 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLR-SGS: Robust LiDAR-Reflectance-Guided Salient Gaussian Splatting for Self-Driving Scene Reconstruction
Mar 13, 2026Recent 3D Gaussian Splatting (3DGS) methods have demonstrated the feasibility of self-driving scene reconstruction and novel view synthesis. However, most existing methods either rely solely on cameras or use LiDAR only for Gaussian initialization or depth supervision, while the rich scene information contained in point clouds, such as reflectance, and the complementarity between LiDAR and RGB have not been fully exploited, leading to degradation in challenging self-driving scenes, such as those with high ego-motion and complex lighting. To address these issues, we propose a robust and efficient LiDAR-reflectance-guided Salient Gaussian Splatting method (LR-SGS) for self-driving scenes, which introduces a structure-aware Salient Gaussian representation, initialized from geometric and reflectance feature points extracted from LiDAR and refined through a salient transform and improved density control to capture edge and planar structures. Furthermore, we calibrate LiDAR intensity into reflectance and attach it to each Gaussian as a lighting-invariant material channel, jointly aligned with RGB to enforce boundary consistency. Extensive experiments on the Waymo Open Dataset demonstrate that LR-SGS achieves superior reconstruction performance with fewer Gaussians and shorter training time. In particular, on Complex Lighting scenes, our method surpasses OmniRe by 1.18 dB PSNR.
WalkGPT: Grounded Vision-Language Conversation with Depth-Aware Segmentation for Pedestrian Navigation
Mar 11, 2026Ensuring accessible pedestrian navigation requires reasoning about both semantic and spatial aspects of complex urban scenes, a challenge that existing Large Vision-Language Models (LVLMs) struggle to meet. Although these models can describe visual content, their lack of explicit grounding leads to object hallucinations and unreliable depth reasoning, limiting their usefulness for accessibility guidance. We introduce WalkGPT, a pixel-grounded LVLM for the new task of Grounded Navigation Guide, unifying language reasoning and segmentation within a single architecture for depth-aware accessibility guidance. Given a pedestrian-view image and a navigation query, WalkGPT generates a conversational response with segmentation masks that delineate accessible and harmful features, along with relative depth estimation. The model incorporates a Multi-Scale Query Projector (MSQP) that shapes the final image tokens by aggregating them along text tokens across spatial hierarchies, and a Calibrated Text Projector (CTP), guided by a proposed Region Alignment Loss, that maps language embeddings into segmentation-aware representations. These components enable fine-grained grounding and depth inference without user-provided cues or anchor points, allowing the model to generate complete and realistic navigation guidance. We also introduce PAVE, a large-scale benchmark of 41k pedestrian-view images paired with accessibility-aware questions and depth-grounded answers. Experiments show that WalkGPT achieves strong grounded reasoning and segmentation performance. The source code and dataset are available on the \href{https://sites.google.com/view/walkgpt-26/home}{project website}.
LingLanMiDian: Systematic Evaluation of LLMs on TCM Knowledge and Clinical Reasoning
Feb 02, 2026Large language models (LLMs) are advancing rapidly in medical NLP, yet Traditional Chinese Medicine (TCM) with its distinctive ontology, terminology, and reasoning patterns requires domain-faithful evaluation. Existing TCM benchmarks are fragmented in coverage and scale and rely on non-unified or generation-heavy scoring that hinders fair comparison. We present the LingLanMiDian (LingLan) benchmark, a large-scale, expert-curated, multi-task suite that unifies evaluation across knowledge recall, multi-hop reasoning, information extraction, and real-world clinical decision-making. LingLan introduces a consistent metric design, a synonym-tolerant protocol for clinical labels, a per-dataset 400-item Hard subset, and a reframing of diagnosis and treatment recommendation into single-choice decision recognition. We conduct comprehensive, zero-shot evaluations on 14 leading open-source and proprietary LLMs, providing a unified perspective on their strengths and limitations in TCM commonsense knowledge understanding, reasoning, and clinical decision support; critically, the evaluation on Hard subset reveals a substantial gap between current models and human experts in TCM-specialized reasoning. By bridging fundamental knowledge and applied reasoning through standardized evaluation, LingLan establishes a unified, quantitative, and extensible foundation for advancing TCM LLMs and domain-specific medical AI research. All evaluation data and code are available at https://github.com/TCMAI-BJTU/LingLan and http://tcmnlp.com.
