 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Memory Agents: Heterogeneous Multi-Agent LLM Systems through Structured Contextual Memory
Aug 12, 2025Multi-agent systems built on Large Language Models (LLMs) show exceptional promise for complex collaborative problem-solving, yet they face fundamental challenges stemming from context window limitations that impair memory consistency, role adherence, and procedural integrity. This paper introduces Intrinsic Memory Agents, a novel framework that addresses these limitations through structured agent-specific memories that evolve intrinsically with agent outputs. Specifically, our method maintains role-aligned memory templates that preserve specialized perspectives while focusing on task-relevant information. We benchmark our approach on the PDDL dataset, comparing its performance to existing state-of-the-art multi-agentic memory approaches and showing an improvement of 38.6\% with the highest token efficiency. An additional evaluation is performed on a complex data pipeline design task, we demonstrate that our approach produces higher quality designs when comparing 5 metrics: scalability, reliability, usability, cost-effectiveness and documentation with additional qualitative evidence of the improvements. Our findings suggest that addressing memory limitations through structured, intrinsic approaches can improve the capabilities of multi-agent LLM systems on structured planning tasks.
Automatic Dataset Generation for Knowledge Intensive Question Answering Tasks
May 20, 2025A question-answering (QA) system is to search suitable answers within a knowledge base. Current QA systems struggle with queries requiring complex reasoning or real-time knowledge integration. They are often supplemented with retrieval techniques on a data source such as Retrieval-Augmented Generation (RAG). However, RAG continues to face challenges in handling complex reasoning and logical connections between multiple sources of information. A novel approach for enhancing Large Language Models (LLMs) in knowledge-intensive QA tasks is presented through the automated generation of context-based QA pairs. This methodology leverages LLMs to create fine-tuning data, reducing reliance on human labelling and improving model comprehension and reasoning capabilities. The proposed system includes an automated QA generator and a model fine-tuner, evaluated using perplexity, ROUGE, BLEU, and BERTScore. Comprehensive experiments demonstrate improvements in logical coherence and factual accuracy, with implications for developing adaptable Artificial Intelligence (AI) systems. Mistral-7b-v0.3 outperforms Llama-3-8b with BERT F1, BLEU, and ROUGE scores 0.858, 0.172, and 0.260 of for the LLM generated QA pairs compared to scores of 0.836, 0.083, and 0.139 for the human annotated QA pairs.
Speaking Your Language: Spatial Relationships in Interpretable Emergent Communication
Jun 11, 2024


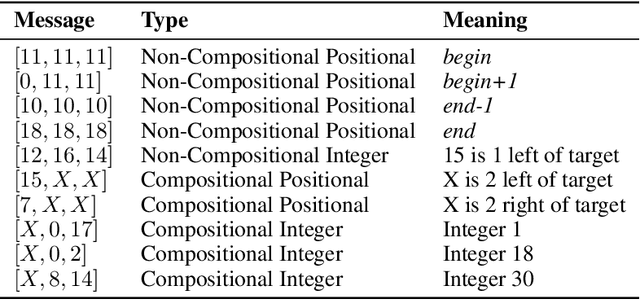
Effective communication requires the ability to refer to specific parts of an observation in relation to others. While emergent communication literature shows success in developing various language properties, no research has shown the emergence of such positional references. This paper demonstrates how agents can communicate about spatial relationships within their observations. The results indicate that agents can develop a language capable of expressing the relationships between parts of their observation, achieving over 90% accuracy when trained in a referential game which requires such communication. Using a collocation measure, we demonstrate how the agents create such references. This analysis suggests that agents use a mixture of non-compositional and compositional messages to convey spatial relationships. We also show that the emergent language is interpretable by humans. The translation accuracy is tested by communicating with the receiver agent, where the receiver achieves over 78% accuracy using parts of this lexicon, confirming that the interpretation of the emergent language was successful.
Agent based modelling for continuously varying supply chains
Dec 24, 2023Problem definition: Supply chains are constantly evolving networks. Reinforcement learning is increasingly proposed as a solution to provide optimal control of these networks. Academic/practical: However, learning in continuously varying environments remains a challenge in the reinforcement learning literature.Methodology: This paper therefore seeks to address whether agents can control varying supply chain problems, transferring learning between environments that require different strategies and avoiding catastrophic forgetting of tasks that have not been seen in a while. To evaluate this approach, two state-of-the-art Reinforcement Learning (RL) algorithms are compared: an actor-critic learner, Proximal Policy Optimisation(PPO), and a Recurrent Proximal Policy Optimisation (RPPO), PPO with a Long Short-Term Memory(LSTM) layer, which is showing popularity in online learning environments. Results: First these methods are compared on six sets of environments with varying degrees of stochasticity. The results show that more lean strategies adopted in Batch environments are different from those adopted in Stochastic environments with varying products. The methods are also compared on various continuous supply chain scenarios, where the PPO agents are shown to be able to adapt through continuous learning when the tasks are similar but show more volatile performance when changing between the extreme tasks. However, the RPPO, with an ability to remember histories, is able to overcome this to some extent and takes on a more realistic strategy. Managerial implications: Our results provide a new perspective on the continuously varying supply chain, the cooperation and coordination of agents are crucial for improving the overall performance in uncertain and semi-continuous non-stationary supply chain environments without the need to retrain the environment as the demand changes.
