 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Domain Learning with Global Expert Mapping
Apr 20, 2026Human perception generalizes well across different domains, but most vision models struggle beyond their training data. This gap motivates multi-dataset learning, where a single model is trained on diverse datasets to improve robustness under domain shifts. However, unified training remains challenging due to inconsistencies in data distributions and label semantics. Mixture-of-Experts (MoE) models provide a scalable solution by routing inputs to specialized subnetworks (experts). Yet, existing MoEs often fail to specialize effectively, as their load-balancing mechanisms enforce uniform input distribution across experts. This fairness conflicts with domain-aware routing, causing experts to learn redundant representations, and reducing performance especially on rare or out-of-distribution domains. We propose GEM (Global Expert Mapping), a planner-compiler framework that replaces the learned router with a global scheduler. Our planner, based on linear programming relaxation, computes a fractional assignment of datasets to experts, while the compiler applies hierarchical rounding to convert this soft plan into a deterministic, capacity-aware mapping. Unlike prior MoEs, GEM avoids balancing loss, resolves the conflict between fairness and specialization, and produces interpretable routing. Experiments show that GEM-DINO achieves state-of-the-art performance on the UODB benchmark, with notable gains on underrepresented datasets and solves task interference in few-shot adaptation scenarios.
Physically-Guided Optical Inversion Enable Non-Contact Side-Channel Attack on Isolated Screens
Apr 15, 2026Noncontact exfiltration of electronic screen content poses a security challenge, with side-channel incursions as the principal vector. We introduce an optical projection side-channel paradigm that confronts two core instabilities: (i) the near-singular Jacobian spectrum of projection mapping breaches Hadamard stability, rendering inversion hypersensitive to perturbations; (ii) irreversible compression in light transport obliterates global semantic cues, magnifying reconstruction ambiguity. Exploiting passive speckle patterns formed by diffuse reflection, our Irradiance Robust Radiometric Inversion Network (IR4Net) fuses a Physically Regularized Irradiance Approximation (PRIrr-Approximation), which embeds the radiative transfer equation in a learnable optimizer, with a contour-to-detail cross-scale reconstruction mechanism that arrests noise propagation. Moreover, an Irreversibility Constrained Semantic Reprojection (ICSR) module reinstates lost global structure through context-driven semantic mapping. Evaluated across four scene categories, IR4Net achieves fidelity beyond competing neural approaches while retaining resilience to illumination perturbations.
Physically-Grounded Manifold Projection Model for Generalizable Metal Artifact Reduction in Dental CBCT
Jan 01, 2026Metal artifacts in Dental CBCT severely obscure anatomical structures, hindering diagnosis. Current deep learning for Metal Artifact Reduction (MAR) faces limitations: supervised methods suffer from spectral blurring due to "regression-to-the-mean", while unsupervised ones risk structural hallucinations. Denoising Diffusion Models (DDPMs) offer realism but rely on slow, stochastic iterative sampling, unsuitable for clinical use. To resolve this, we propose the Physically-Grounded Manifold Projection (PGMP) framework. First, our Anatomically-Adaptive Physics Simulation (AAPS) pipeline synthesizes high-fidelity training pairs via Monte Carlo spectral modeling and patient-specific digital twins, bridging the synthetic-to-real gap. Second, our DMP-Former adapts the Direct x-Prediction paradigm, reformulating restoration as a deterministic manifold projection to recover clean anatomy in a single forward pass, eliminating stochastic sampling. Finally, a Semantic-Structural Alignment (SSA) module anchors the solution using priors from medical foundation models (MedDINOv3), ensuring clinical plausibility. Experiments on synthetic and multi-center clinical datasets show PGMP outperforms state-of-the-art methods on unseen anatomy, setting new benchmarks in efficiency and diagnostic reliability. Code and data: https://github.com/ricoleehduu/PGMP.
