 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Quantized Federated Learning with Diverse Precision
Jul 01, 2025



Federated learning (FL) has emerged as a promising paradigm for distributed machine learning, enabling collaborative training of a global model across multiple local devices without requiring them to share raw data. Despite its advancements, FL is limited by factors such as: (i) privacy risks arising from the unprotected transmission of local model updates to the fusion center (FC) and (ii) decreased learning utility caused by heterogeneity in model quantization resolution across participating devices. Prior work typically addresses only one of these challenges because maintaining learning utility under both privacy risks and quantization heterogeneity is a non-trivial task. In this paper, our aim is therefore to improve the learning utility of a privacy-preserving FL that allows clusters of devices with different quantization resolutions to participate in each FL round. Specifically, we introduce a novel stochastic quantizer (SQ) that is designed to simultaneously achieve differential privacy (DP) and minimum quantization error. Notably, the proposed SQ guarantees bounded distortion, unlike other DP approaches. To address quantization heterogeneity, we introduce a cluster size optimization technique combined with a linear fusion approach to enhance model aggregation accuracy. Numerical simulations validate the benefits of our approach in terms of privacy protection and learning utility compared to the conventional LaplaceSQ-FL algorithm.
Global dense vector representations for words or items using shared parameter alternating Tweedie model
Dec 31, 2024



In this article, we present a model for analyzing the cooccurrence count data derived from practical fields such as user-item or item-item data from online shopping platform, cooccurring word-word pairs in sequences of texts. Such data contain important information for developing recommender systems or studying relevance of items or words from non-numerical sources. Different from traditional regression models, there are no observations for covariates. Additionally, the cooccurrence matrix is typically of so high dimension that it does not fit into a computer's memory for modeling. We extract numerical data by defining windows of cooccurrence using weighted count on the continuous scale. Positive probability mass is allowed for zero observations. We present Shared parameter Alternating Tweedie (SA-Tweedie) model and an algorithm to estimate the parameters. We introduce a learning rate adjustment used along with the Fisher scoring method in the inner loop to help the algorithm stay on track of optimizing direction. Gradient descent with Adam update was also considered as an alternative method for the estimation. Simulation studies and an application showed that our algorithm with Fisher scoring and learning rate adjustment outperforms the other two methods. Pseudo-likelihood approach with alternating parameter update was also studied. Numerical studies showed that the pseudo-likelihood approach is not suitable in our shared parameter alternating regression models with unobserved covariates.
Matrix factorization and prediction for high dimensional co-occurrence count data via shared parameter alternating zero inflated Gamma model
Dec 31, 2024High-dimensional sparse matrix data frequently arise in various applications. A notable example is the weighted word-word co-occurrence count data, which summarizes the weighted frequency of word pairs appearing within the same context window. This type of data typically contains highly skewed non-negative values with an abundance of zeros. Another example is the co-occurrence of item-item or user-item pairs in e-commerce, which also generates high-dimensional data. The objective is to utilize this data to predict the relevance between items or users. In this paper, we assume that items or users can be represented by unknown dense vectors. The model treats the co-occurrence counts as arising from zero-inflated Gamma random variables and employs cosine similarity between the unknown vectors to summarize item-item relevance. The unknown values are estimated using the shared parameter alternating zero-inflated Gamma regression models (SA-ZIG). Both canonical link and log link models are considered. Two parameter updating schemes are proposed, along with an algorithm to estimate the unknown parameters. Convergence analysis is presented analytically. Numerical studies demonstrate that the SA-ZIG using Fisher scoring without learning rate adjustment may fail to fi nd the maximum likelihood estimate. However, the SA-ZIG with learning rate adjustment performs satisfactorily in our simulation studies.
No Analog Combiner TTD-based Hybrid Precoding for Multi-User Sub-THz Communications
Jun 17, 2024

We address the design and optimization of real-world-suitable hybrid precoders for multi-user wideband sub-terahertz (sub-THz) communications. We note that the conventional fully connected true-time delay (TTD)-based architecture is impractical because there is no room for the required large number of analog signal combiners in the circuit board. Additionally, analog signal combiners incur significant signal power loss. These limitations are often overlooked in sub-THz research. To overcome these issues, we study a non-overlapping subarray architecture that eliminates the need for analog combiners. We extend the conventional single-user assumption by formulating an optimization problem to maximize the minimum data rate for simultaneously served users. This complex optimization problem is divided into two sub-problems. The first sub-problem aims to ensure a fair subarray allocation for all users and is solved via a continuous domain relaxation technique. The second sub-problem deals with practical TTD device constraints on range and resolution to maximize the subarray gain and is resolved by shifting to the phase domain. Our simulation results highlight significant performance gain for our real-world-ready TTD-based hybrid precoders.
Minimum Description Feature Selection for Complexity Reduction in Machine Learning-based Wireless Positioning
Apr 21, 2024



