 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Agent Human-LLM Collaborative Framework for Closed-Loop Scientific Literature Summarization
Apr 01, 2026Scientific discovery is slowed by fragmented literature that requires excessive human effort to gather, analyze, and understand. AI tools, including autonomous summarization and question answering, have been developed to aid in understanding scientific literature. However, these tools lack the structured, multi-step approach necessary for extracting deep insights from scientific literature. Large Language Models (LLMs) offer new possibilities for literature analysis, but remain unreliable due to hallucinations and incomplete extraction. We introduce Elhuyar, a multi-agent, human-in-the-loop system that integrates LLMs, structured AI, and human scientists to extract, analyze, and iteratively refine insights from scientific literature. The framework distributes tasks among specialized agents for filtering papers, extracting data, fitting models, and summarizing findings, with human oversight ensuring reliability. The system generates structured reports with extracted data, visualizations, model equations, and text summaries, enabling deeper inquiry through iterative refinement. Deployed in materials science, it analyzed literature on tungsten under helium-ion irradiation, showing experimentally correlated exponential helium bubble growth with irradiation dose and temperature, offering insight for plasma-facing materials (PFMs) in fusion reactors. This demonstrates how AI-assisted literature review can uncover scientific patterns and accelerate discovery.
Reducing Hallucinations in LLM-based Scientific Literature Analysis Using Peer Context Outlier Detection
Apr 01, 2026Reducing hallucinations in Large Language Models (LLMs) is essential for improving the accuracy of data extraction from large text corpora. Current methods, like prompt engineering and chain-of-thought prompting, focus on individual documents but fail to consider relationships across a corpus. This paper introduces Peer Context Outlier Detection (P-COD), a novel approach that uses the relationships between documents to improve extraction accuracy. Our application domain is in scientific literature summarization, where papers with similar experiment settings should draw similar conclusions. By comparing extracted data to validated peer information within the corpus, we adjust confidence scores and flag low-confidence results for expert review. High-confidence results, supported by peer validation, are considered reliable. Our experiments demonstrate up to 98% precision in outlier detection across 6 domains of science, demonstrating that our design reduces hallucinations, enhances trust in automated systems, and allows researchers to focus on ambiguous cases, streamlining the data extraction workflows.
Genetic Transformer-Assisted Quantum Neural Networks for Optimal Circuit Design
Jun 10, 2025We introduce Genetic Transformer Assisted Quantum Neural Networks (GTQNNs), a hybrid learning framework that combines a transformer encoder with a shallow variational quantum circuit and automatically fine tunes the circuit via the NSGA-II multi objective genetic algorithm. The transformer reduces high-dimensional classical data to a compact, qubit sized representation, while NSGA-II searches for Pareto optimal circuits that (i) maximize classification accuracy and (ii) minimize primitive gate count an essential constraint for noisy intermediate-scale quantum (NISQ) hardware. Experiments on four benchmarks (Iris, Breast Cancer, MNIST, and Heart Disease) show that GTQNNs match or exceed state of the art quantum models while requiring much fewer gates for most cases. A hybrid Fisher information analysis further reveals that the trained networks operate far from barren plateaus; the leading curvature directions increasingly align with the quantum subspace as the qubit budget grows, confirming that the transformer front end has effectively condensed the data. Together, these results demonstrate that GTQNNs deliver competitive performance with a quantum resource budget well suited to present-day NISQ devices.
Different thresholding methods on Nearest Shrunken Centroid algorithm
Dec 31, 2024This article considers the impact of different thresholding methods to the Nearest Shrunken Centroid algorithm, which is popularly referred as the Prediction Analysis of Microarrays (PAM) for high-dimensional classification. PAM uses soft thresholding to achieve high computational efficiency and high classification accuracy but in the price of retaining too many features. When applied to microarray human cancers, PAM selected 2611 features on average from 10 multi-class datasets. Such a large number of features make it difficult to perform follow up study. One reason behind this problem is the soft thresholding, which is known to produce biased parameter estimate in regression analysis. In this article, we extend the PAM algorithm with two other thresholding methods, hard and order thresholding, and a deep search algorithm to achieve better thresholding parameter estimate. The modified algorithms are extensively tested and compared to the original one based on real data and Monte Carlo studies. In general, the modification not only gave better cancer status prediction accuracy, but also resulted in more parsimonious models with significantly smaller number of features.
