 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsensus-based Decentralized Multi-agent Reinforcement Learning for Random Access Network Optimization
Aug 09, 2025With wireless devices increasingly forming a unified smart network for seamless, user-friendly operations, random access (RA) medium access control (MAC) design is considered a key solution for handling unpredictable data traffic from multiple terminals. However, it remains challenging to design an effective RA-based MAC protocol to minimize collisions and ensure transmission fairness across the devices. While existing multi-agent reinforcement learning (MARL) approaches with centralized training and decentralized execution (CTDE) have been proposed to optimize RA performance, their reliance on centralized training and the significant overhead required for information collection can make real-world applications unrealistic. In this work, we adopt a fully decentralized MARL architecture, where policy learning does not rely on centralized tasks but leverages consensus-based information exchanges across devices. We design our MARL algorithm over an actor-critic (AC) network and propose exchanging only local rewards to minimize communication overhead. Furthermore, we provide a theoretical proof of global convergence for our approach. Numerical experiments show that our proposed MARL algorithm can significantly improve RA network performance compared to other baselines.
Finite-Time Global Optimality Convergence in Deep Neural Actor-Critic Methods for Decentralized Multi-Agent Reinforcement Learning
May 24, 2025Actor-critic methods for decentralized multi-agent reinforcement learning (MARL) facilitate collaborative optimal decision making without centralized coordination, thus enabling a wide range of applications in practice. To date, however, most theoretical convergence studies for existing actor-critic decentralized MARL methods are limited to the guarantee of a stationary solution under the linear function approximation. This leaves a significant gap between the highly successful use of deep neural actor-critic for decentralized MARL in practice and the current theoretical understanding. To bridge this gap, in this paper, we make the first attempt to develop a deep neural actor-critic method for decentralized MARL, where both the actor and critic components are inherently non-linear. We show that our proposed method enjoys a global optimality guarantee with a finite-time convergence rate of O(1/T), where T is the total iteration times. This marks the first global convergence result for deep neural actor-critic methods in the MARL literature. We also conduct extensive numerical experiments, which verify our theoretical results.
Minimum Description Feature Selection for Complexity Reduction in Machine Learning-based Wireless Positioning
Apr 21, 2024



Recently, deep learning approaches have provided solutions to difficult problems in wireless positioning (WP). Although these WP algorithms have attained excellent and consistent performance against complex channel environments, the computational complexity coming from processing high-dimensional features can be prohibitive for mobile applications. In this work, we design a novel positioning neural network (P-NN) that utilizes the minimum description features to substantially reduce the complexity of deep learning-based WP. P-NN's feature selection strategy is based on maximum power measurements and their temporal locations to convey information needed to conduct WP. We improve P-NN's learning ability by intelligently processing two different types of inputs: sparse image and measurement matrices. Specifically, we implement a self-attention layer to reinforce the training ability of our network. We also develop a technique to adapt feature space size, optimizing over the expected information gain and the classification capability quantified with information-theoretic measures on signal bin selection. Numerical results show that P-NN achieves a significant advantage in performance-complexity tradeoff over deep learning baselines that leverage the full power delay profile (PDP). In particular, we find that P-NN achieves a large improvement in performance for low SNR, as unnecessary measurements are discarded in our minimum description features.
