 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVALID: a Validated Algorithm for Learning in Decentralized Networks with Possible Adversarial Presence
May 12, 2024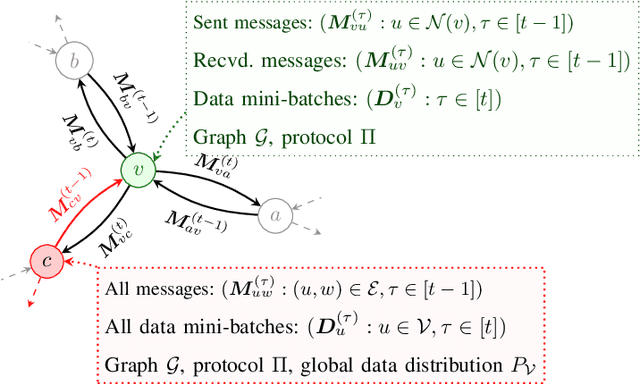
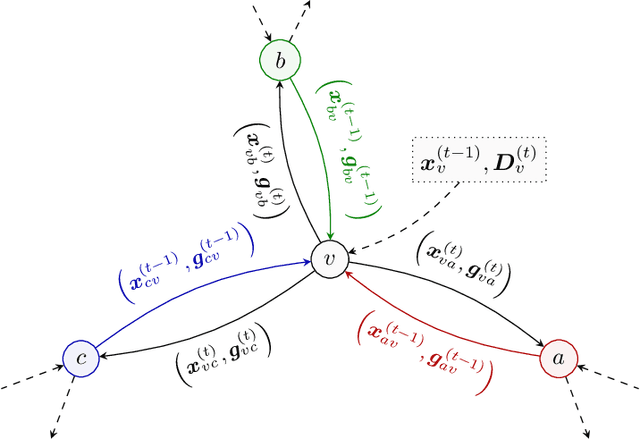
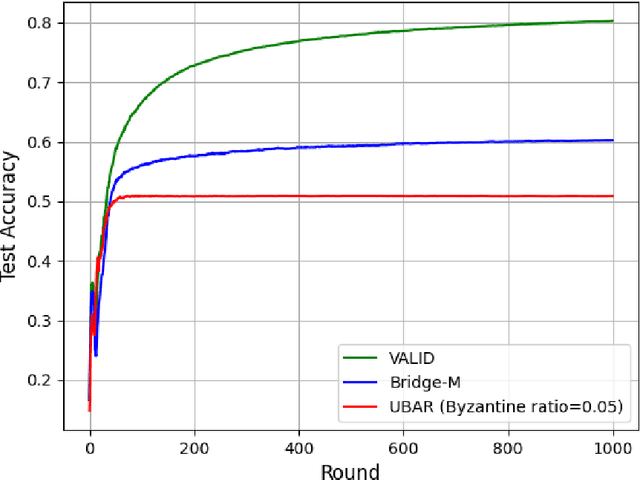
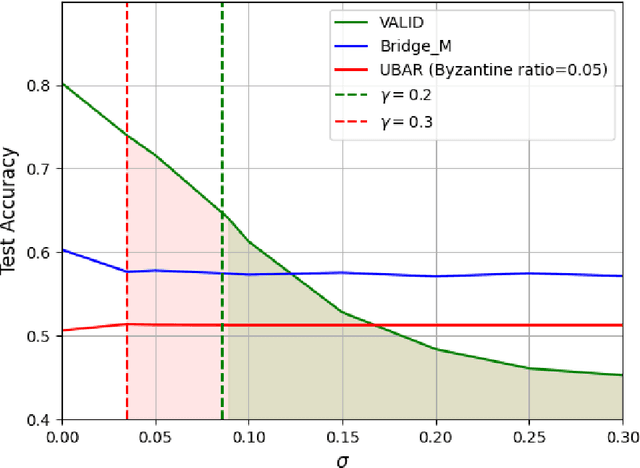
We introduce the paradigm of validated decentralized learning for undirected networks with heterogeneous data and possible adversarial infiltration. We require (a) convergence to a global empirical loss minimizer when adversaries are absent, and (b) either detection of adversarial presence of convergence to an admissible consensus irrespective of the adversarial configuration. To this end, we propose the VALID protocol which, to the best of our knowledge, is the first to achieve a validated learning guarantee. Moreover, VALID offers an O(1/T) convergence rate (under pertinent regularity assumptions), and computational and communication complexities comparable to non-adversarial distributed stochastic gradient descent. Remarkably, VALID retains optimal performance metrics in adversary-free environments, sidestepping the robustness penalties observed in prior byzantine-robust methods. A distinctive aspect of our study is a heterogeneity metric based on the norms of individual agents' gradients computed at the global empirical loss minimizer. This not only provides a natural statistic for detecting significant byzantine disruptions but also allows us to prove the optimality of VALID in wide generality. Lastly, our numerical results reveal that, in the absence of adversaries, VALID converges faster than state-of-the-art byzantine robust algorithms, while when adversaries are present, VALID terminates with each honest either converging to an admissible consensus of declaring adversarial presence in the network.