* 30 pages 9 figures
Matrix factorization and prediction for high dimensional co-occurrence count data via shared parameter alternating zero inflated Gamma model
Dec 31, 2024High-dimensional sparse matrix data frequently arise in various applications. A notable example is the weighted word-word co-occurrence count data, which summarizes the weighted frequency of word pairs appearing within the same context window. This type of data typically contains highly skewed non-negative values with an abundance of zeros. Another example is the co-occurrence of item-item or user-item pairs in e-commerce, which also generates high-dimensional data. The objective is to utilize this data to predict the relevance between items or users. In this paper, we assume that items or users can be represented by unknown dense vectors. The model treats the co-occurrence counts as arising from zero-inflated Gamma random variables and employs cosine similarity between the unknown vectors to summarize item-item relevance. The unknown values are estimated using the shared parameter alternating zero-inflated Gamma regression models (SA-ZIG). Both canonical link and log link models are considered. Two parameter updating schemes are proposed, along with an algorithm to estimate the unknown parameters. Convergence analysis is presented analytically. Numerical studies demonstrate that the SA-ZIG using Fisher scoring without learning rate adjustment may fail to fi nd the maximum likelihood estimate. However, the SA-ZIG with learning rate adjustment performs satisfactorily in our simulation studies.
Global dense vector representations for words or items using shared parameter alternating Tweedie model
Dec 31, 2024



In this article, we present a model for analyzing the cooccurrence count data derived from practical fields such as user-item or item-item data from online shopping platform, cooccurring word-word pairs in sequences of texts. Such data contain important information for developing recommender systems or studying relevance of items or words from non-numerical sources. Different from traditional regression models, there are no observations for covariates. Additionally, the cooccurrence matrix is typically of so high dimension that it does not fit into a computer's memory for modeling. We extract numerical data by defining windows of cooccurrence using weighted count on the continuous scale. Positive probability mass is allowed for zero observations. We present Shared parameter Alternating Tweedie (SA-Tweedie) model and an algorithm to estimate the parameters. We introduce a learning rate adjustment used along with the Fisher scoring method in the inner loop to help the algorithm stay on track of optimizing direction. Gradient descent with Adam update was also considered as an alternative method for the estimation. Simulation studies and an application showed that our algorithm with Fisher scoring and learning rate adjustment outperforms the other two methods. Pseudo-likelihood approach with alternating parameter update was also studied. Numerical studies showed that the pseudo-likelihood approach is not suitable in our shared parameter alternating regression models with unobserved covariates.
Cluster-Enhanced Federated Graph Neural Network for Recommendation
Dec 11, 2024Personal interaction data can be effectively modeled as individual graphs for each user in recommender systems.Graph Neural Networks (GNNs)-based recommendation techniques have become extremely popular since they can capture high-order collaborative signals between users and items by aggregating the individual graph into a global interactive graph.However, this centralized approach inherently poses a threat to user privacy and security. Recently, federated GNN-based recommendation techniques have emerged as a promising solution to mitigate privacy concerns. Nevertheless, current implementations either limit on-device training to an unaccompanied individual graphs or necessitate reliance on an extra third-party server to touch other individual graphs, which also increases the risk of privacy leakage. To address this challenge, we propose a Cluster-enhanced Federated Graph Neural Network framework for Recommendation, named CFedGR, which introduces high-order collaborative signals to augment individual graphs in a privacy preserving manner. Specifically, the server clusters the pretrained user representations to identify high-order collaborative signals. In addition, two efficient strategies are devised to reduce communication between devices and the server. Extensive experiments on three benchmark datasets validate the effectiveness of our proposed methods.
