 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Fine-Grained Prototype Learning for Incomplete Image-Tabular Classification
Jun 03, 2026The missing-modality problem poses a significant challenge in image-tabular multimodal learning across a wide range of multimedia applications, including product understanding, recommendation systems, and medical diagnosis. This challenge is particularly pronounced when the two modalities are highly heterogeneous, as images and tabular attributes differ substantially in their semantic granularity and data distributions. Existing methods learn modality-invariant representations through disentanglement and alignment over global token-averaged features, capturing only coarse cross-modal consistency and overlooking fine-grained semantic and distributional misalignment, which hampers the exploitation of complementary cues under missing modalities. To address this, we propose DFPL, a novel framework for fine-grained prototype learning. Specifically, Shared-Specific Prototype Modeling (SSPM) extracts compact and diverse shared and modality-specific prototypes, and further performs prototype-level disentanglement to suppress redundant intra-modality correlations. Additionally, we propose a Prototype-guided Fine-grained Alignment (PFA) module that jointly enforces prototype-level distribution matching and prototype-to-class semantic alignment within a unified prototype space, thereby preserving both fine-grained distributional and semantic consistency across modalities. We further introduce a Class-aware Multi-scale Aggregation (CMA) module to adaptively aggregate shared semantics and modality-specific characteristics from global and prototype levels for robust predictions. Extensive experiments on three diverse image-tabular benchmarks demonstrate the superiority of our method compared to the previous approaches under various missing-modality settings. Code will be made publicly available.
3D Points Splatting for Real-Time Dynamic Hand Reconstruction
Dec 21, 2023We present 3D Points Splatting Hand Reconstruction (3D-PSHR), a real-time and photo-realistic hand reconstruction approach. We propose a self-adaptive canonical points upsampling strategy to achieve high-resolution hand geometry representation. This is followed by a self-adaptive deformation that deforms the hand from the canonical space to the target pose, adapting to the dynamic changing of canonical points which, in contrast to the common practice of subdividing the MANO model, offers greater flexibility and results in improved geometry fitting. To model texture, we disentangle the appearance color into the intrinsic albedo and pose-aware shading, which are learned through a Context-Attention module. Moreover, our approach allows the geometric and the appearance models to be trained simultaneously in an end-to-end manner. We demonstrate that our method is capable of producing animatable, photorealistic and relightable hand reconstructions using multiple datasets, including monocular videos captured with handheld smartphones and large-scale multi-view videos featuring various hand poses. We also demonstrate that our approach achieves real-time rendering speeds while simultaneously maintaining superior performance compared to existing state-of-the-art methods.
SMC-NCA: Semantic-guided Multi-level Contrast for Semi-supervised Action Segmentation
Dec 19, 2023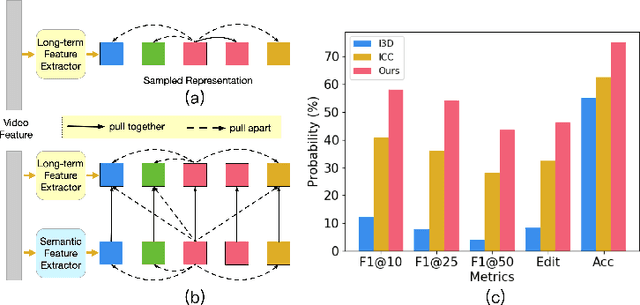

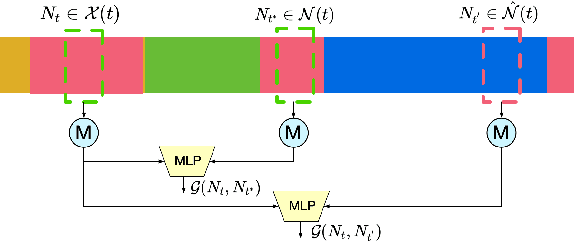

Semi-supervised action segmentation aims to perform frame-wise classification in long untrimmed videos, where only a fraction of videos in the training set have labels. Recent studies have shown the potential of contrastive learning in unsupervised representation learning using unlabelled data. However, learning the representation of each frame by unsupervised contrastive learning for action segmentation remains an open and challenging problem. In this paper, we propose a novel Semantic-guided Multi-level Contrast scheme with a Neighbourhood-Consistency-Aware unit (SMC-NCA) to extract strong frame-wise representations for semi-supervised action segmentation. Specifically, for