Recently, deep learning approaches have provided solutions to difficult problems in wireless positioning (WP). Although these WP algorithms have attained excellent and consistent performance against complex channel environments, the computational complexity coming from processing high-dimensional features can be prohibitive for mobile applications. In this work, we design a novel positioning neural network (P-NN) that utilizes the minimum description features to substantially reduce the complexity of deep learning-based WP. P-NN's feature selection strategy is based on maximum power measurements and their temporal locations to convey information needed to conduct WP. We improve P-NN's learning ability by intelligently processing two different types of inputs: sparse image and measurement matrices. Specifically, we implement a self-attention layer to reinforce the training ability of our network. We also develop a technique to adapt feature space size, optimizing over the expected information gain and the classification capability quantified with information-theoretic measures on signal bin selection. Numerical results show that P-NN achieves a significant advantage in performance-complexity tradeoff over deep learning baselines that leverage the full power delay profile (PDP). In particular, we find that P-NN achieves a large improvement in performance for low SNR, as unnecessary measurements are discarded in our minimum description features.
Complexity Reduction in Machine Learning-Based Wireless Positioning: Minimum Description Features
Feb 14, 2024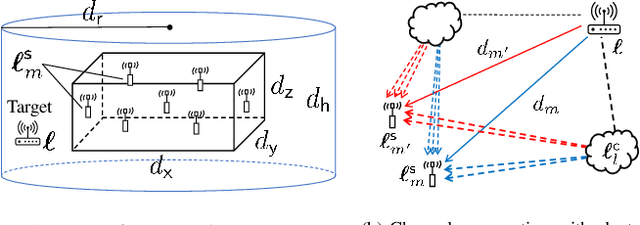
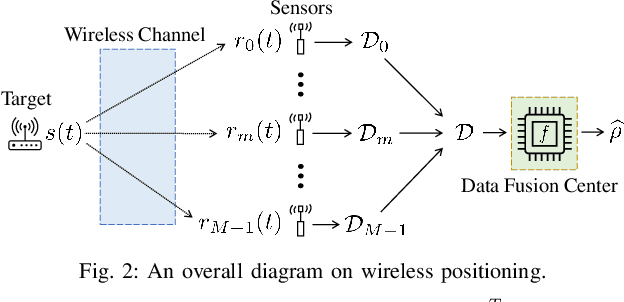
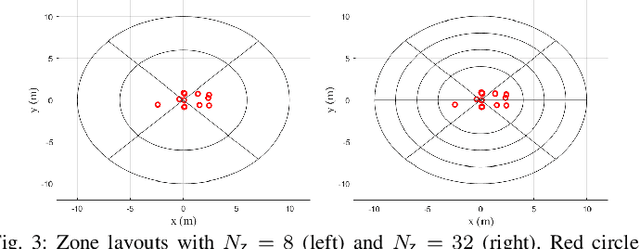
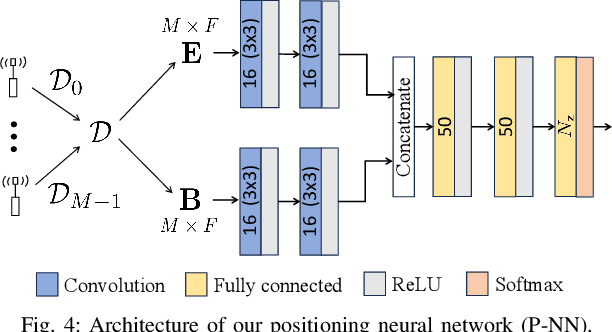
A recent line of research has been investigating deep learning approaches to wireless positioning (WP). Although these WP algorithms have demonstrated high accuracy and robust performance against diverse channel conditions, they also have a major drawback: they require processing high-dimensional features, which can be prohibitive for mobile applications. In this work, we design a positioning neural network (P-NN) that substantially reduces the complexity of deep learning-based WP through carefully crafted minimum description features. Our feature selection is based on maximum power measurements and their temporal locations to convey information needed to conduct WP. We also develop a novel methodology for adaptively selecting the size of feature space, which optimizes over balancing the expected amount of useful information and classification capability, quantified using information-theoretic measures on the signal bin selection. Numerical results show that P-NN achieves a significant advantage in performance-complexity tradeoff over deep learning baselines that leverage the full power delay profile (PDP).
Coding for Gaussian Two-Way Channels: Linear and Learning-Based Approaches
Dec 31, 2023