Automatic Calibration for Membership Inference Attack on Large Language Models
May 06, 2025



Membership Inference Attacks (MIAs) have recently been employed to determine whether a specific text was part of the pre-training data of Large Language Models (LLMs). However, existing methods often misinfer non-members as members, leading to a high false positive rate, or depend on additional reference models for probability calibration, which limits their practicality. To overcome these challenges, we introduce a novel framework called Automatic Calibration Membership Inference Attack (ACMIA), which utilizes a tunable temperature to calibrate output probabilities effectively. This approach is inspired by our theoretical insights into maximum likelihood estimation during the pre-training of LLMs. We introduce ACMIA in three configurations designed to accommodate different levels of model access and increase the probability gap between members and non-members, improving the reliability and robustness of membership inference. Extensive experiments on various open-source LLMs demonstrate that our proposed attack is highly effective, robust, and generalizable, surpassing state-of-the-art baselines across three widely used benchmarks. Our code is available at: \href{https://github.com/Salehzz/ACMIA}{\textcolor{blue}{Github}}.
BiPVL-Seg: Bidirectional Progressive Vision-Language Fusion with Global-Local Alignment for Medical Image Segmentation
Mar 30, 2025



Medical image segmentation typically relies solely on visual data, overlooking the rich textual information clinicians use for diagnosis. Vision-language models attempt to bridge this gap, but existing approaches often process visual and textual features independently, resulting in weak cross-modal alignment. Simple fusion techniques fail due to the inherent differences between spatial visual features and sequential text embeddings. Additionally, medical terminology deviates from general language, limiting the effectiveness of off-the-shelf text encoders and further hindering vision-language alignment. We propose BiPVL-Seg, an end-to-end framework that integrates vision-language fusion and embedding alignment through architectural and training innovations, where both components reinforce each other to enhance medical image segmentation. BiPVL-Seg introduces bidirectional progressive fusion in the architecture, which facilitates stage-wise information exchange between vision and text encoders. Additionally, it incorporates global-local contrastive alignment, a training objective that enhances the text encoder's comprehension by aligning text and vision embeddings at both class and concept levels. Extensive experiments on diverse medical imaging benchmarks across CT and MR modalities demonstrate BiPVL-Seg's superior performance when compared with state-of-the-art methods in complex multi-class segmentation. Source code is available in this GitHub repository.