representation learning, SMC is firstly used to explore intra- and inter-information variations in a unified and contrastive way, based on dynamic clustering process of the original input, encoded semantic and temporal features. Then, the NCA module, which is responsible for enforcing spatial consistency between neighbourhoods centered at different frames to alleviate over-segmentation issues, works alongside SMC for semi-supervised learning. Our SMC outperforms the other state-of-the-art methods on three benchmarks, offering improvements of up to 17.8% and 12.6% in terms of edit distance and accuracy, respectively. Additionally, the NCA unit results in significant better segmentation performance against the others in the presence of only 5% labelled videos. We also demonstrate the effectiveness of the proposed method on our Parkinson's Disease Mouse Behaviour (PDMB) dataset. The code and datasets will be made publicly available.
A Probabilistic Attention Model with Occlusion-aware Texture Regression for 3D Hand Reconstruction from a Single RGB Image
Apr 27, 2023Recently, deep learning based approaches have shown promising results in 3D hand reconstruction from a single RGB image. These approaches can be roughly divided into model-based approaches, which are heavily dependent on the model's parameter space, and model-free approaches, which require large numbers of 3D ground truths to reduce depth ambiguity and struggle in weakly-supervised scenarios. To overcome these issues, we propose a novel probabilistic model to achieve the robustness of model-based approaches and reduced dependence on the model's parameter space of model-free approaches. The proposed probabilistic model incorporates a model-based network as a prior-net to estimate the prior probability distribution of joints and vertices. An Attention-based Mesh Vertices Uncertainty Regression (AMVUR) model is proposed to capture dependencies among vertices and the correlation between joints and mesh vertices to improve their feature representation. We further propose a learning based occlusion-aware Hand Texture Regression model to achieve high-fidelity texture reconstruction. We demonstrate the flexibility of the proposed probabilistic model to be trained in both supervised and weakly-supervised scenarios. The experimental results demonstrate our probabilistic model's state-of-the-art accuracy in 3D hand and texture reconstruction from a single image in both training schemes, including in the presence of severe occlusions.
Cross-Skeleton Interaction Graph Aggregation Network for Representation Learning of Mouse Social Behaviour
Aug 07, 2022



Automated social behaviour analysis of mice has become an increasingly popular research area in behavioural neuroscience. Recently, pose information (i.e., locations of keypoints or skeleton) has been used to interpret social behaviours of mice. Nevertheless, effective encoding and decoding of social interaction information underlying the keypoints of mice has been rarely investigated in the existing methods. In particular, it is challenging to model complex social interactions between mice due to highly deformable body shapes and ambiguous movement patterns. To deal with the interaction modelling problem, we here propose a Cross-Skeleton Interaction Graph Aggregation Network (CS-IGANet) to learn abundant dynamics of freely interacting mice, where a Cross-Skeleton Node-level Interaction module (CS-NLI) is used to model multi-level interactions (i.e., intra-, inter- and cross-skeleton interactions). Furthermore, we design a novel Interaction-Aware Transformer (IAT) to dynamically learn the graph-level representation of social behaviours and update the node-level representation, guided by our proposed interaction-aware self-attention mechanism. Finally, to enhance the representation ability of our model, an auxiliary self-supervised learning task is proposed for measuring the similarity between cross-skeleton nodes. Experimental results on the standard CRMI13-Skeleton and our PDMB-Skeleton datasets show that our proposed model outperforms several other state-of-the-art approaches.
