 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Closer! An Adversarial Parametric Editing Framework for Hallucination Mitigation in VLMs
Dec 26, 2025While Vision-Language Models (VLMs) have garnered increasing attention in the AI community due to their promising practical applications, they exhibit persistent hallucination issues, generating outputs misaligned with visual inputs. Recent studies attribute these hallucinations to VLMs' over-reliance on linguistic priors and insufficient visual feature integration, proposing heuristic decoding calibration strategies to mitigate them. However, the non-trainable nature of these strategies inherently limits their optimization potential. To this end, we propose an adversarial parametric editing framework for Hallucination mitigation in VLMs, which follows an \textbf{A}ctivate-\textbf{L}ocate-\textbf{E}dit \textbf{A}dversarially paradigm. Specifically, we first construct an activation dataset that comprises grounded responses (positive samples attentively anchored in visual features) and hallucinatory responses (negative samples reflecting LLM prior bias and internal knowledge artifacts). Next, we identify critical hallucination-prone parameter clusters by analyzing differential hidden states of response pairs. Then, these clusters are fine-tuned using prompts injected with adversarial tuned prefixes that are optimized to maximize visual neglect, thereby forcing the model to prioritize visual evidence over inherent parametric biases. Evaluations on both generative and discriminative VLM tasks demonstrate the significant effectiveness of ALEAHallu in alleviating hallucinations. Our code is available at https://github.com/hujiayu1223/ALEAHallu.
FullTransNet: Full Transformer with Local-Global Attention for Video Summarization
Jan 01, 2025Video summarization mainly aims to produce a compact, short, informative, and representative synopsis of raw videos, which is of great importance for browsing, analyzing, and understanding video content. Dominant video summarization approaches are generally based on recurrent or convolutional neural networks, even recent encoder-only transformers. We propose using full transformer as an alternative architecture to perform video summarization. The full transformer with an encoder-decoder structure, specifically designed for handling sequence transduction problems, is naturally suitable for video summarization tasks. This work considers supervised video summarization and casts it as a sequence-to-sequence learning problem. Our key idea is to directly apply the full transformer to the video summarization task, which is intuitively sound and effective. Also, considering the efficiency problem, we replace full attention with the combination of local and global sparse attention, which enables modeling long-range dependencies while reducing computational costs. Based on this, we propose a transformer-like architecture, named FullTransNet, which has a full encoder-decoder structure with local-global sparse attention for video summarization. Specifically, both the encoder and decoder in FullTransNet are stacked the same way as ones in the vanilla transformer, and the local-global sparse attention is used only at the encoder side. Extensive experiments on two public multimedia benchmark datasets SumMe and TVSum demonstrate that our proposed model can outperform other video summarization approaches, achieving F-Measures of 54.4% on SumMe and 63.9% on TVSum with relatively lower compute and memory requirements, verifying its effectiveness and efficiency. The code and models are publicly available on GitHub.
An Unbiased Risk Estimator for Partial Label Learning with Augmented Classes
Sep 29, 2024Partial Label Learning (PLL) is a typical weakly supervised learning task, which assumes each training instance is annotated with a set of candidate labels containing the ground-truth label. Recent PLL methods adopt identification-based disambiguation to alleviate the influence of false positive labels and achieve promising performance. However, they require all classes in the test set to have appeared in the training set, ignoring the fact that new classes will keep emerging in real applications. To address this issue, in this paper, we focus on the problem of Partial Label Learning with Augmented Class (PLLAC), where one or more augmented classes are not visible in the training stage but appear in the inference stage. Specifically, we propose an unbiased risk estimator with theoretical guarantees for PLLAC, which estimates the distribution of augmented classes by differentiating the distribution of known classes from unlabeled data and can be equipped with arbitrary PLL loss functions. Besides, we provide a theoretical analysis of the estimation error bound of the estimator, which guarantees the convergence of the empirical risk minimizer to the true risk minimizer as the number of training data tends to infinity. Furthermore, we add a risk-penalty regularization term in the optimization objective to alleviate the influence of the over-fitting issue caused by negative empirical risk. Extensive experiments on benchmark, UCI and real-world datasets demonstrate the effectiveness of the proposed approach.
