 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSleepGMUformer: A gated multimodal temporal neural network for sleep staging
Feb 20, 2025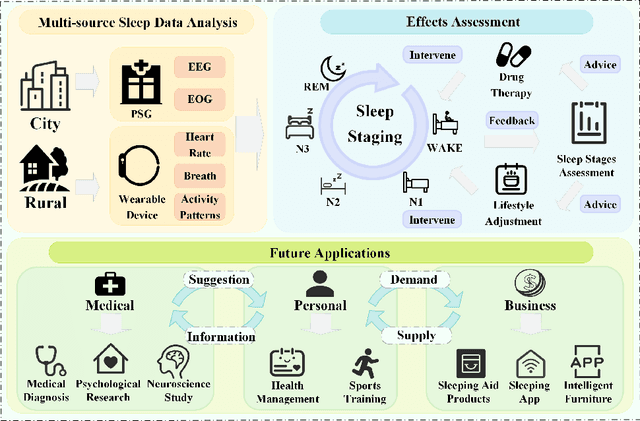

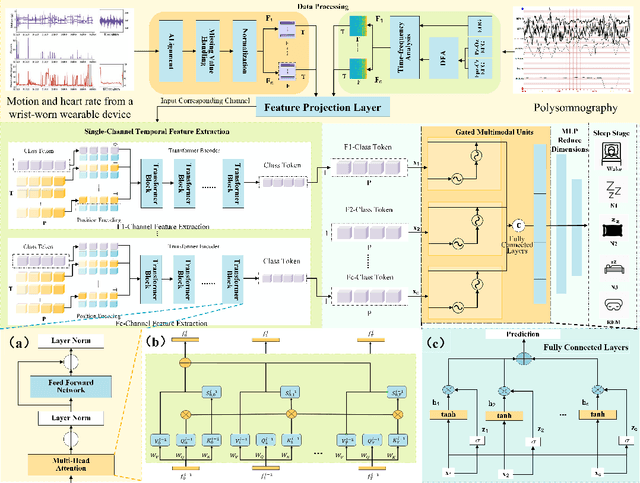

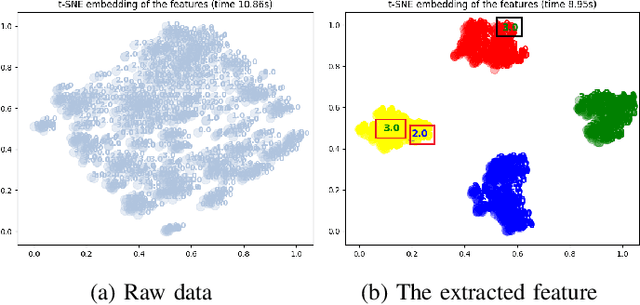
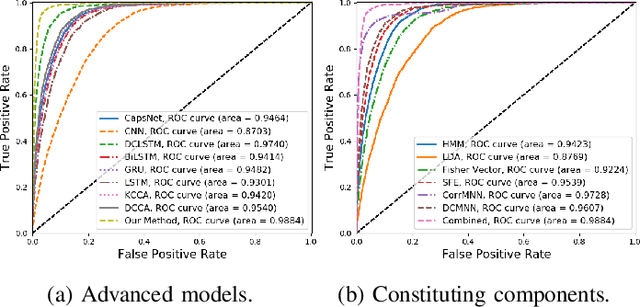
Sleep staging is a key method for assessing sleep quality and diagnosing sleep disorders. However, current deep learning methods face challenges: 1) postfusion techniques ignore the varying contributions of different modalities; 2) unprocessed sleep data can interfere with frequency-domain information. To tackle these issues, this paper proposes a gated multimodal temporal neural network for multidomain sleep data, including heart rate, motion, steps, EEG (Fpz-Cz, Pz-Oz), and EOG from WristHR-Motion-Sleep and SleepEDF-78. The model integrates: 1) a pre-processing module for feature alignment, missing value handling, and EEG de-trending; 2) a feature extraction module for complex sleep features in the time dimension; and 3) a dynamic fusion module for real-time modality weighting.Experiments show classification accuracies of 85.03% on SleepEDF-78 and 94.54% on WristHR-Motion-Sleep datasets. The model handles heterogeneous datasets and outperforms state-of-the-art models by 1.00%-4.00%.
