 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVALID: a Validated Algorithm for Learning in Decentralized Networks with Possible Adversarial Presence
May 12, 2024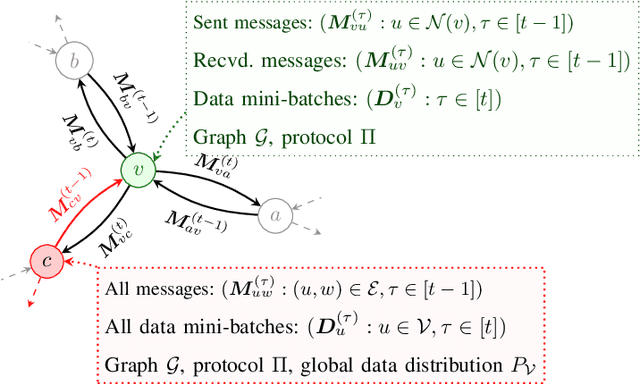
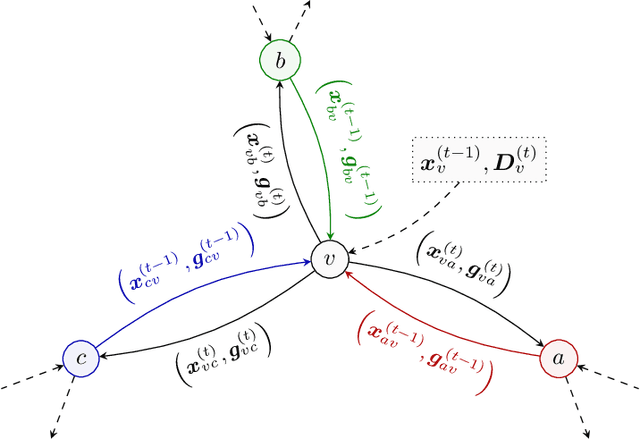
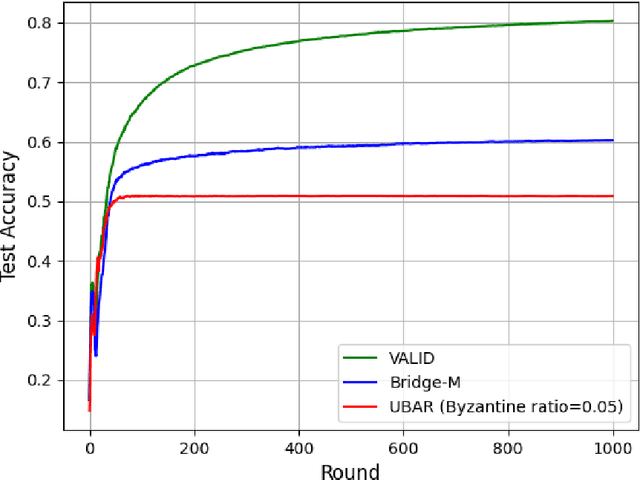
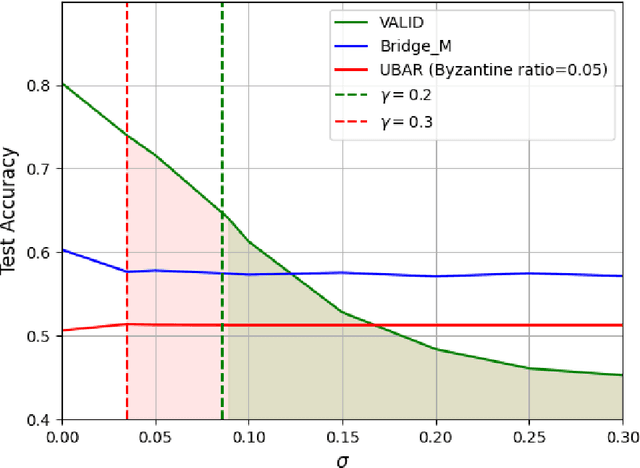
We introduce the paradigm of validated decentralized learning for undirected networks with heterogeneous data and possible adversarial infiltration. We require (a) convergence to a global empirical loss minimizer when adversaries are absent, and (b) either detection of adversarial presence of convergence to an admissible consensus irrespective of the adversarial configuration. To this end, we propose the VALID protocol which, to the best of our knowledge, is the first to achieve a validated learning guarantee. Moreover, VALID offers an O(1/T) convergence rate (under pertinent regularity assumptions), and computational and communication complexities comparable to non-adversarial distributed stochastic gradient descent. Remarkably, VALID retains optimal performance metrics in adversary-free environments, sidestepping the robustness penalties observed in prior byzantine-robust methods. A distinctive aspect of our study is a heterogeneity metric based on the norms of individual agents' gradients computed at the global empirical loss minimizer. This not only provides a natural statistic for detecting significant byzantine disruptions but also allows us to prove the optimality of VALID in wide generality. Lastly, our numerical results reveal that, in the absence of adversaries, VALID converges faster than state-of-the-art byzantine robust algorithms, while when adversaries are present, VALID terminates with each honest either converging to an admissible consensus of declaring adversarial presence in the network.
