 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalkGPT: Grounded Vision-Language Conversation with Depth-Aware Segmentation for Pedestrian Navigation
Mar 11, 2026Ensuring accessible pedestrian navigation requires reasoning about both semantic and spatial aspects of complex urban scenes, a challenge that existing Large Vision-Language Models (LVLMs) struggle to meet. Although these models can describe visual content, their lack of explicit grounding leads to object hallucinations and unreliable depth reasoning, limiting their usefulness for accessibility guidance. We introduce WalkGPT, a pixel-grounded LVLM for the new task of Grounded Navigation Guide, unifying language reasoning and segmentation within a single architecture for depth-aware accessibility guidance. Given a pedestrian-view image and a navigation query, WalkGPT generates a conversational response with segmentation masks that delineate accessible and harmful features, along with relative depth estimation. The model incorporates a Multi-Scale Query Projector (MSQP) that shapes the final image tokens by aggregating them along text tokens across spatial hierarchies, and a Calibrated Text Projector (CTP), guided by a proposed Region Alignment Loss, that maps language embeddings into segmentation-aware representations. These components enable fine-grained grounding and depth inference without user-provided cues or anchor points, allowing the model to generate complete and realistic navigation guidance. We also introduce PAVE, a large-scale benchmark of 41k pedestrian-view images paired with accessibility-aware questions and depth-grounded answers. Experiments show that WalkGPT achieves strong grounded reasoning and segmentation performance. The source code and dataset are available on the \href{https://sites.google.com/view/walkgpt-26/home}{project website}.
BiPVL-Seg: Bidirectional Progressive Vision-Language Fusion with Global-Local Alignment for Medical Image Segmentation
Mar 30, 2025



Medical image segmentation typically relies solely on visual data, overlooking the rich textual information clinicians use for diagnosis. Vision-language models attempt to bridge this gap, but existing approaches often process visual and textual features independently, resulting in weak cross-modal alignment. Simple fusion techniques fail due to the inherent differences between spatial visual features and sequential text embeddings. Additionally, medical terminology deviates from general language, limiting the effectiveness of off-the-shelf text encoders and further hindering vision-language alignment. We propose BiPVL-Seg, an end-to-end framework that integrates vision-language fusion and embedding alignment through architectural and training innovations, where both components reinforce each other to enhance medical image segmentation. BiPVL-Seg introduces bidirectional progressive fusion in the architecture, which facilitates stage-wise information exchange between vision and text encoders. Additionally, it incorporates global-local contrastive alignment, a training objective that enhances the text encoder's comprehension by aligning text and vision embeddings at both class and concept levels. Extensive experiments on diverse medical imaging benchmarks across CT and MR modalities demonstrate BiPVL-Seg's superior performance when compared with state-of-the-art methods in complex multi-class segmentation. Source code is available in this GitHub repository.
MulModSeg: Enhancing Unpaired Multi-Modal Medical Image Segmentation with Modality-Conditioned Text Embedding and Alternating Training
Nov 23, 2024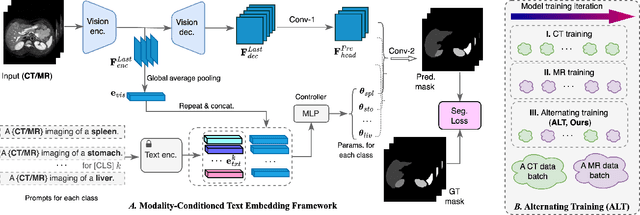
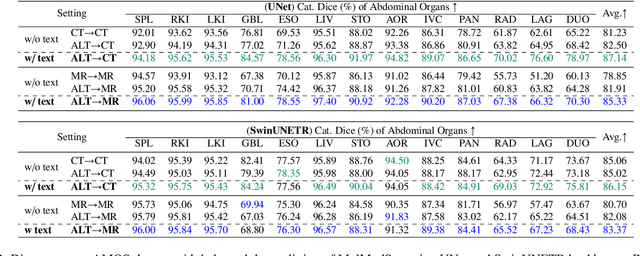
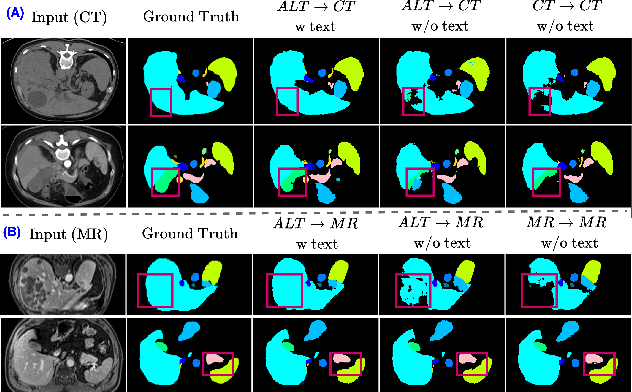