Multi-Agent Decision Transformers for Dynamic Dispatching in Material Handling Systems Leveraging Enterprise Big Data
Nov 04, 2024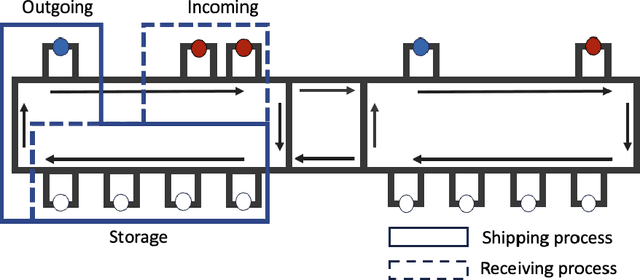

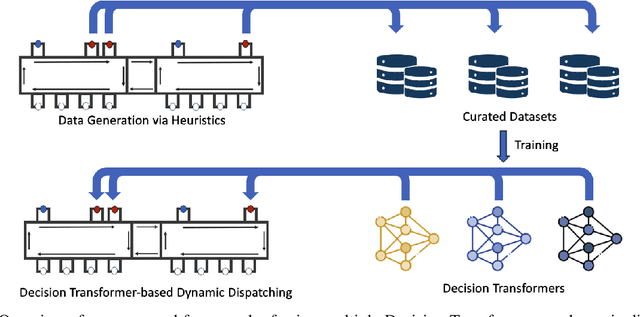
Dynamic dispatching rules that allocate resources to tasks in real-time play a critical role in ensuring efficient operations of many automated material handling systems across industries. Traditionally, the dispatching rules deployed are typically the result of manually crafted heuristics based on domain experts' knowledge. Generating these rules is time-consuming and often sub-optimal. As enterprises increasingly accumulate vast amounts of operational data, there is significant potential to leverage this big data to enhance the performance of automated systems. One promising approach is to use Decision Transformers, which can be trained on existing enterprise data to learn better dynamic dispatching rules for improving system throughput. In this work, we study the application of Decision Transformers as dynamic dispatching policies within an actual multi-agent material handling system and identify scenarios where enterprises can effectively leverage Decision Transformers on existing big data to gain business value. Our empirical results demonstrate that Decision Transformers can improve the material handling system's throughput by a considerable amount when the heuristic originally used in the enterprise data exhibits moderate performance and involves no randomness. When the original heuristic has strong performance, Decision Transformers can still improve the throughput but with a smaller improvement margin. However, when the original heuristics contain an element of randomness or when the performance of the dataset is below a certain threshold, Decision Transformers fail to outperform the original heuristic. These results highlight both the potential and limitations of Decision Transformers as dispatching policies for automated industrial material handling systems.