Although user cooperation cannot improve the capacity of Gaussian two-way channels (GTWCs) with independent noises, it can improve communication reliability. In this work, we aim to enhance and balance the communication reliability in GTWCs by minimizing the sum of error probabilities via joint design of encoders and decoders at the users. We first formulate general encoding/decoding functions, where the user cooperation is captured by the coupling of user encoding processes. The coupling effect renders the encoder/decoder design non-trivial, requiring effective decoding to capture this effect, as well as efficient power management at the encoders within power constraints. To address these challenges, we propose two different two-way coding strategies: linear coding and learning-based coding. For linear coding, we propose optimal linear decoding and discuss new insights on encoding regarding user cooperation to balance reliability. We then propose an efficient algorithm for joint encoder/decoder design. For learning-based coding, we introduce a novel recurrent neural network (RNN)-based coding architecture, where we propose interactive RNNs and a power control layer for encoding, and we incorporate bi-directional RNNs with an attention mechanism for decoding. Through simulations, we show that our two-way coding methodologies outperform conventional channel coding schemes (that do not utilize user cooperation) significantly in sum-error performance. We also demonstrate that our linear coding excels at high signal-to-noise ratios (SNRs), while our RNN-based coding performs best at low SNRs. We further investigate our two-way coding strategies in terms of power distribution, two-way coding benefit, different coding rates, and block-length gain.
On The Stability of Approximate Message Passing with Independent Measurement Ensembles
May 16, 2023Approximate message passing (AMP) is a scalable, iterative approach to signal recovery. For structured random measurement ensembles, including independent and identically distributed (i.i.d.) Gaussian and rotationally-invariant matrices, the performance of AMP can be characterized by a scalar recursion called state evolution (SE). The pseudo-Lipschitz (polynomial) smoothness is conventionally assumed. In this work, we extend the SE for AMP to a new class of measurement matrices with independent (not necessarily identically distributed) entries. We also extend it to a general class of functions, called controlled functions which are not constrained by the polynomial smoothness; unlike the pseudo-Lipschitz function that has polynomial smoothness, the controlled function grows exponentially. The lack of structure in the assumed measurement ensembles is addressed by leveraging Lindeberg-Feller. The lack of smoothness of the assumed controlled function is addressed by a proposed conditioning technique leveraging the empirical statistics of the AMP instances. The resultants grant the use of the SE to a broader class of measurement ensembles and a new class of functions.
Dynamic and Robust Sensor Selection Strategies for Wireless Positioning with TOA/RSS Measurement
Apr 30, 2023



Emerging wireless applications are requiring ever more accurate location-positioning from sensor measurements. In this paper, we develop sensor selection strategies for 3D wireless positioning based on time of arrival (TOA) and received signal strength (RSS) measurements to handle two distinct scenarios: (i) known approximated target location, for which we conduct dynamic sensor selection to minimize the positioning error; and (ii) unknown approximated target location, in which the worst-case positioning error is minimized via robust sensor selection. We derive expressions for the Cram\'er-Rao lower bound (CRLB) as a performance metric to quantify the positioning accuracy resulted from selected sensors. For dynamic sensor selection, two greedy selection strategies are proposed, each of which exploits properties revealed in the derived CRLB expressions. These selection strategies are shown to strike an efficient balance between computational complexity and performance suboptimality. For robust sensor selection, we show that the conventional convex relaxation approach leads to instability, and then develop three algorithms based on (i) iterative convex optimization (ICO), (ii) difference of convex functions programming (DCP), and (iii) discrete monotonic optimization (DMO). Each of these strategies exhibits a different tradeoff between computational complexity and optimality guarantee. Simulation results show that the proposed sensor selection strategies provide significant improvements in terms of accuracy and/or complexity compared to existing sensor selection methods.
Robust Non-Linear Feedback Coding via Power-Constrained Deep Learning
Apr 25, 2023



The design of codes for feedback-enabled communications has been a long-standing open problem. Recent research on non-linear, deep learning-based coding schemes have demonstrated significant improvements in communication reliability over linear codes, but are still vulnerable to the presence of forward and feedback noise over the channel. In this paper, we develop a new family of non-linear feedback codes that greatly enhance robustness to channel noise. Our autoencoder-based architecture is designed to learn codes based on consecutive blocks of bits, which obtains de-noising advantages over bit-by-bit processing to help overcome the physical separation between the encoder and decoder over a noisy channel. Moreover, we develop a power control layer at the encoder to explicitly incorporate hardware constraints into the learning optimization, and prove that the resulting average power constraint is satisfied asymptotically. Numerical experiments demonstrate that our scheme outperforms state-of-the-art feedback codes by wide margins over practical forward and feedback noise regimes, and provide information-theoretic insights on the behavior of our non-linear codes. Moreover, we observe that, in a long blocklength regime, canonical error correction codes are still preferable to feedback codes when the feedback noise becomes high.