A Hierarchical Interactive Network for Joint Span-based Aspect-Sentiment Analysis
Aug 24, 2022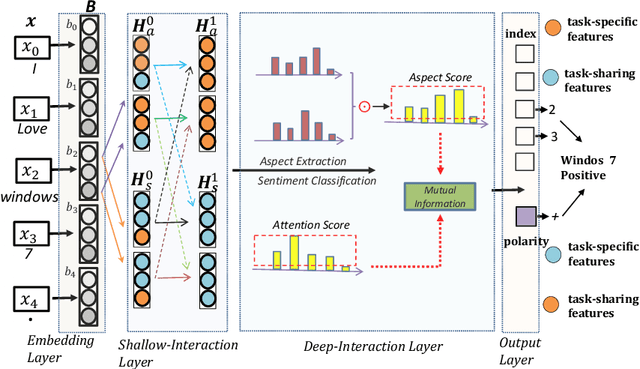
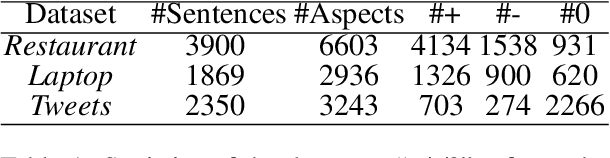
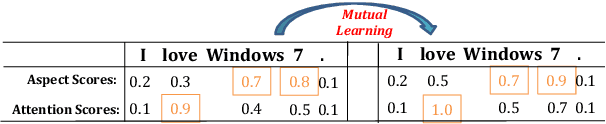
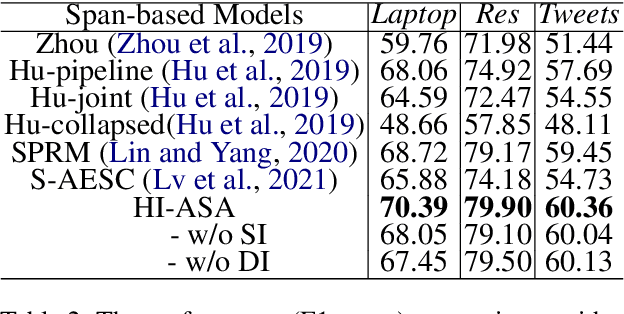
Recently, some span-based methods have achieved encouraging performances for joint aspect-sentiment analysis, which first extract aspects (aspect extraction) by detecting aspect boundaries and then classify the span-level sentiments (sentiment classification). However, most existing approaches either sequentially extract task-specific features, leading to insufficient feature interactions, or they encode aspect features and sentiment features in a parallel manner, implying that feature representation in each task is largely independent of each other except for input sharing. Both of them ignore the internal correlations between the aspect extraction and sentiment classification. To solve this problem, we novelly propose a hierarchical interactive network (HI-ASA) to model two-way interactions between two tasks appropriately, where the hierarchical interactions involve two steps: shallow-level interaction and deep-level interaction. First, we utilize cross-stitch mechanism to combine the different task-specific features selectively as the input to ensure proper two-way interactions. Second, the mutual information technique is applied to mutually constrain learning between two tasks in the output layer, thus the aspect input and the sentiment input are capable of encoding features of the other task via backpropagation. Extensive experiments on three real-world datasets demonstrate HI-ASA's superiority over baselines.
