 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAG-X: Systematic Diagnosis of Retrieval-Augmented Generation for Medical Question Answering
Mar 03, 2026Automated question-answering (QA) systems increasingly rely on retrieval-augmented generation (RAG) to ground large language models (LLMs) in authoritative medical knowledge, ensuring clinical accuracy and patient safety in Artificial Intelligence (AI) applications for healthcare. Despite progress in RAG evaluation, current benchmarks focus only on simple multiple-choice QA tasks and employ metrics that poorly capture the semantic precision required for complex QA tasks. These approaches fail to diagnose whether an error stems from faulty retrieval or flawed generation, limiting developers from performing targeted improvement. To address this gap, we propose RAG-X, a diagnostic framework that evaluates the retriever and generator independently across a triad of QA tasks: information extraction, short-answer generation, and multiple-choice question (MCQ) answering. RAG-X introduces Context Utilization Efficiency (CUE) metrics to disaggregate system success into interpretable quadrants, isolating verified grounding from deceptive accuracy. Our experiments reveal an ``Accuracy Fallacy", where a 14\% gap separates perceived system success from evidence-based grounding. By surfacing hidden failure modes, RAG-X offers the diagnostic transparency needed for safe and verifiable clinical RAG systems.
Automatic Calibration for Membership Inference Attack on Large Language Models
May 06, 2025



Membership Inference Attacks (MIAs) have recently been employed to determine whether a specific text was part of the pre-training data of Large Language Models (LLMs). However, existing methods often misinfer non-members as members, leading to a high false positive rate, or depend on additional reference models for probability calibration, which limits their practicality. To overcome these challenges, we introduce a novel framework called Automatic Calibration Membership Inference Attack (ACMIA), which utilizes a tunable temperature to calibrate output probabilities effectively. This approach is inspired by our theoretical insights into maximum likelihood estimation during the pre-training of LLMs. We introduce ACMIA in three configurations designed to accommodate different levels of model access and increase the probability gap between members and non-members, improving the reliability and robustness of membership inference. Extensive experiments on various open-source LLMs demonstrate that our proposed attack is highly effective, robust, and generalizable, surpassing state-of-the-art baselines across three widely used benchmarks. Our code is available at: \href{https://github.com/Salehzz/ACMIA}{\textcolor{blue}{Github}}.
Prompt Perturbation Consistency Learning for Robust Language Models
Feb 24, 2024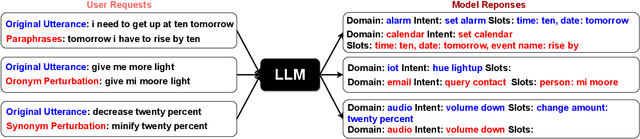

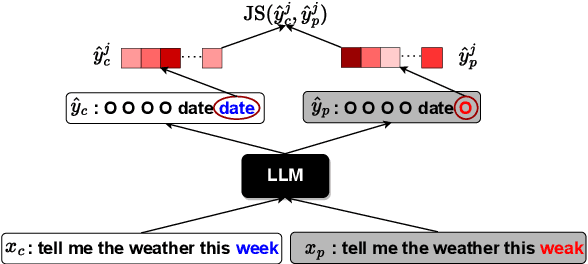

Large language models (LLMs) have demonstrated impressive performance on a number of natural language processing tasks, such as question answering and text summarization. However, their performance on sequence labeling tasks such as intent classification and slot filling (IC-SF), which is a central component in personal assistant systems, lags significantly behind discriminative models. Furthermore, there is a lack of substantive research on the robustness of LLMs to various perturbations in the input prompts. The contributions of this paper are three-fold. First, we show that fine-tuning sufficiently large LLMs can produce IC-SF performance comparable to discriminative models. Next, we systematically analyze the performance deterioration of those fine-tuned models due to three distinct yet relevant types of input perturbations - oronyms, synonyms, and paraphrasing. Finally, we propose an efficient mitigation approach, Prompt Perturbation Consistency Learning (PPCL), which works by regularizing the divergence between losses from clean and perturbed samples. Our experiments demonstrate that PPCL can recover on average 59% and 69% of the performance drop for IC and SF tasks, respectively. Furthermore, PPCL beats the data augmentation approach while using ten times fewer augmented data samples.
Learning to Poison Large Language Models During Instruction Tuning
Feb 21, 2024