Hand-Based Person Identification using Global and Part-Aware Deep Feature Representation Learning
Jan 19, 2021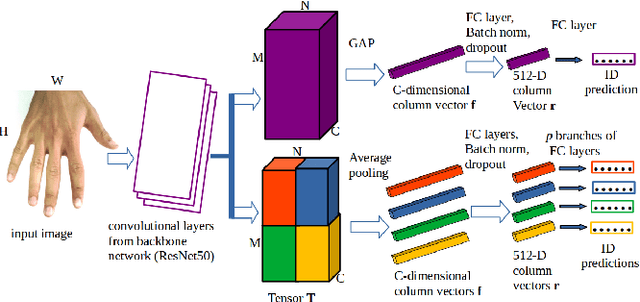

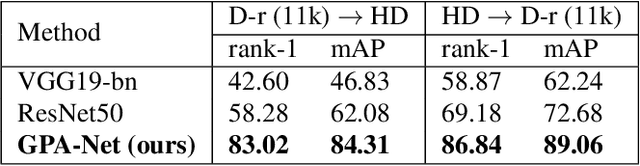

In cases of serious crime, including sexual abuse, often the only available information with demonstrated potential for identification is images of the hands. Since this evidence is captured in uncontrolled situations, it is difficult to analyse. As global approaches to feature comparison are limited in this case, it is important to extend to consider local information. In this work, we propose hand-based person identification by learning both global and local deep feature representation. Our proposed method, Global and Part-Aware Network (GPA-Net), creates global and local branches on the conv-layer for learning robust discriminative global and part-level features. For learning the local (part-level) features, we perform uniform partitioning on the conv-layer in both horizontal and vertical directions. We retrieve the parts by conducting a soft partition without explicitly partitioning the images or requiring external cues such as pose estimation. We make extensive evaluations on two large multi-ethnic and publicly available hand datasets, demonstrating that our proposed method significantly outperforms competing approaches.
Structured Context Enhancement Network for Mouse Pose Estimation
Dec 01, 2020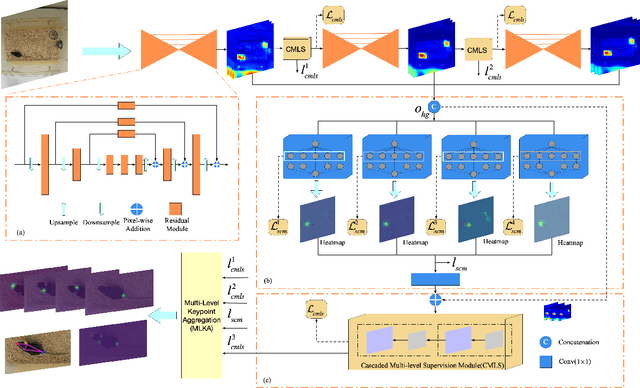
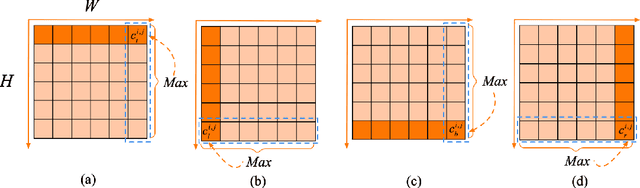
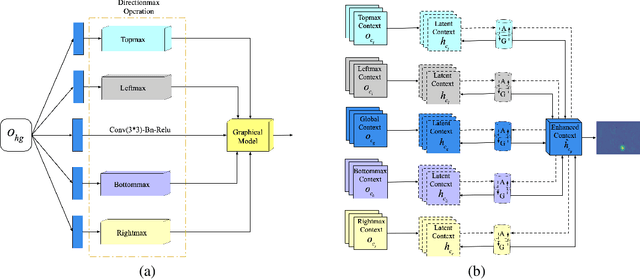
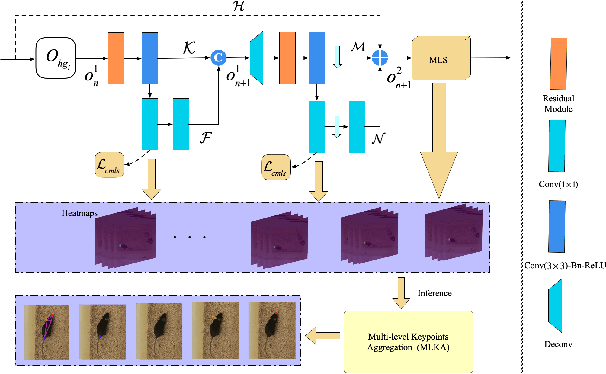
Automated analysis of mouse behaviours is crucial for many applications in neuroscience. However, quantifying mouse behaviours from videos or images remains a challenging problem, where pose estimation plays an important role in describing mouse behaviours. Although deep learning based methods have made promising advances in mouse or other animal pose estimation, they cannot properly handle complicated scenarios (e.g., occlusions, invisible keypoints, and abnormal poses). Particularly, since mouse body is highly deformable, it is a big challenge to accurately locate different keypoints on the mouse body. In this paper, we propose a novel hourglass network based