Complexity Reduction in Machine Learning-Based Wireless Positioning: Minimum Description Features
Feb 14, 2024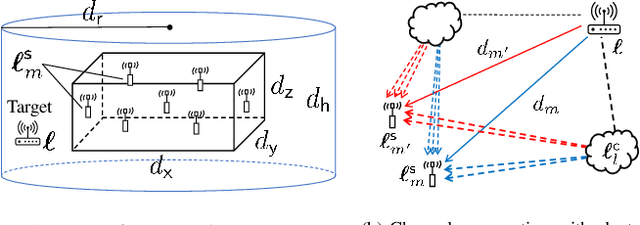
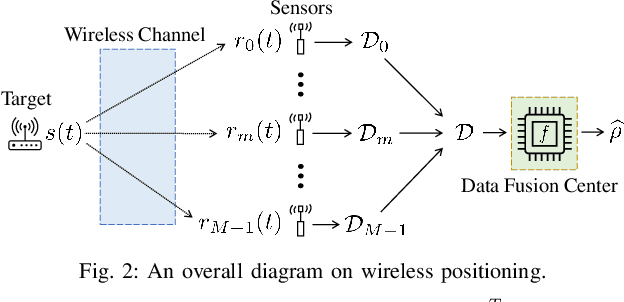
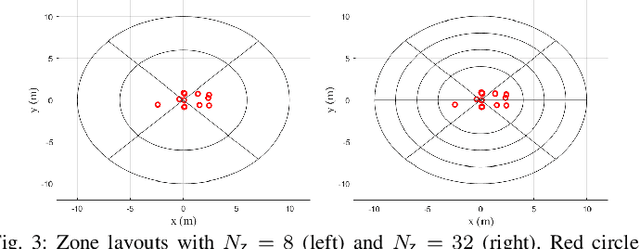
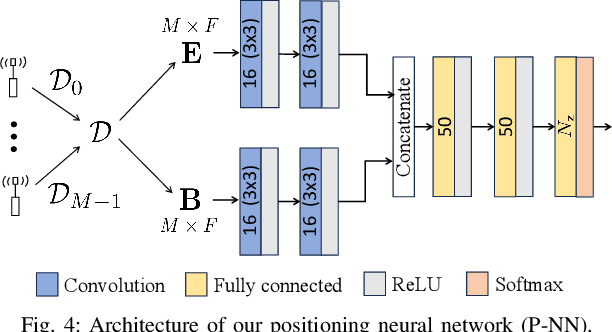
A recent line of research has been investigating deep learning approaches to wireless positioning (WP). Although these WP algorithms have demonstrated high accuracy and robust performance against diverse channel conditions, they also have a major drawback: they require processing high-dimensional features, which can be prohibitive for mobile applications. In this work, we design a positioning neural network (P-NN) that substantially reduces the complexity of deep learning-based WP through carefully crafted minimum description features. Our feature selection is based on maximum power measurements and their temporal locations to convey information needed to conduct WP. We also develop a novel methodology for adaptively selecting the size of feature space, which optimizes over balancing the expected amount of useful information and classification capability, quantified using information-theoretic measures on the signal bin selection. Numerical results show that P-NN achieves a significant advantage in performance-complexity tradeoff over deep learning baselines that leverage the full power delay profile (PDP).
Dynamic and Robust Sensor Selection Strategies for Wireless Positioning with TOA/RSS Measurement
Apr 30, 2023



Emerging wireless applications are requiring ever more accurate location-positioning from sensor measurements. In this paper, we develop sensor selection strategies for 3D wireless positioning based on time of arrival (TOA) and received signal strength (RSS) measurements to handle two distinct scenarios: (i) known approximated target location, for which we conduct dynamic sensor selection to minimize the positioning error; and (ii) unknown approximated target location, in which the worst-case positioning error is minimized via robust sensor selection. We derive expressions for the Cram\'er-Rao lower bound (CRLB) as a performance metric to quantify the positioning accuracy resulted from selected sensors. For dynamic sensor selection, two greedy selection strategies are proposed, each of which exploits properties revealed in the derived CRLB expressions. These selection strategies are shown to strike an efficient balance between computational complexity and performance suboptimality. For robust sensor selection, we show that the conventional convex relaxation approach leads to instability, and then develop three algorithms based on (i) iterative convex optimization (ICO), (ii) difference of convex functions programming (DCP), and (iii) discrete monotonic optimization (DMO). Each of these strategies exhibits a different tradeoff between computational complexity and optimality guarantee. Simulation results show that the proposed sensor selection strategies provide significant improvements in terms of accuracy and/or complexity compared to existing sensor selection methods.