Switchable deep beamformer for high-quality and real-time passive acoustic mapping
Dec 03, 2024
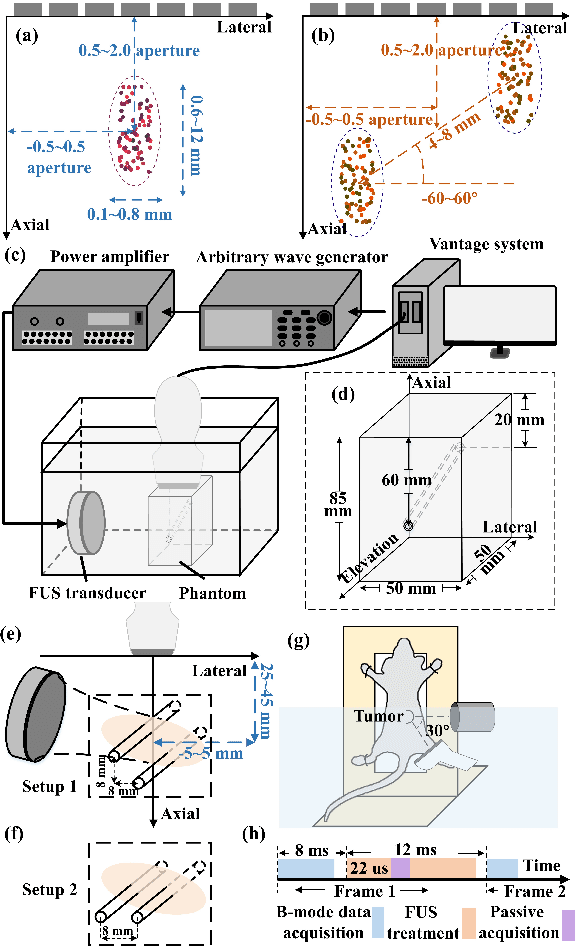
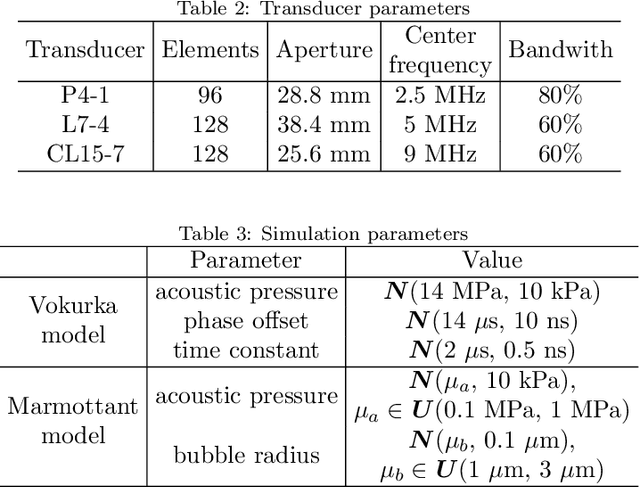
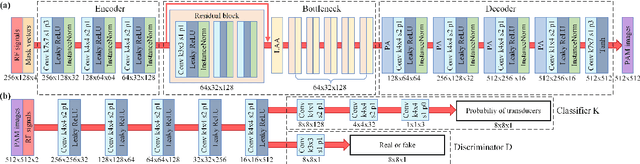
Passive acoustic mapping (PAM) is a promising tool for monitoring acoustic cavitation activities in the applications of ultrasound therapy. Data-adaptive beamformers for PAM have better image quality compared to the time exposure acoustics (TEA) algorithms. However, the computational cost of data-adaptive beamformers is considerably expensive. In this work, we develop a deep beamformer based on a generative adversarial network, which can switch between different transducer arrays and reconstruct high-quality PAM images directly from radio frequency ultrasound signals with low computational cost. The deep beamformer was trained on the dataset consisting of simulated and experimental cavitation signals of single and multiple microbubble clouds measured by different (linear and phased) arrays covering 1-15 MHz. We compared the performance of the deep beamformer to TEA and three different data-adaptive beamformers using the simulated and experimental test dataset. Compared with TEA, the deep beamformer reduced the energy spread area by 18.9%-65.0% and improved the image signal-to-noise ratio by 9.3-22.9 dB in average for the different arrays in our data. Compared to the data-adaptive beamformers, the deep beamformer reduced the computational cost by three orders of magnitude achieving 10.5 ms image reconstruction speed in our data, while the image quality was as good as that of the data-adaptive beamformers. These results demonstrated the potential of the deep beamformer for high-resolution monitoring of microbubble cavitation activities for ultrasound therapy.
MulModSeg: Enhancing Unpaired Multi-Modal Medical Image Segmentation with Modality-Conditioned Text Embedding and Alternating Training
Nov 23, 2024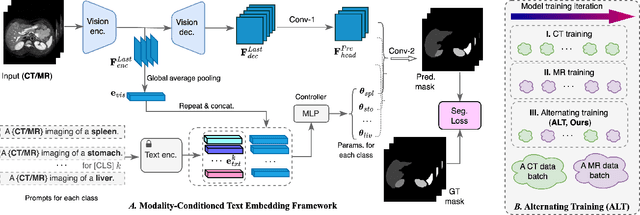
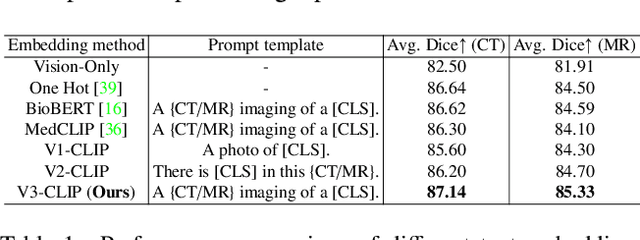
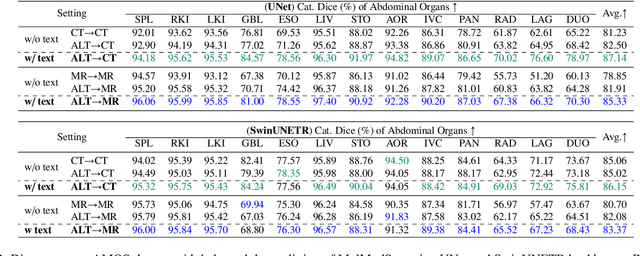
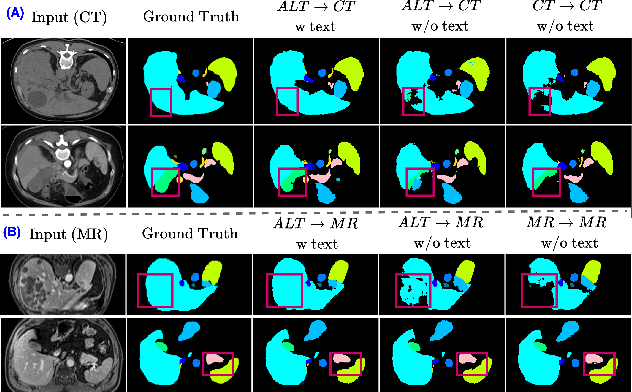
In the diverse field of medical imaging, automatic segmentation has numerous applications and must handle a wide variety of input domains, such as different types of Computed Tomography (CT) scans and Magnetic Resonance (MR) images. This heterogeneity challenges automatic segmentation algorithms to maintain consistent performance across different modalities due to the requirement for spatially aligned and paired images. Typically, segmentation models are trained using a single modality, which limits their ability to generalize to other types of input data without employing transfer learning techniques. Additionally, leveraging complementary information from different modalities to enhance segmentation precision often necessitates substantial modifications