model, namely Graphical Model based Structured Context Enhancement Network (GM-SCENet) where two effective modules, i.e., Structured Context Mixer (SCM) and Cascaded Multi-Level Supervision module (CMLS) are designed. The SCM can adaptively learn and enhance the proposed structured context information of each mouse part by a novel graphical model with close consideration on the difference between body parts. Then, the CMLS module is designed to jointly train the proposed SCM and the hourglass network by generating multi-level information, which increases the robustness of the whole network. Based on the multi-level predictions from the SCM and the CMLS module, we also propose an inference method to enhance the localization results. Finally, we evaluate our proposed approach against several baselines...
Muti-view Mouse Social Behaviour Recognition with Deep Graphical Model
Nov 04, 2020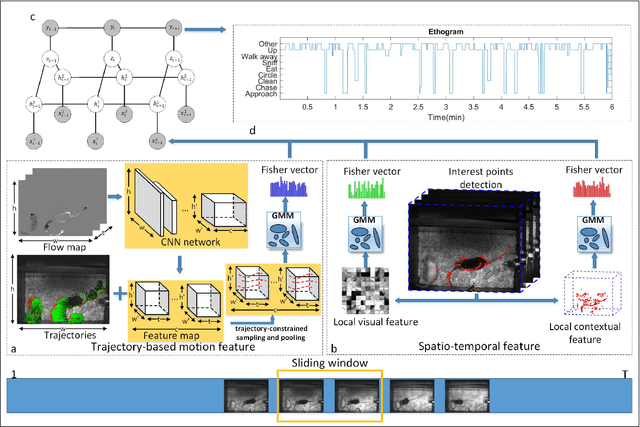


Home-cage social behaviour analysis of mice is an invaluable tool to assess therapeutic efficacy of neurodegenerative diseases. Despite tremendous efforts made within the research community, single-camera video recordings are mainly used for such analysis. Because of the potential to create rich descriptions of mouse social behaviors, the use of multi-view video recordings for rodent observations is increasingly receiving much attention. However, identifying social behaviours from various views is still challenging due to the lack of correspondence across data sources. To address this problem, we here propose a novel multiview latent-attention and dynamic discriminative model that jointly learns view-specific and view-shared sub-structures, where the former captures unique dynamics of each view whilst the latter encodes the interaction between the views. Furthermore, a novel multi-view latent-attention variational autoencoder model is introduced in learning the acquired features, enabling us to learn discriminative features in each view. Experimental results on the standard CRMI13 and our multi-view Parkinson's Disease Mouse Behaviour (PDMB) datasets demonstrate that our model outperforms the other state of the arts technologies and effectively deals with the imbalanced data problem.