Physically-Grounded Manifold Projection with Foundation Priors for Metal Artifact Reduction in Dental CBCT
Dec 30, 2025Metal artifacts in Dental CBCT severely obscure anatomical structures, hindering diagnosis. Current deep learning for Metal Artifact Reduction (MAR) faces limitations: supervised methods suffer from spectral blurring due to "regression-to-the-mean", while unsupervised ones risk structural hallucinations. Denoising Diffusion Models (DDPMs) offer realism but rely on slow, stochastic iterative sampling, unsuitable for clinical use. To resolve this, we propose the Physically-Grounded Manifold Projection (PGMP) framework. First, our Anatomically-Adaptive Physics Simulation (AAPS) pipeline synthesizes high-fidelity training pairs via Monte Carlo spectral modeling and patient-specific digital twins, bridging the synthetic-to-real gap. Second, our DMP-Former adapts the Direct x-Prediction paradigm, reformulating restoration as a deterministic manifold projection to recover clean anatomy in a single forward pass, eliminating stochastic sampling. Finally, a Semantic-Structural Alignment (SSA) module anchors the solution using priors from medical foundation models (MedDINOv3), ensuring clinical plausibility. Experiments on synthetic and multi-center clinical datasets show PGMP outperforms state-of-the-art methods on unseen anatomy, setting new benchmarks in efficiency and diagnostic reliability. Code and data: https://github.com/ricoleehduu/PGMP
PFed-Signal: An ADR Prediction Model based on Federated Learning
Dec 29, 2025The adverse drug reactions (ADRs) predicted based on the biased records in FAERS (U.S. Food and Drug Administration Adverse Event Reporting System) may mislead diagnosis online. Generally, such problems are solved by optimizing reporting odds ratio (ROR) or proportional reporting ratio (PRR). However, these methods that rely on statistical methods cannot eliminate the biased data, leading to inaccurate signal prediction. In this paper, we propose PFed-signal, a federated learning-based signal prediction model of ADR, which utilizes the Euclidean distance to eliminate the biased data from FAERS, thereby improving the accuracy of ADR prediction. Specifically, we first propose Pfed-Split, a method to split the original dataset into a split dataset based on ADR. Then we propose ADR-signal, an ADR prediction model, including a biased data identification method based on federated learning and an ADR prediction model based on Transformer. The former identifies the biased data according to the Euclidean distance and generates a clean dataset by deleting the biased data. The latter is an ADR prediction model based on Transformer trained on the clean data set. The results show that the ROR and PRR on the clean dataset are better than those of the traditional methods. Furthermore, the accuracy rate, F1 score, recall rate and AUC of PFed-Signal are 0.887, 0.890, 0.913 and 0.957 respectively, which are higher than the baselines.
Multi-Label Transfer Learning in Non-Stationary Data Streams
Sep 09, 2025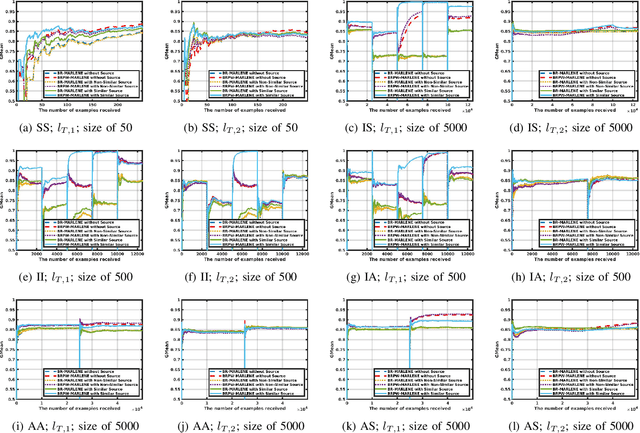



Label concepts in multi-label data streams often experience drift in non-stationary environments, either independently or in relation to other labels. Transferring knowledge between related labels can accelerate adaptation, yet research on multi-label transfer learning for data streams remains limited. To address this, we propose two novel transfer learning methods: BR-MARLENE leverages knowledge from different labels in both source and target streams for multi-label classification; BRPW-MARLENE builds on this by explicitly modelling and transferring pairwise label dependencies to enhance learning performance. Comprehensive experiments show that both methods outperform state-of-the-art multi-label stream approaches in non-stationary environments, demonstrating the effectiveness of inter-label knowledge transfer for improved predictive performance.
MARLINE: Multi-Source Mapping Transfer Learning for Non-Stationary Environments
Sep 09, 2025



Concept drift is a major problem in online learning due to its impact on the predictive performance of data stream mining systems. Recent studies have started exploring data streams from different sources as a strategy to tackle concept drift in a given target domain. These approaches make the assumption that at least one of the source models represents a concept similar to the target concept, which may not hold in many real-world scenarios. In this paper, we propose a novel approach called Multi-source mApping with tRansfer LearnIng for Non-stationary Environments (MARLINE). MARLINE can benefit from knowledge from multiple data sources in non-stationary environments even when source and target concepts do not match. This is achieved by projecting the target concept to the space of each source concept, enabling multiple source sub-classifiers to contribute towards the prediction of the target concept as part of an ensemble. Experiments on several synthetic and real-world datasets show that MARLINE was more accurate than several state-of-the-art data stream learning approaches.
SliceSemOcc: Vertical Slice Based Multimodal 3D Semantic Occupancy Representation
Sep 04, 2025Driven by autonomous driving's demands for precise 3D perception, 3D semantic occupancy prediction has become a pivotal research topic. Unlike bird's-eye-view (BEV) methods, which restrict scene representation to a 2D plane, occupancy prediction leverages a complete 3D voxel grid to model spatial structures in all dimensions, thereby capturing semantic variations along the vertical axis. However, most existing approaches overlook height-axis information when processing voxel features. And conventional SENet-style channel attention assigns uniform weight across all height layers, limiting their ability to emphasize features at different heights. To address these limitations, we propose SliceSemOcc, a novel vertical slice based multimodal framework for 3D semantic occupancy representation. Specifically, we extract voxel features along the height-axis using both global and local vertical slices. Then, a global local fusion module adaptively reconciles fine-grained spatial details with holistic contextual information. Furthermore, we propose the SEAttention3D module, which preserves height-wise resolution through average pooling and assigns dynamic channel attention weights to each height layer. Extensive experiments on nuScenes-SurroundOcc and nuScenes-OpenOccupancy datasets verify that our method significantly enhances mean IoU, achieving especially pronounced gains on most small-object categories. Detailed ablation studies further validate the effectiveness of the proposed SliceSemOcc framework.