The advent of Large Language Models (LLMs) has marked significant achievements in language processing and reasoning capabilities. Despite their advancements, LLMs face vulnerabilities to data poisoning attacks, where adversaries insert backdoor triggers into training data to manipulate outputs for malicious purposes. This work further identifies additional security risks in LLMs by designing a new data poisoning attack tailored to exploit the instruction tuning process. We propose a novel gradient-guided backdoor trigger learning approach to identify adversarial triggers efficiently, ensuring an evasion of detection by conventional defenses while maintaining content integrity. Through experimental validation across various LLMs and tasks, our strategy demonstrates a high success rate in compromising model outputs; poisoning only 1\% of 4,000 instruction tuning samples leads to a Performance Drop Rate (PDR) of around 80\%. Our work highlights the need for stronger defenses against data poisoning attack, offering insights into safeguarding LLMs against these more sophisticated attacks. The source code can be found on this GitHub repository: https://github.com/RookieZxy/GBTL/blob/main/README.md.
FedDRO: Federated Compositional Optimization for Distributionally Robust Learning
Nov 21, 2023

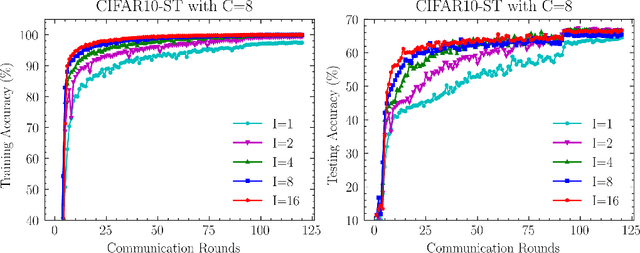
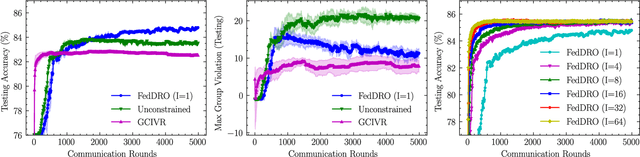
Recently, compositional optimization (CO) has gained popularity because of its applications in distributionally robust optimization (DRO) and many other machine learning problems. Large-scale and distributed availability of data demands the development of efficient federated learning (FL) algorithms for solving CO problems. Developing FL algorithms for CO is particularly challenging because of the compositional nature of the objective. Moreover, current state-of-the-art methods to solve such problems rely on large batch gradients (depending on the solution accuracy) not feasible for most practical settings. To address these challenges, in this work, we propose efficient FedAvg-type algorithms for solving non-convex CO in the FL setting. We first establish that vanilla FedAvg is not suitable to solve distributed CO problems because of the data heterogeneity in the compositional objective at each client which leads to the amplification of bias in the local compositional gradient estimates. To this end, we propose a novel FL framework FedDRO that utilizes the DRO problem structure to design a communication strategy that allows FedAvg to control the bias in the estimation of the compositional gradient. A key novelty of our work is to develop solution accuracy-independent algorithms that do not require large batch gradients (and function evaluations) for solving federated CO problems. We establish $\mathcal{O}(\epsilon^{-2})$ sample and $\mathcal{O}(\epsilon^{-3/2})$ communication complexity in the FL setting while achieving linear speedup with the number of clients. We corroborate our theoretical findings with empirical studies on large-scale DRO problems.
Hijacking Large Language Models via Adversarial In-Context Learning
Nov 16, 2023



In-context learning (ICL) has emerged as a powerful paradigm leveraging LLMs for specific tasks by utilizing labeled examples as demonstrations in the precondition prompts. Despite its promising performance, ICL suffers from instability with the choice and arrangement of examples. Additionally, crafted adversarial attacks pose a notable threat to the robustness of ICL. However, existing attacks are either easy to detect, rely on external models, or lack specificity towards ICL. To address these issues, this work introduces a novel transferable attack for ICL, aiming to hijack LLMs to generate the targeted response. The proposed LLM hijacking attack leverages a gradient-based prompt search method to learn and append imperceptible adversarial suffixes to the in-context demonstrations. Extensive experimental results on various tasks and datasets demonstrate the effectiveness of our LLM hijacking attack, resulting in a distracted attention towards adversarial tokens, consequently leading to the targeted unwanted outputs.
Interpretability-Aware Vision Transformer
Sep 14, 2023