to popular encoder-decoder designs, such as introducing multiple branched encoding or decoding paths for each modality. In this work, we propose a simple Multi-Modal Segmentation (MulModSeg) strategy to enhance medical image segmentation across multiple modalities, specifically CT and MR. It incorporates two key designs: a modality-conditioned text embedding framework via a frozen text encoder that adds modality awareness to existing segmentation frameworks without significant structural modifications or computational overhead, and an alternating training procedure that facilitates the integration of essential features from unpaired CT and MR inputs. Through extensive experiments with both Fully Convolutional Network and Transformer-based backbones, MulModSeg consistently outperforms previous methods in segmenting abdominal multi-organ and cardiac substructures for both CT and MR modalities. The code is available in this {\href{https://github.com/ChengyinLee/MulModSeg_2024}{link}}.
Progressive Multi-Level Alignments for Semi-Supervised Domain Adaptation SAR Target Recognition Using Simulated Data
Nov 07, 2024Recently, an intriguing research trend for automatic target recognition (ATR) from synthetic aperture radar (SAR) imagery has arisen: using simulated data to train ATR models is a feasible solution to the issue of inadequate measured data. To close the domain gap that exists between the real and simulated data, the unsupervised domain adaptation (UDA) techniques are frequently exploited to construct ATR models. However, for UDA, the target domain lacks labeled data to direct the model training, posing a great challenge to ATR performance. To address the above problem, a semi-supervised domain adaptation (SSDA) framework has been proposed adopting progressive multi-level alignments for simulated data-aided SAR ATR. First, a progressive wavelet transform data augmentation (PWTDA) is presented by analyzing the discrepancies of wavelet decomposition sub-bands of two domain images, obtaining the domain-level alignment. Specifically, the domain gap is narrowed by mixing the wavelet transform high-frequency sub-band components. Second, we develop an asymptotic instance-prototype alignment (AIPA) strategy to push the source domain instances close to the corresponding target prototypes, aiming to achieve category-level alignment. Moreover, the consistency alignment is implemented by excavating the strong-weak augmentation consistency of both individual samples and the multi-sample relationship, enhancing the generalization capability of the model. Extensive experiments on the Synthetic and Measured Paired Labeled Experiment (SAMPLE) dataset, indicate that our approach obtains recognition accuracies of 99.63% and 98.91% in two common experimental settings with only one labeled sample per class of the target domain, outperforming the most advanced SSDA techniques.