In the diverse field of medical imaging, automatic segmentation has numerous applications and must handle a wide variety of input domains, such as different types of Computed Tomography (CT) scans and Magnetic Resonance (MR) images. This heterogeneity challenges automatic segmentation algorithms to maintain consistent performance across different modalities due to the requirement for spatially aligned and paired images. Typically, segmentation models are trained using a single modality, which limits their ability to generalize to other types of input data without employing transfer learning techniques. Additionally, leveraging complementary information from different modalities to enhance segmentation precision often necessitates substantial modifications to popular encoder-decoder designs, such as introducing multiple branched encoding or decoding paths for each modality. In this work, we propose a simple Multi-Modal Segmentation (MulModSeg) strategy to enhance medical image segmentation across multiple modalities, specifically CT and MR. It incorporates two key designs: a modality-conditioned text embedding framework via a frozen text encoder that adds modality awareness to existing segmentation frameworks without significant structural modifications or computational overhead, and an alternating training procedure that facilitates the integration of essential features from unpaired CT and MR inputs. Through extensive experiments with both Fully Convolutional Network and Transformer-based backbones, MulModSeg consistently outperforms previous methods in segmenting abdominal multi-organ and cardiac substructures for both CT and MR modalities. The code is available in this {\href{https://github.com/ChengyinLee/MulModSeg_2024}{link}}.
FedDRO: Federated Compositional Optimization for Distributionally Robust Learning
Nov 21, 2023

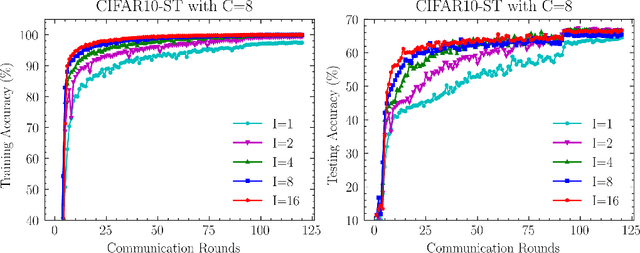
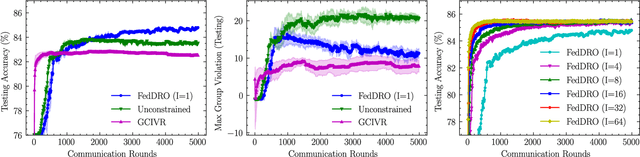
Recently, compositional optimization (CO) has gained popularity because of its applications in distributionally robust optimization (DRO) and many other machine learning problems. Large-scale and distributed availability of data demands the development of efficient federated learning (FL) algorithms for solving CO problems. Developing FL algorithms for CO is particularly challenging because of the compositional nature of the objective. Moreover, current state-of-the-art methods to solve such problems rely on large batch gradients (depending on the solution accuracy) not feasible for most practical settings. To address these challenges, in this work, we propose efficient FedAvg-type algorithms for solving non-convex CO in the FL setting. We first establish that vanilla FedAvg is not suitable to solve distributed CO problems because of the data heterogeneity in the compositional objective at each client which leads to the amplification of bias in the local compositional gradient estimates. To this end, we propose a novel FL framework FedDRO that utilizes the DRO problem structure to design a communication strategy that allows FedAvg to control the bias in the estimation of the compositional gradient. A key novelty of our work is to develop solution accuracy-independent algorithms that do not require large batch gradients (and function evaluations) for solving federated CO problems. We establish $\mathcal{O}(\epsilon^{-2})$ sample and $\mathcal{O}(\epsilon^{-3/2})$ communication complexity in the FL setting while achieving linear speedup with the number of clients. We corroborate our theoretical findings with empirical studies on large-scale DRO problems.
GeoSAM: Fine-tuning SAM with Sparse and Dense Visual Prompting for Automated Segmentation of Mobility Infrastructure
Nov 19, 2023



The Segment Anything Model (SAM) has shown impressive performance when applied to natural image segmentation. However, it struggles with geographical images like aerial and satellite imagery, especially when segmenting mobility infrastructure including roads, sidewalks, and crosswalks. This inferior performance stems from the narrow features of these objects, their textures blending into the surroundings, and interference from objects like trees, buildings, vehicles, and pedestrians - all of which can disorient the model to produce inaccurate segmentation maps. To address these challenges, we propose Geographical SAM (GeoSAM), a novel SAM-based framework that implements a fine-tuning strategy using the dense visual prompt from zero-shot learning, and the sparse visual prompt from a pre-trained CNN segmentation model. The proposed GeoSAM outperforms existing approaches for geographical image segmentation, specifically by 20%, 14.29%, and 17.65% for road infrastructure, pedestrian infrastructure, and on average, respectively, representing a momentous leap in leveraging foundation models to segment mobility infrastructure including both road and pedestrian infrastructure in geographical images.