On Temporal References in Emergent Communication
Oct 10, 2023


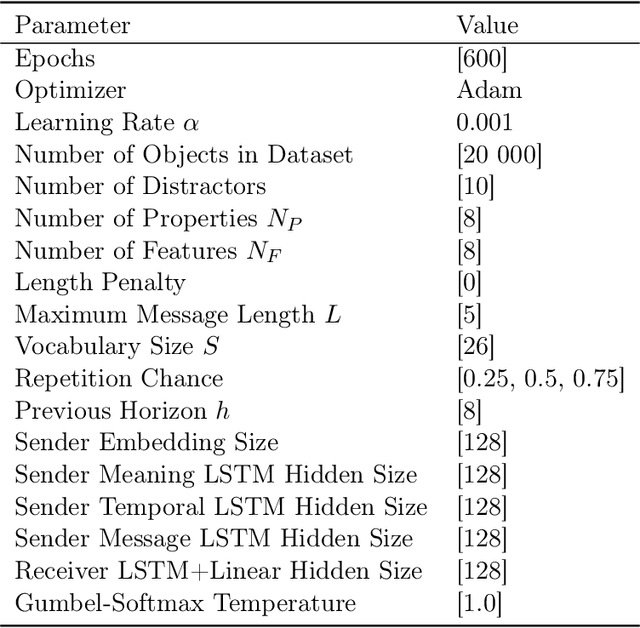
As humans, we use linguistic elements referencing time, such as before or tomorrow, to easily share past experiences and future predictions. While temporal aspects of the language have been considered in computational linguistics, no such exploration has been done within the field of emergent communication. We research this gap, providing the first reported temporal vocabulary within emergent communication literature. Our experimental analysis shows that a different agent architecture is sufficient for the natural emergence of temporal references, and that no additional losses are necessary. Our readily transferable architectural insights provide the basis for the incorporation of temporal referencing into other emergent communication environments.
The Effect of Epigenetic Blocking on Dynamic Multi-Objective Optimisation Problems
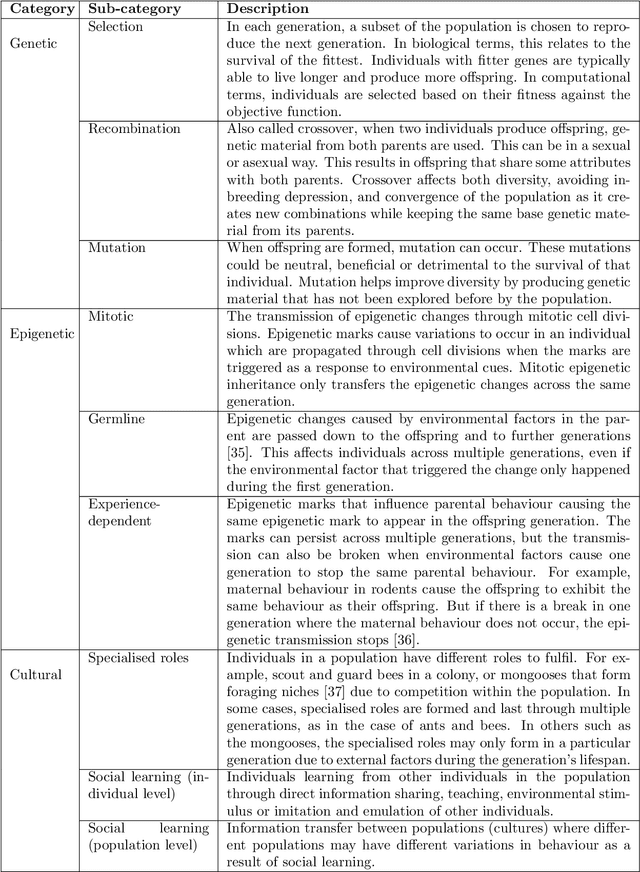
Nov 25, 2022Hundreds of Evolutionary Computation approaches have been reported. From an evolutionary perspective they focus on two fundamental mechanisms: cultural inheritance in Swarm Intelligence and genetic inheritance in Evolutionary Algorithms. Contemporary evolutionary biology looks beyond genetic inheritance, proposing a so-called ``Extended Evolutionary Synthesis''. Many concepts from the Extended Evolutionary Synthesis have been left out of Evolutionary Computation as interest has moved toward specific implementations of the same general mechanisms. One such concept is epigenetic inheritance, which is increasingly considered central to evolutionary thinking. Epigenetic mechanisms allow quick non- or partially-genetic adaptations to environmental changes. Dynamic multi-objective optimisation problems represent similar circumstances to the natural world where fitness can be determined by multiple objectives (traits), and the environment is constantly changing. This paper asks if the advantages that epigenetic inheritance provide in the natural world are replicated in dynamic multi-objective optimisation problems. Specifically, an epigenetic blocking mechanism is applied to a state-of-the-art multi-objective genetic algorithm, MOEA/D-DE, and its performance is compared on three sets of dynamic test functions, FDA, JY, and UDF. The mechanism shows improved performance on 12 of the 16 test problems, providing initial evidence that more algorithms should explore the wealth of epigenetic mechanisms seen in the natural world.