A Multi-Resolution Mutual Learning Network for Multi-Label ECG Classification
Jun 12, 2024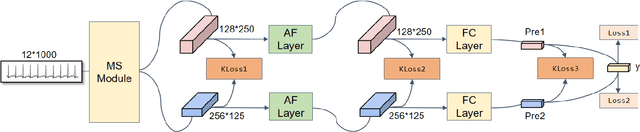
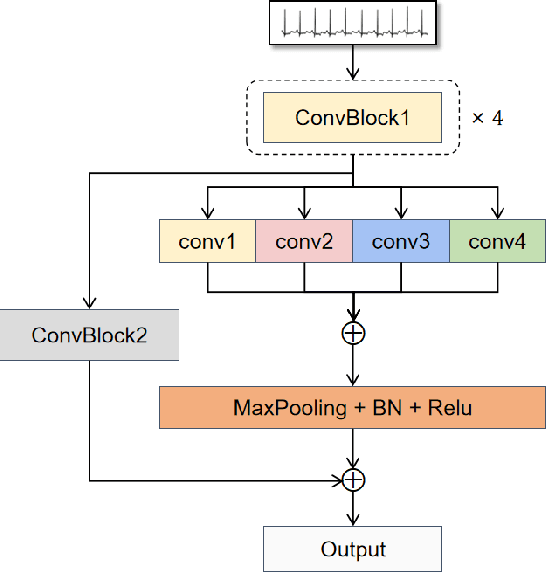
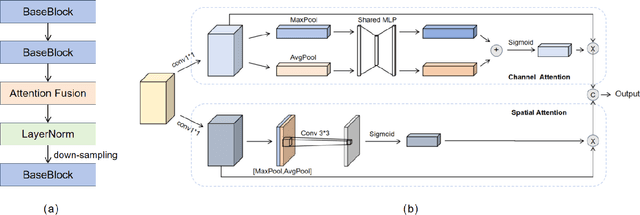
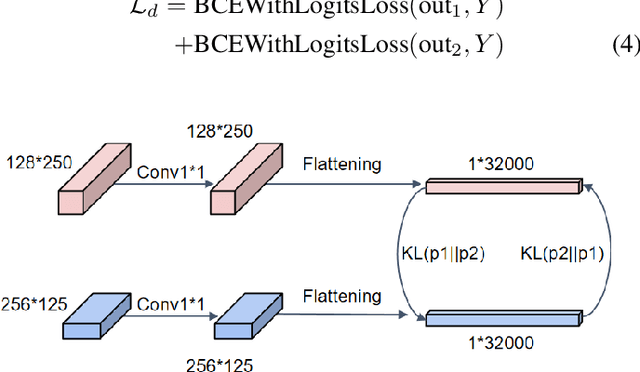
Electrocardiograms (ECG), which record the electrophysiological activity of the heart, have become a crucial tool for diagnosing these diseases. In recent years, the application of deep learning techniques has significantly improved the performance of ECG signal classification. Multi-resolution feature analysis, which captures and processes information at different time scales, can extract subtle changes and overall trends in ECG signals, showing unique advantages. However, common multi-resolution analysis methods based on simple feature addition or concatenation may lead to the neglect of low-resolution features, affecting model performance. To address this issue, this paper proposes the Multi-Resolution Mutual Learning Network (MRM-Net). MRM-Net includes a dual-resolution attention architecture and a feature complementary mechanism. The dual-resolution attention architecture processes high-resolution and low-resolution features in parallel. Through the attention mechanism, the high-resolution and low-resolution branches can focus on subtle waveform changes and overall rhythm patterns, enhancing the ability to capture critical features in ECG signals. Meanwhile, the feature complementary mechanism introduces mutual feature learning after each layer of the feature extractor. This allows features at different resolutions to reinforce each other, thereby reducing information loss and improving model performance and robustness. Experiments on the PTB-XL and CPSC2018 datasets demonstrate that MRM-Net significantly outperforms existing methods in multi-label ECG classification performance. The code for our framework will be publicly available at https://github.com/wxhdf/MRM.
Predictive Analysis for Optimizing Port Operations
Jan 25, 2024Maritime transport is a pivotal logistics mode for the long-distance and bulk transportation of goods. However, the intricate planning involved in this mode is often hindered by uncertainties, including weather conditions, cargo diversity, and port dynamics, leading to increased costs. Consequently, accurately estimating vessel total (stay) time at port and potential delays becomes imperative for effective planning and scheduling in port operations. This study aims to develop a port operation solution with competitive prediction and classification capabilities for estimating vessel Total and Delay times. This research addresses a significant gap in port analysis models for vessel Stay and Delay times, offering a valuable contribution to the field of maritime logistics. The proposed solution is designed to assist decision-making in port environments and predict service delays. This is demonstrated through a case study on Brazil ports. Additionally, feature analysis is used to understand the key factors impacting maritime logistics, enhancing the overall understanding of the complexities involved in port operations.