A Decentralized Pilot Assignment Methodology for Scalable O-RAN Cell-Free Massive MIMO
Jan 12, 2023



Radio access networks (RANs) in monolithic architectures have limited adaptability to supporting different network scenarios. Recently, open-RAN (O-RAN) techniques have begun adding enormous flexibility to RAN implementations. O-RAN is a natural architectural fit for cell-free massive multiple-input multiple-output (CFmMIMO) systems, where many geographically-distributed access points (APs) are employed to achieve ubiquitous coverage and enhanced user performance. In this paper, we address the decentralized pilot assignment (PA) problem for scalable O-RAN-based CFmMIMO systems. We propose a low-complexity PA scheme using a multi-agent deep reinforcement learning (MA-DRL) framework in which multiple learning agents perform distributed learning over the O-RAN communication architecture to suppress pilot contamination. Our approach does not require prior channel knowledge but instead relies on real-time interactions made with the environment during the learning procedure. In addition, we design a codebook search (CS) scheme that exploits the decentralization of our O-RAN CFmMIMO architecture, where different codebook sets can be utilized to further improve PA performance without any significant additional complexities. Numerical evaluations verify that our proposed scheme provides substantial computational scalability advantages and improvements in channel estimation performance compared to the state-of-the-art.
Channel Estimation via Successive Denoising in MIMO OFDM Systems: A Reinforcement Learning Approach
Feb 15, 2021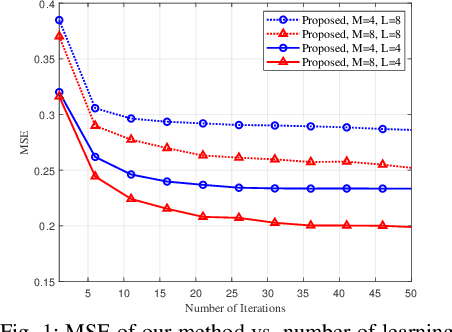

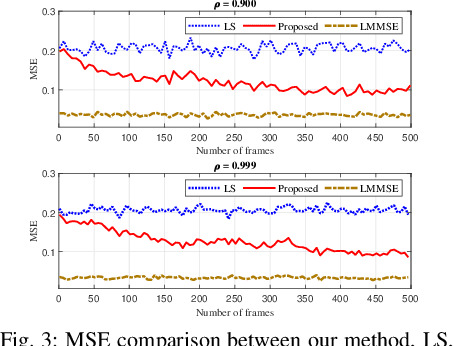
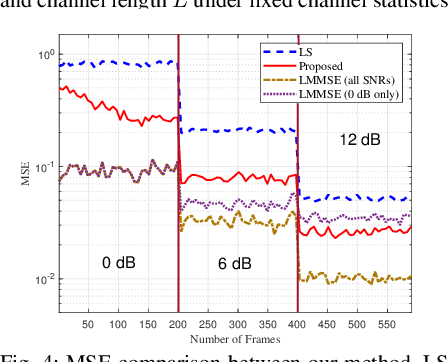
Reliable communication through multiple-input multiple-output (MIMO) orthogonal frequency division multiplexing (OFDM) requires accurate channel estimation. Existing literature largely focuses on denoising methods for channel estimation that are dependent on either (i) channel analysis in the time-domain, and/or (ii) supervised learning techniques, requiring large pre-labeled datasets for training. To address these limitations, we present a frequency-domain denoising method based on the application of a reinforcement learning framework that does not need a priori channel knowledge and pre-labeled data. Our methodology includes a new successive channel denoising process based on channel curvature computation, for which we obtain a channel curvature magnitude threshold to identify unreliable channel estimates. Based on this process, we formulate the denoising mechanism as a Markov decision process, where we define the actions through a geometry-based channel estimation update, and the reward function based on a policy that reduces the MSE. We then resort to Q-learning to update the channel estimates over the time instances. Numerical results verify that our denoising algorithm can successfully mitigate noise in channel estimates. In particular, our algorithm provides a significant improvement over the practical least squares (LS) channel estimation method and provides performance that approaches that of the ideal linear minimum mean square error (LMMSE) with perfect knowledge of channel statistics.