ communication complexity in the FL setting while achieving linear speedup with the number of clients. We corroborate our theoretical findings with empirical studies on large-scale DRO problems.