Interpretability-Aware Vision Transformer
Sep 14, 2023


Vision Transformers (ViTs) have become prominent models for solving various vision tasks. However, the interpretability of ViTs has not kept pace with their promising performance. While there has been a surge of interest in developing {\it post hoc} solutions to explain ViTs' outputs, these methods do not generalize to different downstream tasks and various transformer architectures. Furthermore, if ViTs are not properly trained with the given data and do not prioritize the region of interest, the {\it post hoc} methods would be less effective. Instead of developing another {\it post hoc} approach, we introduce a novel training procedure that inherently enhances model interpretability. Our interpretability-aware ViT (IA-ViT) draws inspiration from a fresh insight: both the class patch and image patches consistently generate predicted distributions and attention maps. IA-ViT is composed of a feature extractor, a predictor, and an interpreter, which are trained jointly with an interpretability-aware training objective. Consequently, the interpreter simulates the behavior of the predictor and provides a faithful explanation through its single-head self-attention mechanism. Our comprehensive experimental results demonstrate the effectiveness of IA-ViT in several image classification tasks, with both qualitative and quantitative evaluations of model performance and interpretability. Source code is available from: https://github.com/qiangyao1988/IA-ViT.
Auto-Prompting SAM for Mobile Friendly 3D Medical Image Segmentation
Aug 28, 2023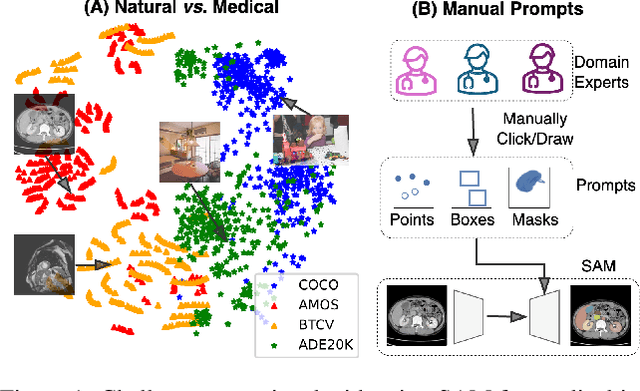
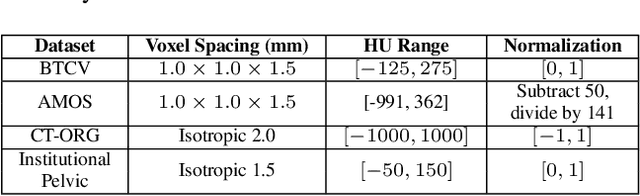
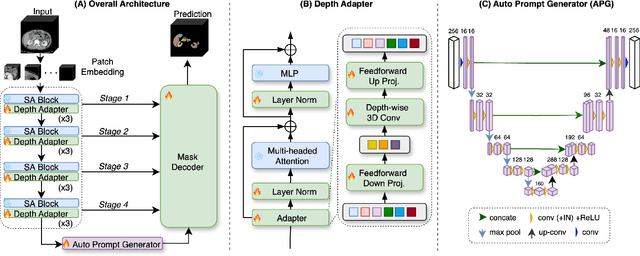
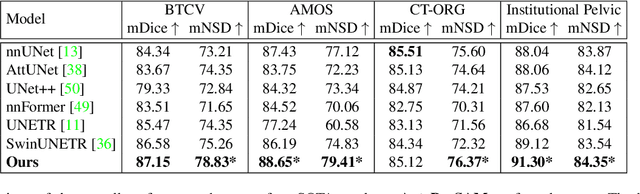
The Segment Anything Model (SAM) has rapidly been adopted for segmenting a wide range of natural images. However, recent studies have indicated that SAM exhibits subpar performance on 3D medical image segmentation tasks. In addition to the domain gaps between natural and medical images, disparities in the spatial arrangement between 2D and 3D images, the substantial computational burden imposed by powerful GPU servers, and the time-consuming manual prompt generation impede the extension of SAM to a broader spectrum of medical image segmentation applications. To address these challenges, in this work, we introduce a novel method, AutoSAM Adapter, designed specifically for 3D multi-organ CT-based segmentation. We employ parameter-efficient adaptation techniques in developing an automatic prompt learning paradigm to facilitate the transformation of the SAM model's capabilities to 3D medical image segmentation, eliminating the need for manually generated prompts. Furthermore, we effectively transfer the acquired knowledge of the AutoSAM Adapter to other lightweight models specifically tailored for 3D medical image analysis, achieving state-of-the-art (SOTA) performance on medical image segmentation tasks. Through extensive experimental evaluation, we demonstrate the AutoSAM Adapter as a critical foundation for effectively leveraging the emerging ability of foundation models in 2D natural image segmentation for 3D medical image segmentation.