GeoSAM: Fine-tuning SAM with Sparse and Dense Visual Prompting for Automated Segmentation of Mobility Infrastructure
Nov 19, 2023



The Segment Anything Model (SAM) has shown impressive performance when applied to natural image segmentation. However, it struggles with geographical images like aerial and satellite imagery, especially when segmenting mobility infrastructure including roads, sidewalks, and crosswalks. This inferior performance stems from the narrow features of these objects, their textures blending into the surroundings, and interference from objects like trees, buildings, vehicles, and pedestrians - all of which can disorient the model to produce inaccurate segmentation maps. To address these challenges, we propose Geographical SAM (GeoSAM), a novel SAM-based framework that implements a fine-tuning strategy using the dense visual prompt from zero-shot learning, and the sparse visual prompt from a pre-trained CNN segmentation model. The proposed GeoSAM outperforms existing approaches for geographical image segmentation, specifically by 20%, 14.29%, and 17.65% for road infrastructure, pedestrian infrastructure, and on average, respectively, representing a momentous leap in leveraging foundation models to segment mobility infrastructure including both road and pedestrian infrastructure in geographical images.
FAS-UNet: A Novel FAS-driven Unet to Learn Variational Image Segmentation
Nov 06, 2022
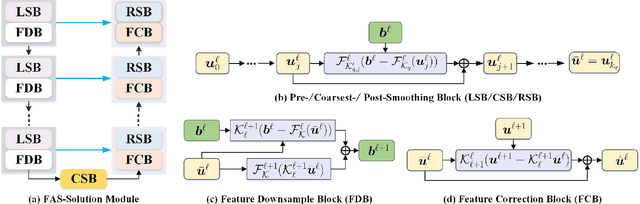
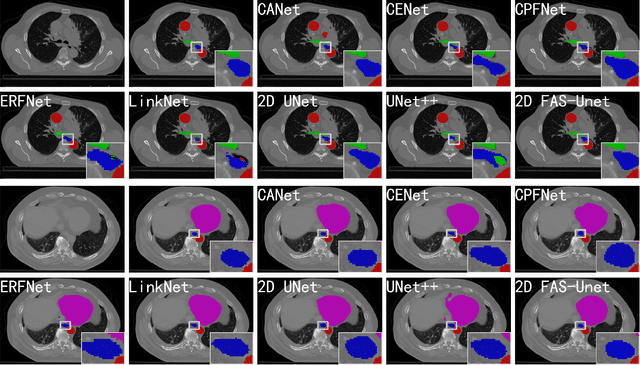
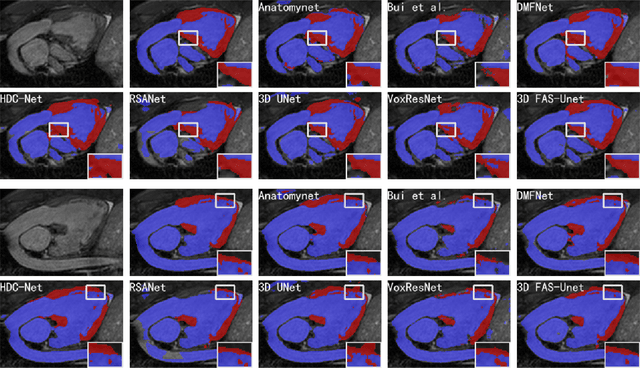
Solving variational image segmentation problems with hidden physics is often expensive and requires different algorithms and manually tunes model parameter. The deep learning methods based on the U-Net structure have obtained outstanding performances in many different medical image segmentation tasks, but designing such networks requires a lot of parameters and training data, not always available for practical problems. In this paper, inspired by traditional multi-phase convexity Mumford-Shah variational model and full approximation scheme (FAS) solving the nonlinear systems, we propose a novel variational-model-informed network (denoted as FAS-Unet) that exploits the model and algorithm priors to extract the multi-scale features. The proposed model-informed network integrates image data and mathematical models, and implements them through learning a few convolution kernels. Based on the variational theory and FAS algorithm, we first design a feature extraction sub-network (FAS-Solution module) to solve the model-driven nonlinear systems, where a skip-connection is employed to fuse the multi-scale features. Secondly, we further design a convolution block to fuse the extracted features from the previous stage, resulting in the final segmentation possibility. Experimental results on three different medical image segmentation tasks show that the proposed FAS-Unet is very competitive with other state-of-the-art methods in qualitative, quantitative and model complexity evaluations. Moreover, it may also be possible to train specialized network architectures that automatically satisfy some of the mathematical and physical laws in other image problems for better accuracy, faster training and improved generalization.The code is available at \url{https://github.com/zhuhui100/FASUNet}.