FHEDN: A based on context modeling Feature Hierarchy Encoder-Decoder Network for face detection
Dec 11, 2017

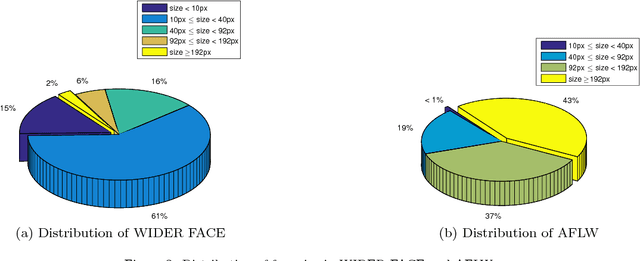
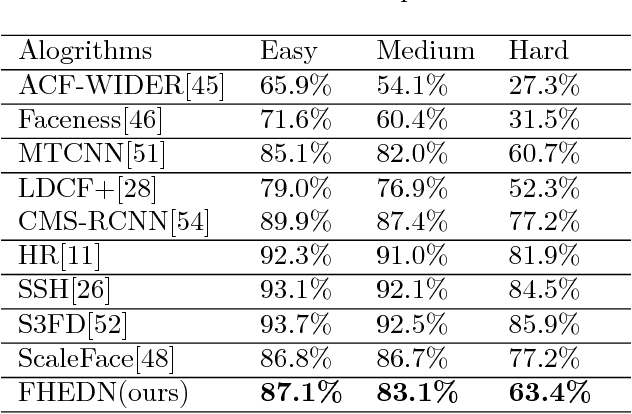
Because of affected by weather conditions, camera pose and range, etc. Objects are usually small, blur, occluded and diverse pose in the images gathered from outdoor surveillance cameras or access control system. It is challenging and important to detect faces precisely for face recognition system in the field of public security. In this paper, we design a based on context modeling structure named Feature Hierarchy Encoder-Decoder Network for face detection(FHEDN), which can detect small, blur and occluded face with hierarchy by hierarchy from the end to the beginning likes encoder-decoder in a single network. The proposed network is consist of multiple context modeling and prediction modules, which are in order to detect small, blur, occluded and diverse pose faces. In addition, we analyse the influence of distribution of training set, scale of default box and receipt field size to detection performance in implement stage. Demonstrated by experiments, Our network achieves promising performance on WIDER FACE and FDDB benchmarks.
A breakthrough in Speech emotion recognition using Deep Retinal Convolution Neural Networks
Jul 12, 2017
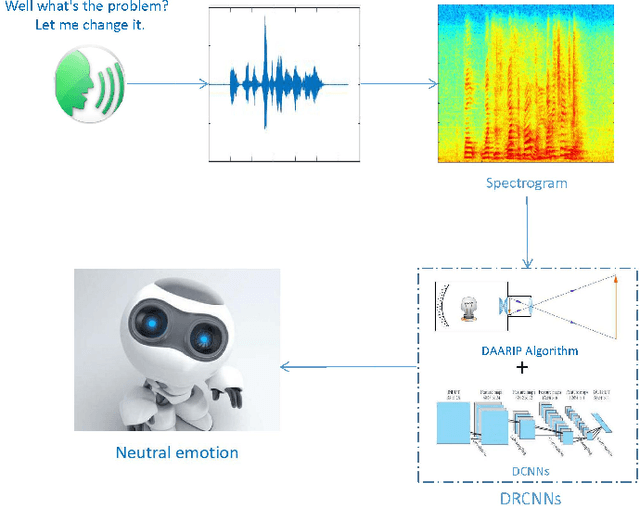


Speech emotion recognition (SER) is to study the formation and change of speaker's emotional state from the speech signal perspective, so as to make the interaction between human and computer more intelligent. SER is a challenging task that has encountered the problem of less training data and low prediction accuracy. Here we propose a data augmentation algorithm based on the imaging principle of the retina and convex lens, to acquire the different sizes of spectrogram and increase the amount of training data by changing the distance between the spectrogram and the convex lens. Meanwhile, with the help of deep learning to get the high-level features, we propose the Deep Retinal Convolution Neural Networks (DRCNNs) for SER and achieve the average accuracy over 99%. The experimental results indicate that DRCNNs outperforms the previous studies in terms of both the number of emotions and the accuracy of recognition. Predictably, our results will dramatically improve human-computer interaction.