 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Closer! An Adversarial Parametric Editing Framework for Hallucination Mitigation in VLMs
Dec 26, 2025While Vision-Language Models (VLMs) have garnered increasing attention in the AI community due to their promising practical applications, they exhibit persistent hallucination issues, generating outputs misaligned with visual inputs. Recent studies attribute these hallucinations to VLMs' over-reliance on linguistic priors and insufficient visual feature integration, proposing heuristic decoding calibration strategies to mitigate them. However, the non-trainable nature of these strategies inherently limits their optimization potential. To this end, we propose an adversarial parametric editing framework for Hallucination mitigation in VLMs, which follows an \textbf{A}ctivate-\textbf{L}ocate-\textbf{E}dit \textbf{A}dversarially paradigm. Specifically, we first construct an activation dataset that comprises grounded responses (positive samples attentively anchored in visual features) and hallucinatory responses (negative samples reflecting LLM prior bias and internal knowledge artifacts). Next, we identify critical hallucination-prone parameter clusters by analyzing differential hidden states of response pairs. Then, these clusters are fine-tuned using prompts injected with adversarial tuned prefixes that are optimized to maximize visual neglect, thereby forcing the model to prioritize visual evidence over inherent parametric biases. Evaluations on both generative and discriminative VLM tasks demonstrate the significant effectiveness of ALEAHallu in alleviating hallucinations. Our code is available at https://github.com/hujiayu1223/ALEAHallu.
Power allocation for cell-free MIMO integrated sensing and communication
May 26, 2025


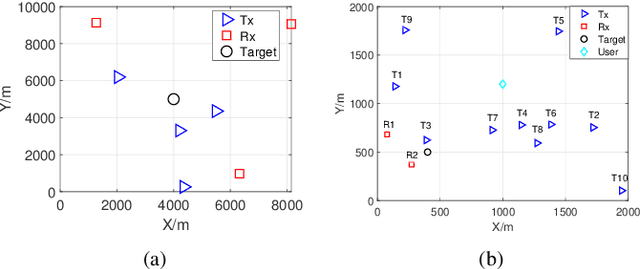
In this paper, we investigate integrated sensing and communication (ISAC) in a cell-free (CF) multiple-input multiple-output (MIMO) network with single-antenna access points (APs), where each AP functions either as a transmitter for both sensing and communication or as a receiver for target-reflected signals. We derive closed-form Cramer-Rao lower bounds (CRLBs) for location and velocity estimation under arbitrary power allocation ratios, assuming the radar cross-section (RCS) is deterministic and unknown over the observation interval. A power allocation optimization problem is formulated to maximize the communication signal-to-interference-plus-noise ratio (SINR), subject to CRLB-based sensing constraints and per-transmitter power limits. To solve the resulting nonlinear and non-convex problem, we propose a penalty function and projection-based modified conjugate gradient algorithm with inexact line search (PP-MCG-ILS), and an alternative method based on a modified steepest descent approach (PP-MSD-ILS). Additionally, for power minimization in pure sensing scenarios, we introduce a penalty function-based normalized conjugate gradient algorithm (P-NCG-ILS). We analyze the convergence behavior and qualitatively compare the computational complexity of the proposed algorithms. Simulation results confirm the accuracy of the derived CRLBs and demonstrate the effectiveness of the proposed power allocation strategies in enhancing both sensing and overall ISAC performance.
Cell-Free MIMO-ISAC: Joint Location and Velocity Estimation and Fundamental CRLB Analysis
Mar 09, 2025This paper investigates joint location and velocity estimation, along with their fundamental performance bounds analysis, in a cell-free multi-input multi-output (MIMO) integrated sensing and communication (ISAC) system. First, unlike existing studies that derive likelihood functions for target parameter estimation using continuous received signals, we formulate the maximum likelihood estimation (MLE) for radar sensing based on discrete received signals at a given sampling rate. Second, leveraging the proposed MLEs, we derive closed-form Cramer-Rao lower bounds (CRLBs) for joint location and velocity estimation in both single-target and multiple-target scenarios. Third, to enhance computational efficiency, we propose approximate CRLBs and conduct an in-depth accuracy analysis. Additionally, we thoroughly examine the impact of sampling rate, squared effective bandwidth, and time width on CRLB performance. For multiple-target scenarios, the concepts of safety distance and safety velocity are introduced to characterize conditions under which the CRLBs for multiple targets converge to their single target counterparts. Finally, extensive simulations are conducted to verify the accuracy of the proposed CRLBs and the theoretical results using state-of-the-art waveforms, namely orthogonal frequency division multiplexing (OFDM) and orthogonal chirp division multiplexing (OCDM).
DuSSS: Dual Semantic Similarity-Supervised Vision-Language Model for Semi-Supervised Medical Image Segmentation
Dec 17, 2024



Semi-supervised medical image segmentation (SSMIS) uses consistency learning to regularize model training, which alleviates the burden of pixel-wise manual annotations. However, it often suffers from error supervision from low-quality pseudo labels. Vision-Language Model (VLM) has great potential to enhance pseudo labels by introducing text prompt guided multimodal supervision information. It nevertheless faces the cross-modal problem: the obtained messages tend to correspond to multiple targets. To address aforementioned problems, we propose a Dual Semantic Similarity-Supervised VLM (DuSSS) for SSMIS. Specifically, 1) a Dual Contrastive Learning (DCL) is designed to improve cross-modal semantic consistency by capturing intrinsic representations within each modality and semantic correlations across modalities. 2) To encourage the learning of multiple semantic correspondences, a Semantic Similarity-Supervision strategy (SSS) is proposed and injected into each contrastive learning process in DCL, supervising semantic similarity via the distribution-based uncertainty levels. Furthermore, a novel VLM-based SSMIS network is designed to compensate for the quality deficiencies of pseudo-labels. It utilizes the pretrained VLM to generate text prompt guided supervision information, refining the pseudo label for better consistency regularization. Experimental results demonstrate that our DuSSS achieves outstanding performance with Dice of 82.52%, 74.61% and 78.03% on three public datasets (QaTa-COV19, BM-Seg and MoNuSeg).