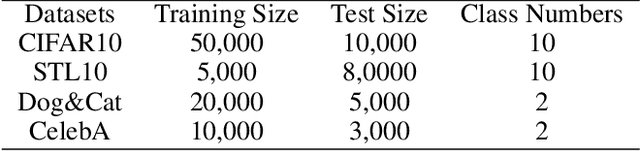
Vision Transformers (ViTs) have become prominent models for solving various vision tasks. However, the interpretability of ViTs has not kept pace with their promising performance. While there has been a surge of interest in developing {\it post hoc} solutions to explain ViTs' outputs, these methods do not generalize to different downstream tasks and various transformer architectures. Furthermore, if ViTs are not properly trained with the given data and do not prioritize the region of interest, the {\it post hoc} methods would be less effective. Instead of developing another {\it post hoc} approach, we introduce a novel training procedure that inherently enhances model interpretability. Our interpretability-aware ViT (IA-ViT) draws inspiration from a fresh insight: both the class patch and image patches consistently generate predicted distributions and attention maps. IA-ViT is composed of a feature extractor, a predictor, and an interpreter, which are trained jointly with an interpretability-aware training objective. Consequently, the interpreter simulates the behavior of the predictor and provides a faithful explanation through its single-head self-attention mechanism. Our comprehensive experimental results demonstrate the effectiveness of IA-ViT in several image classification tasks, with both qualitative and quantitative evaluations of model performance and interpretability. Source code is available from: https://github.com/qiangyao1988/IA-ViT.
Auto-Prompting SAM for Mobile Friendly 3D Medical Image Segmentation
Aug 28, 2023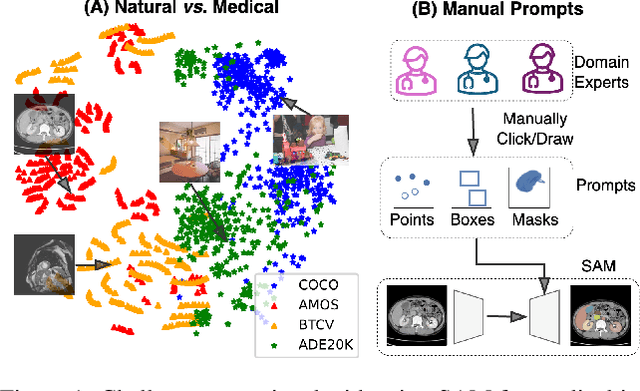
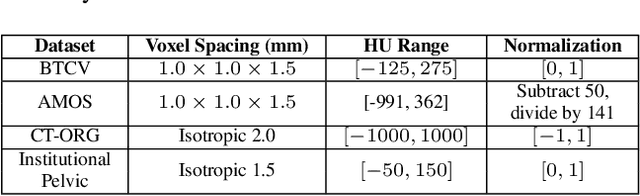
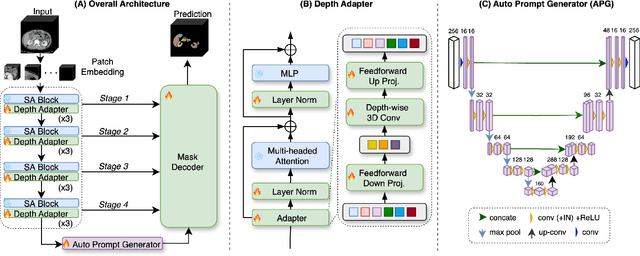
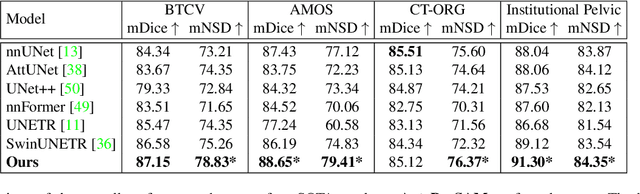
The Segment Anything Model (SAM) has rapidly been adopted for segmenting a wide range of natural images. However, recent studies have indicated that SAM exhibits subpar performance on 3D medical image segmentation tasks. In addition to the domain gaps between natural and medical images, disparities in the spatial arrangement between 2D and 3D images, the substantial computational burden imposed by powerful GPU servers, and the time-consuming manual prompt generation impede the extension of SAM to a broader spectrum of medical image segmentation applications. To address these challenges, in this work, we introduce a novel method, AutoSAM Adapter, designed specifically for 3D multi-organ CT-based segmentation. We employ parameter-efficient adaptation techniques in developing an automatic prompt learning paradigm to facilitate the transformation of the SAM model's capabilities to 3D medical image segmentation, eliminating the need for manually generated prompts. Furthermore, we effectively transfer the acquired knowledge of the AutoSAM Adapter to other lightweight models specifically tailored for 3D medical image analysis, achieving state-of-the-art (SOTA) performance on medical image segmentation tasks. Through extensive experimental evaluation, we demonstrate the AutoSAM Adapter as a critical foundation for effectively leveraging the emerging ability of foundation models in 2D natural image segmentation for 3D medical image segmentation.
Fairness-aware Vision Transformer via Debiased Self-Attention
Jan 31, 2023