RELDEC: Reinforcement Learning-Based Decoding of Moderate Length LDPC Codes
Dec 27, 2021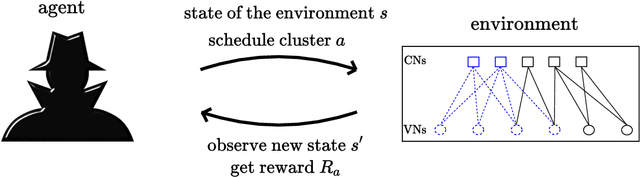
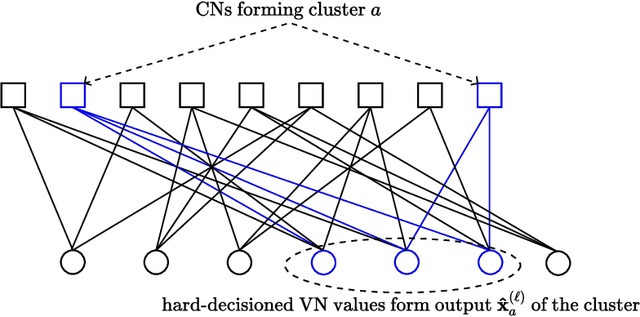
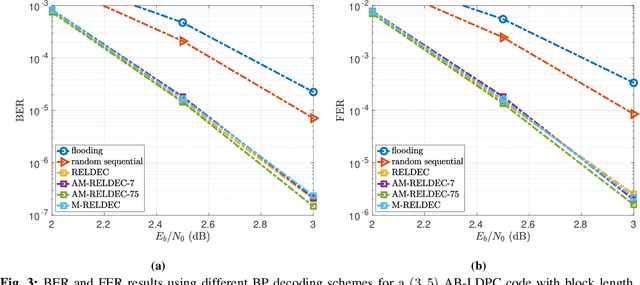
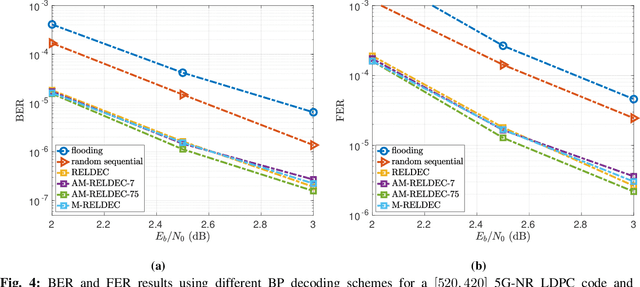
In this work we propose RELDEC, a novel approach for sequential decoding of moderate length low-density parity-check (LDPC) codes. The main idea behind RELDEC is that an optimized decoding policy is subsequently obtained via reinforcement learning based on a Markov decision process (MDP). In contrast to our previous work, where an agent learns to schedule only a single check node (CN) within a group (cluster) of CNs per iteration, in this work we train the agent to schedule all CNs in a cluster, and all clusters in every iteration. That is, in each learning step of RELDEC an agent learns to schedule CN clusters sequentially depending on a reward associated with the outcome of scheduling a particular cluster. We also modify the state space representation of the MDP, enabling RELDEC to be suitable for larger block length LDPC codes than those studied in our previous work. Furthermore, to address decoding under varying channel conditions, we propose two related schemes, namely, agile meta-RELDEC (AM-RELDEC) and meta-RELDEC (M-RELDEC), both of which employ meta-reinforcement learning. The proposed RELDEC scheme significantly outperforms standard flooding and random sequential decoding for a variety of LDPC codes, including codes designed for 5G new radio.