FedDRO: Federated Compositional Optimization for Distributionally Robust Learning
Nov 21, 2023

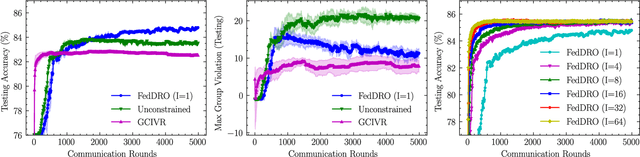
Recently, compositional optimization (CO) has gained popularity because of its applications in distributionally robust optimization (DRO) and many other machine learning problems. Large-scale and distributed availability of data demands the development of efficient federated learning (FL) algorithms for solving CO problems. Developing FL algorithms for CO is particularly challenging because of the compositional nature of the objective. Moreover, current state-of-the-art methods to solve such problems rely on large batch gradients (depending on the solution accuracy) not feasible for most practical settings. To address these challenges, in this work, we propose efficient FedAvg-type algorithms for solving non-convex CO in the FL setting. We first establish that vanilla FedAvg is not suitable to solve distributed CO problems because of the data heterogeneity in the compositional objective at each client which leads to the amplification of bias in the local compositional gradient estimates. To this end, we propose a novel FL framework FedDRO that utilizes the DRO problem structure to design a communication strategy that allows FedAvg to control the bias in the estimation of the compositional gradient. A key novelty of our work is to develop solution accuracy-independent algorithms that do not require large batch gradients (and function evaluations) for solving federated CO problems. We establish $\mathcal{O}(\epsilon^{-2})$ sample and $\mathcal{O}(\epsilon^{-3/2})$ communication complexity in the FL setting while achieving linear speedup with the number of clients. We corroborate our theoretical findings with empirical studies on large-scale DRO problems.
RELDEC: Reinforcement Learning-Based Decoding of Moderate Length LDPC Codes
Dec 27, 2021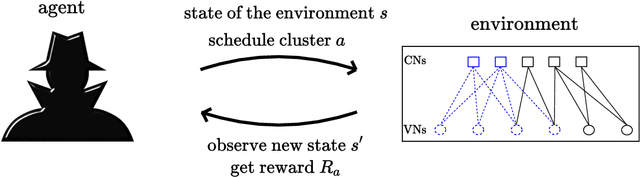
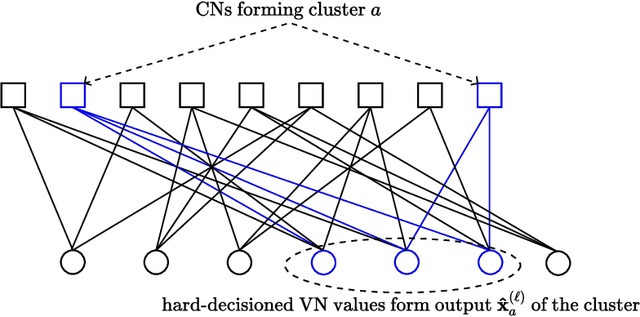
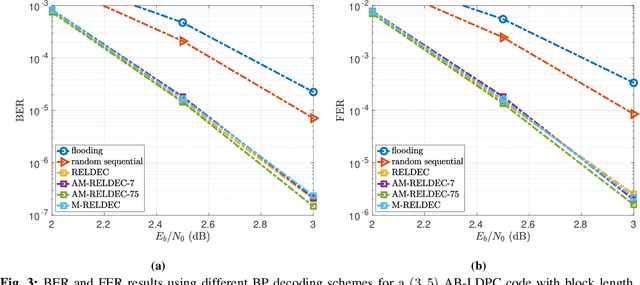
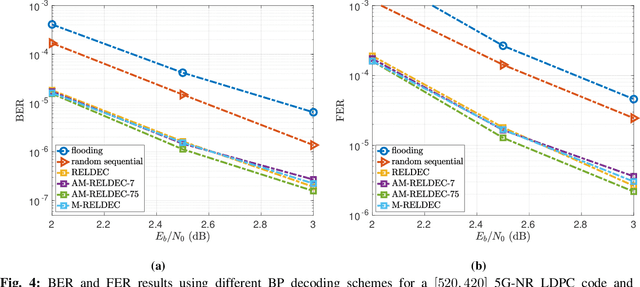
In this work we propose RELDEC, a novel approach for sequential decoding of moderate length low-density parity-check (LDPC) codes. The main idea behind RELDEC is that an optimized decoding policy is subsequently obtained via reinforcement learning based on a Markov decision process (MDP). In contrast to our previous work, where an agent learns to schedule only a single check node (CN) within a group (cluster) of CNs per iteration, in this work we train the agent to schedule all CNs in a cluster, and all clusters in every iteration. That is, in each learning step of RELDEC an agent learns to schedule CN clusters sequentially depending on a reward associated with the outcome of scheduling a particular cluster. We also modify the state space representation of the MDP, enabling RELDEC to be suitable for larger block length LDPC codes than those studied in our previous work. Furthermore, to address decoding under varying channel conditions, we propose two related schemes, namely, agile meta-RELDEC (AM-RELDEC) and meta-RELDEC (M-RELDEC), both of which employ meta-reinforcement learning. The proposed RELDEC scheme significantly outperforms standard flooding and random sequential decoding for a variety of LDPC codes, including codes designed for 5G new radio.