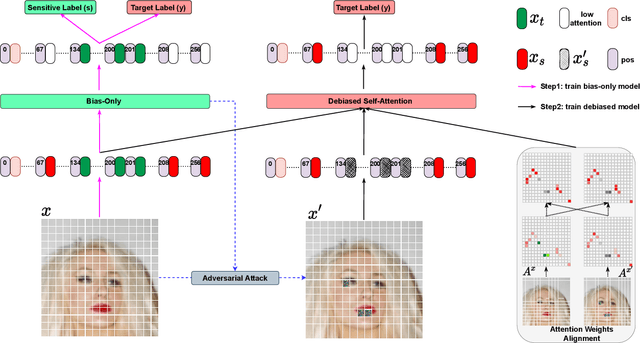
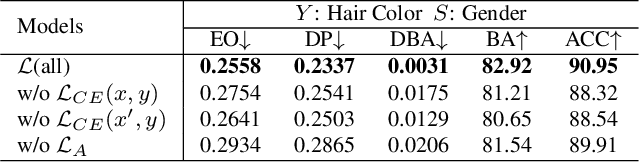
Vision Transformer (ViT) has recently gained significant interest in solving computer vision (CV) problems due to its capability of extracting informative features and modeling long-range dependencies through the self-attention mechanism. To fully realize the advantages of ViT in real-world applications, recent works have explored the trustworthiness of ViT, including its robustness and explainability. However, another desiderata, fairness has not yet been adequately addressed in the literature. We establish that the existing fairness-aware algorithms (primarily designed for CNNs) do not perform well on ViT. This necessitates the need for developing our novel framework via Debiased Self-Attention (DSA). DSA is a fairness-through-blindness approach that enforces ViT to eliminate spurious features correlated with the sensitive attributes for bias mitigation. Notably, adversarial examples are leveraged to locate and mask the spurious features in the input image patches. In addition, DSA utilizes an attention weights alignment regularizer in the training objective to encourage learning informative features for target prediction. Importantly, our DSA framework leads to improved fairness guarantees over prior works on multiple prediction tasks without compromising target prediction performance
Negative Flux Aggregation to Estimate Feature Attributions
Jan 17, 2023



There are increasing demands for understanding deep neural networks' (DNNs) behavior spurred by growing security and/or transparency concerns. Due to multi-layer nonlinearity of the deep neural network architectures, explaining DNN predictions still remains as an open problem, preventing us from gaining a deeper understanding of the mechanisms. To enhance the explainability of DNNs, we estimate the input feature's attributions to the prediction task using divergence and flux. Inspired by the divergence theorem in vector analysis, we develop a novel Negative Flux Aggregation (NeFLAG) formulation and an efficient approximation algorithm to estimate attribution map. Unlike the previous techniques, ours doesn't rely on fitting a surrogate model nor need any path integration of gradients. Both qualitative and quantitative experiments demonstrate a superior performance of NeFLAG in generating more faithful attribution maps than the competing methods.