Perceptual underwater image enhancement with deep learning and physical priors
Sep 26, 2020
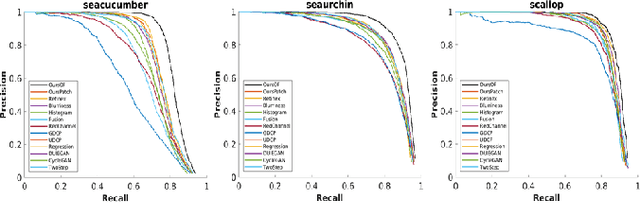
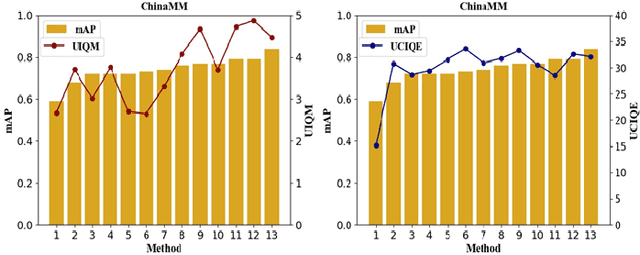
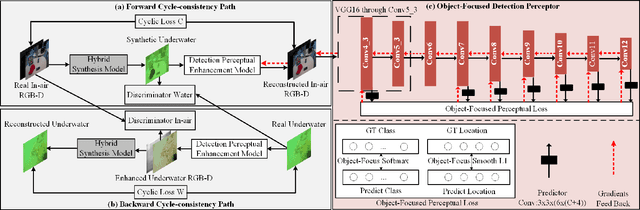
Underwater image enhancement, as a pre-processing step to improve the accuracy of the following object detection task, has drawn considerable attention in the field of underwater navigation and ocean exploration. However, most of the existing underwater image enhancement strategies tend to consider enhancement and detection as two independent modules with no interaction, and the practice of separate optimization does not always help the underwater object detection task. In this paper, we propose two perceptual enhancement models, each of which uses a deep enhancement model with a detection perceptor. The detection perceptor provides coherent information in the form of gradients to the enhancement model, guiding the enhancement model to generate patch level visually pleasing images or detection favourable images. In addition, due to the lack of training data, a hybrid underwater image synthesis model, which fuses physical priors and data-driven cues, is proposed to synthesize training data and generalise our enhancement model for real-world underwater images. Experimental results show the superiority of our proposed method over several state-of-the-art methods on both real-world and synthetic underwater datasets.
Deep Learning Based Brain Tumor Segmentation: A Survey
Jul 21, 2020
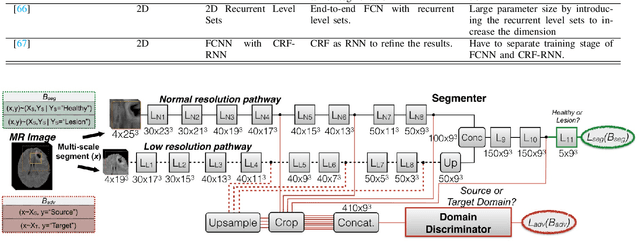

Brain tumor segmentation is a challenging problem in medical image analysis. The goal of brain tumor segmentation is to generate accurate delineation of brain tumor regions with correctly located masks. In recent years, deep learning methods have shown very promising performance in solving various computer vision problems, such as image classification, object detection and semantic segmentation. A number of deep learning based methods have been applied to brain tumor segmentation and achieved impressive system performance. Considering state-of-the-art technologies and their performance, the purpose of this paper is to provide a comprehensive survey of recently developed deep learning based brain tumor segmentation techniques. The established works included in this survey extensively cover technical aspects such as the strengths and weaknesses of different approaches, pre- and post-processing frameworks, datasets and evaluation metrics. Finally, we conclude this survey by discussing the potential development in future research work.