SLENet: A Guidance-Enhanced Network for Underwater Camouflaged Object Detection
Sep 04, 2025
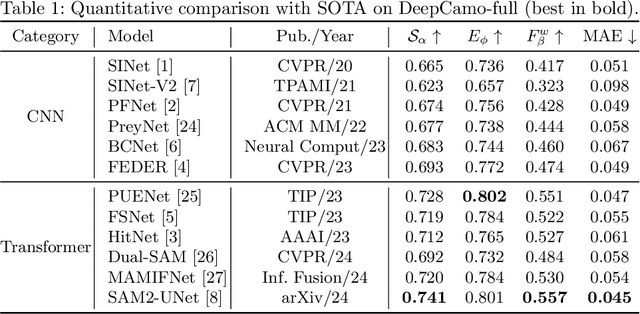

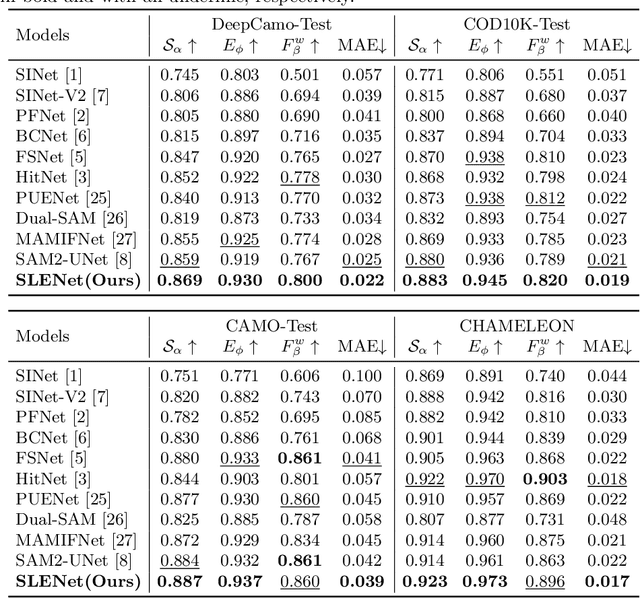
Underwater Camouflaged Object Detection (UCOD) aims to identify objects that blend seamlessly into underwater environments. This task is critically important to marine ecology. However, it remains largely underexplored and accurate identification is severely hindered by optical distortions, water turbidity, and the complex traits of marine organisms. To address these challenges, we introduce the UCOD task and present DeepCamo, a benchmark dataset designed for this domain. We also propose Semantic Localization and Enhancement Network (SLENet), a novel framework for UCOD. We first benchmark state-of-the-art COD models on DeepCamo to reveal key issues, upon which SLENet is built. In particular, we incorporate Gamma-Asymmetric Enhancement (GAE) module and a Localization Guidance Branch (LGB) to enhance multi-scale feature representation while generating a location map enriched with global semantic information. This map guides the Multi-Scale Supervised Decoder (MSSD) to produce more accurate predictions. Experiments on our DeepCamo dataset and three benchmark COD datasets confirm SLENet's superior performance over SOTA methods, and underscore its high generality for the broader COD task.
Power allocation for cell-free MIMO integrated sensing and communication
May 26, 2025


In this paper, we investigate integrated sensing and communication (ISAC) in a cell-free (CF) multiple-input multiple-output (MIMO) network with single-antenna access points (APs), where each AP functions either as a transmitter for both sensing and communication or as a receiver for target-reflected signals. We derive closed-form Cramer-Rao lower bounds (CRLBs) for location and velocity estimation under arbitrary power allocation ratios, assuming the radar cross-section (RCS) is deterministic and unknown over the observation interval. A power allocation optimization problem is formulated to maximize the communication signal-to-interference-plus-noise ratio (SINR), subject to CRLB-based sensing constraints and per-transmitter power limits. To solve the resulting nonlinear and non-convex problem, we propose a penalty function and projection-based modified conjugate gradient algorithm with inexact line search (PP-MCG-ILS), and an alternative method based on a modified steepest descent approach (PP-MSD-ILS). Additionally, for power minimization in pure sensing scenarios, we introduce a penalty function-based normalized conjugate gradient algorithm (P-NCG-ILS). We analyze the convergence behavior and qualitatively compare the computational complexity of the proposed algorithms. Simulation results confirm the accuracy of the derived CRLBs and demonstrate the effectiveness of the proposed power allocation strategies in enhancing both sensing and overall ISAC performance.