Multimodal Gait Recognition for Neurodegenerative Diseases
Jan 07, 2021
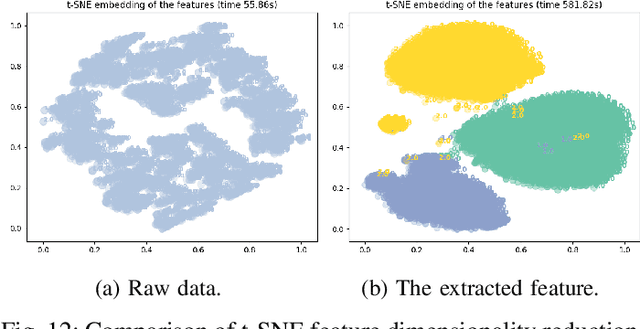
In recent years, single modality based gait recognition has been extensively explored in the analysis of medical images or other sensory data, and it is recognised that each of the established approaches has different strengths and weaknesses. As an important motor symptom, gait disturbance is usually used for diagnosis and evaluation of diseases; moreover, the use of multi-modality analysis of the patient's walking pattern compensates for the one-sidedness of single modality gait recognition methods that only learn gait changes in a single measurement dimension. The fusion of multiple measurement resources has demonstrated promising performance in the identification of gait patterns associated with individual diseases. In this paper, as a useful tool, we propose a novel hybrid model to learn the gait differences between three neurodegenerative diseases, between patients with different severity levels of Parkinson's disease and between healthy individuals and patients, by fusing and aggregating data from multiple sensors. A spatial feature extractor (SFE) is applied to generating representative features of images or signals. In order to capture temporal information from the two modality data, a new correlative memory neural network (CorrMNN) architecture is designed for extracting temporal features. Afterwards, we embed a multi-switch discriminator to associate the observations with individual state estimations. Compared with several state-of-the-art techniques, our proposed framework shows more accurate classification results.
Associated Spatio-Temporal Capsule Network for Gait Recognition
Jan 07, 2021
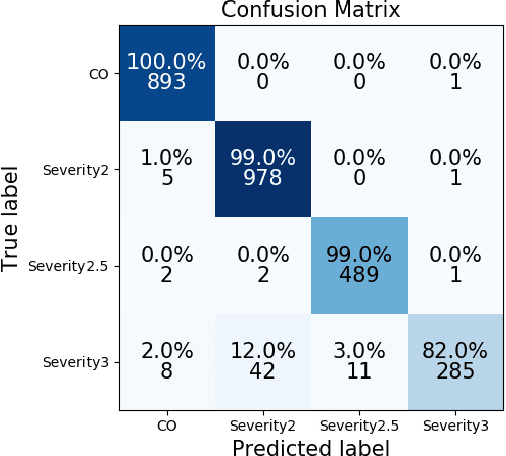
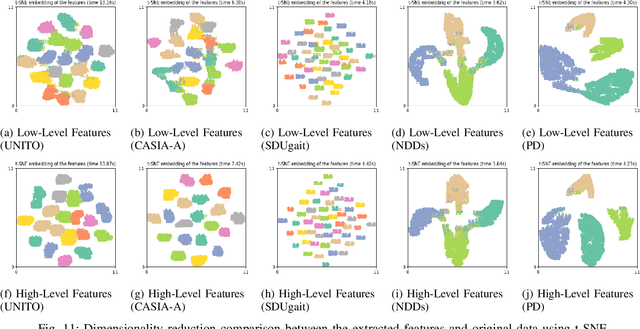
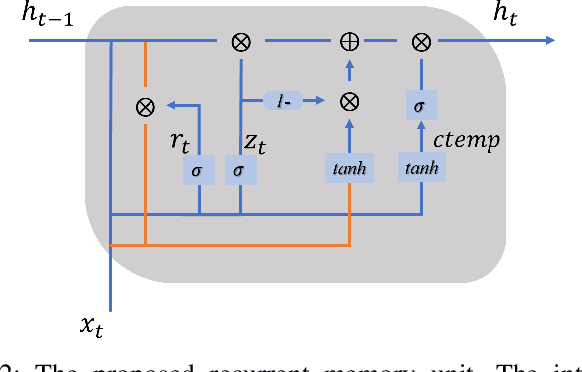
It is a challenging task to identify a person based on her/his gait patterns. State-of-the-art approaches rely on the analysis of temporal or spatial characteristics of gait, and gait recognition is usually performed on single modality data (such as images, skeleton joint coordinates, or force signals). Evidence has shown that using multi-modality data is more conducive to gait research. Therefore, we here establish an automated learning system, with an associated spatio-temporal capsule network (ASTCapsNet) trained on multi-sensor datasets, to analyze multimodal information for gait recognition. Specifically, we first design a low-level feature extractor and a high-level feature extractor for spatio-temporal feature extraction of gait with a novel recurrent memory unit and a relationship layer. Subsequently, a Bayesian model is employed for the decision-making of class labels. Extensive experiments on several public datasets (normal and abnormal gait) validate the effectiveness of the proposed ASTCapsNet, compared against several state-of-the-art methods.