Fairness-aware Vision Transformer via Debiased Self-Attention
Jan 31, 2023

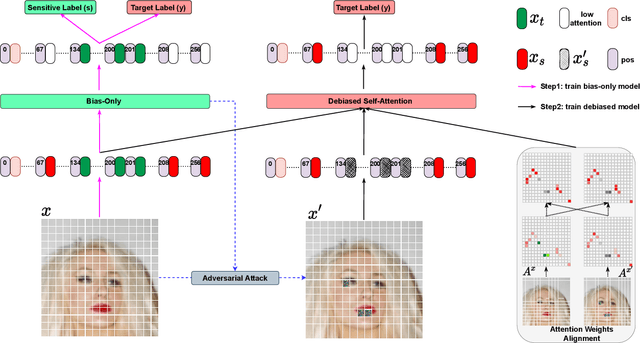
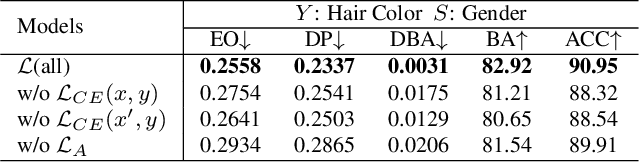
Vision Transformer (ViT) has recently gained significant interest in solving computer vision (CV) problems due to its capability of extracting informative features and modeling long-range dependencies through the self-attention mechanism. To fully realize the advantages of ViT in real-world applications, recent works have explored the trustworthiness of ViT, including its robustness and explainability. However, another desiderata, fairness has not yet been adequately addressed in the literature. We establish that the existing fairness-aware algorithms (primarily designed for CNNs) do not perform well on ViT. This necessitates the need for developing our novel framework via Debiased Self-Attention (DSA). DSA is a fairness-through-blindness approach that enforces ViT to eliminate spurious features correlated with the sensitive attributes for bias mitigation. Notably, adversarial examples are leveraged to locate and mask the spurious features in the input image patches. In addition, DSA utilizes an attention weights alignment regularizer in the training objective to encourage learning informative features for target prediction. Importantly, our DSA framework leads to improved fairness guarantees over prior works on multiple prediction tasks without compromising target prediction performance
Negative Flux Aggregation to Estimate Feature Attributions
Jan 17, 2023



There are increasing demands for understanding deep neural networks' (DNNs) behavior spurred by growing security and/or transparency concerns. Due to multi-layer nonlinearity of the deep neural network architectures, explaining DNN predictions still remains as an open problem, preventing us from gaining a deeper understanding of the mechanisms. To enhance the explainability of DNNs, we estimate the input feature's attributions to the prediction task using divergence and flux. Inspired by the divergence theorem in vector analysis, we develop a novel Negative Flux Aggregation (NeFLAG) formulation and an efficient approximation algorithm to estimate attribution map. Unlike the previous techniques, ours doesn't rely on fitting a surrogate model nor need any path integration of gradients. Both qualitative and quantitative experiments demonstrate a superior performance of NeFLAG in generating more faithful attribution maps than the competing methods.
Coupling User Preference with External Rewards to Enable Driver-centered and Resource-aware EV Charging Recommendation
Oct 23, 2022Electric Vehicle (EV) charging recommendation that both accommodates user preference and adapts to the ever-changing external environment arises as a cost-effective strategy to alleviate the range anxiety of private EV drivers. Previous studies focus on centralized strategies to achieve optimized resource allocation, particularly useful for privacy-indifferent taxi fleets and fixed-route public transits. However, private EV driver seeks a more personalized and resource-aware charging recommendation that is tailor-made to accommodate the user preference (when and where to charge) yet sufficiently adaptive to the spatiotemporal mismatch between charging supply and demand. Here we propose a novel Regularized Actor-Critic (RAC) charging recommendation approach that would allow each EV driver to strike an optimal balance between the user preference (historical charging pattern) and the external reward (driving distance and wait time). Experimental results on two real-world datasets demonstrate the unique features and superior performance of our approach to the competing methods.