Generative Adversarial User Privacy in Lossy Single-Server Information Retrieval
Dec 07, 2020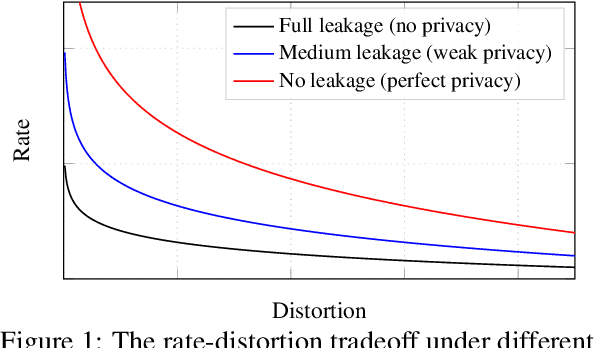
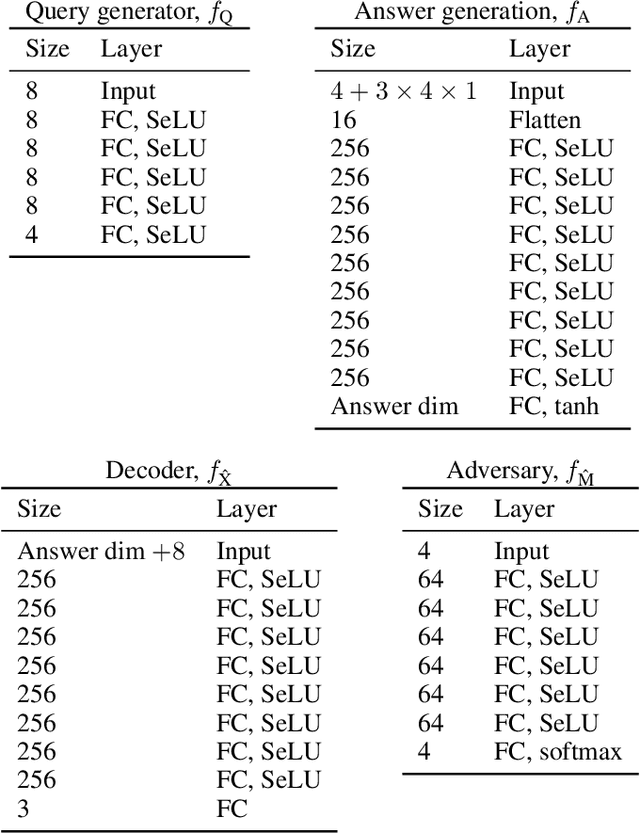
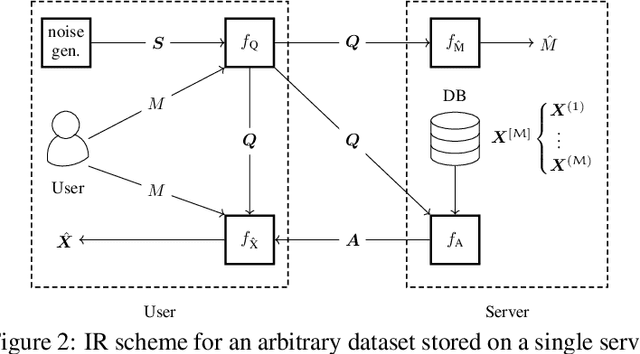

We consider the problem of information retrieval from a dataset of files stored on a single server under both a user distortion and a user privacy constraint. Specifically, a user requesting a file from the dataset should be able to reconstruct the requested file with a prescribed distortion, and in addition, the identity of the requested file should be kept private from the server with a prescribed privacy level. The proposed model can be seen as an extension of the well-known concept of private information retrieval by allowing for distortion in the retrieval process and relaxing the perfect privacy requirement. We initiate the study of the tradeoff between download rate, distortion, and user privacy leakage, and show that the optimal rate-distortion-leakage tradeoff is convex and that in the limit of large file sizes this allows for a concise information-theoretical formulation in terms of mutual information. Moreover, we propose a new data-driven framework by leveraging recent advancements in generative adversarial models which allows a user to learn efficient schemes in terms of download rate from the data itself. Learning the scheme is formulated as a constrained minimax game between a user which desires to keep the identity of the requested file private and an adversary that tries to infer which file the user is interested in under a distortion constraint. In general, guaranteeing a certain privacy level leads to a higher rate-distortion tradeoff curve, and hence a sacrifice in either download rate or distortion. We evaluate the performance of the scheme on a synthetic Gaussian dataset as well as on the MNIST and CIFAR-$10$ datasets. For the MNIST dataset, the data-driven approach significantly outperforms a proposed general achievable scheme combining source coding with the download of multiple files, while for CIFAR-$10$ the performances are comparable.