Muti-view Mouse Social Behaviour Recognition with Deep Graphical Model
Nov 04, 2020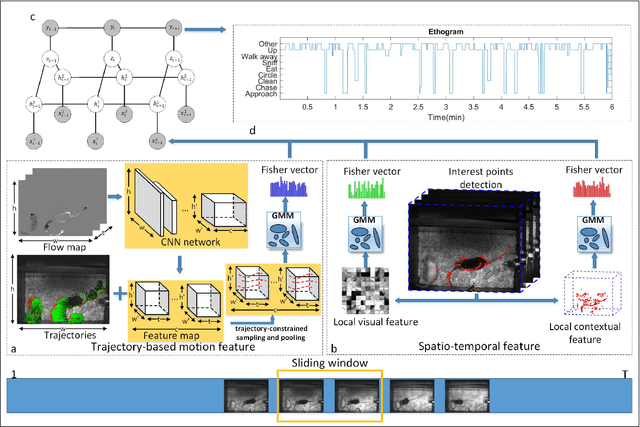

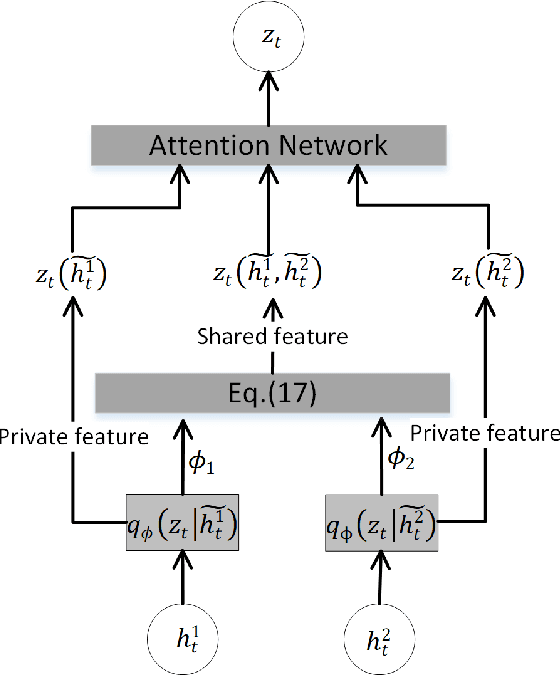

Home-cage social behaviour analysis of mice is an invaluable tool to assess therapeutic efficacy of neurodegenerative diseases. Despite tremendous efforts made within the research community, single-camera video recordings are mainly used for such analysis. Because of the potential to create rich descriptions of mouse social behaviors, the use of multi-view video recordings for rodent observations is increasingly receiving much attention. However, identifying social behaviours from various views is still challenging due to the lack of correspondence across data sources. To address this problem, we here propose a novel multiview latent-attention and dynamic discriminative model that jointly learns view-specific and view-shared sub-structures, where the former captures unique dynamics of each view whilst the latter encodes the interaction between the views. Furthermore, a novel multi-view latent-attention variational autoencoder model is introduced in learning the acquired features, enabling us to learn discriminative features in each view. Experimental results on the standard CRMI13 and our multi-view Parkinson's Disease Mouse Behaviour (PDMB) datasets demonstrate that our model outperforms the other state of the arts technologies and effectively deals with the imbalanced data problem.
Perceptual underwater image enhancement with deep learning and physical priors
Sep 26, 2020
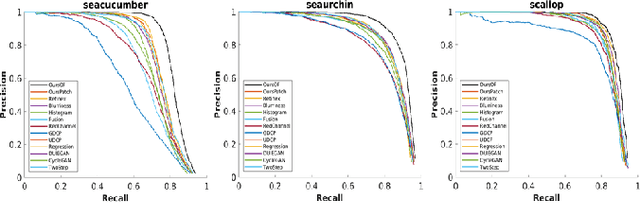
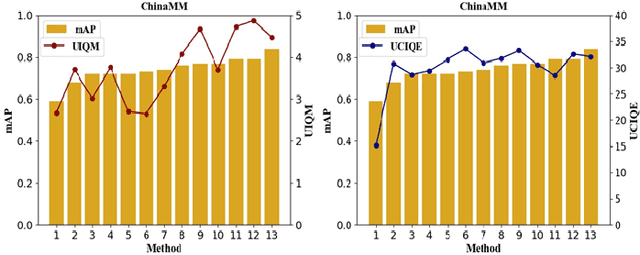
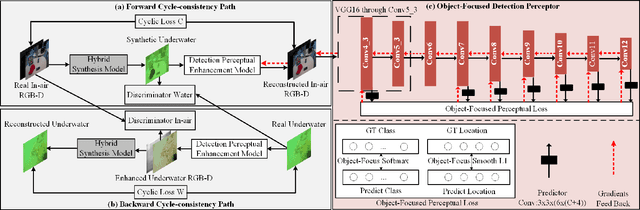
Underwater image enhancement, as a pre-processing step to improve the accuracy of the following object detection task, has drawn considerable attention in the field of underwater navigation and ocean exploration. However, most of the existing underwater image enhancement strategies tend to consider enhancement and detection as two independent modules with no interaction, and the practice of separate optimization does not always help the underwater object detection task. In this paper, we propose two perceptual enhancement models, each of which uses a deep enhancement model with a detection perceptor. The detection perceptor provides coherent information in the form of gradients to the enhancement model, guiding the enhancement model to generate patch level visually pleasing images or detection favourable images. In addition, due to the lack of training data, a hybrid underwater image synthesis model, which fuses physical priors and data-driven cues, is proposed to synthesize training data and generalise our enhancement model for real-world underwater images. Experimental results show the superiority of our proposed method over several state-of-the-art methods on both real-world and synthetic underwater datasets.