Epigenetic opportunities for Evolutionary Computation
Aug 10, 2021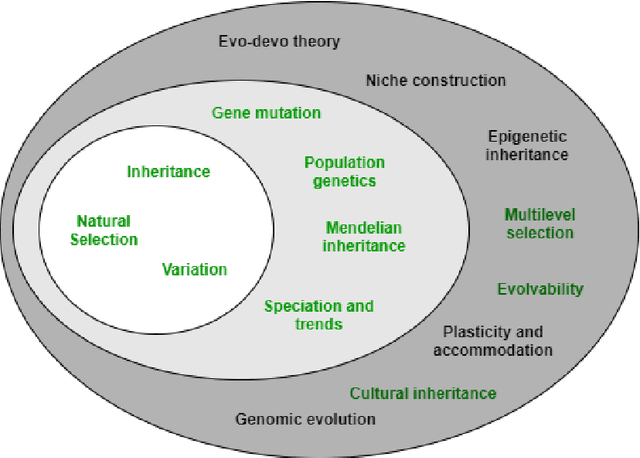
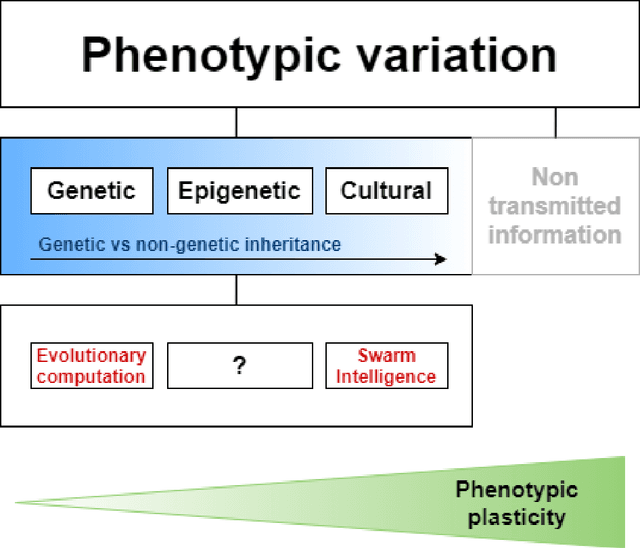
Evolutionary Computation is a group of biologically inspired algorithms used to solve complex optimisation problems. It can be split into Evolutionary Algorithms, which take inspiration from genetic inheritance, and Swarm Intelligence algorithms, that take inspiration from cultural inheritance. However, recent developments have focused on computational or mathematical adaptions, leaving their biological roots behind. This has left much of the modern evolutionary literature relatively unexplored. To understand which evolutionary mechanisms have been considered, and which have been overlooked, this paper breaks down successful bio-inspired algorithms under a contemporary biological framework based on the Extended Evolutionary Synthesis, an extension of the classical, genetics focussed, Modern Synthesis. The analysis shows that Darwinism and the Modern Synthesis have been incorporated into Evolutionary Computation but that the Extended Evolutionary Synthesis has been broadly ignored beyond:cultural inheritance, incorporated in the sub-set of Swarm Intelligence algorithms, evolvability, through CMA-ES, and multilevel selection, through Multi-Level Selection Genetic Algorithm. The framework shows a missing gap in epigenetic inheritance for Evolutionary Computation, despite being a key building block in modern interpretations of how evolution occurs. Epigenetic inheritance can explain fast adaptation, without changes in an individual's genotype, by allowing biological organisms to self-adapt quickly to environmental cues, which, increases the speed of convergence while maintaining stability in changing environments. This leaves a diverse range of biologically inspired mechanisms as low hanging fruit that should be explored further within Evolutionary Computation.
Lifetime policy reuse and the importance of task capacity
Jun 03, 2021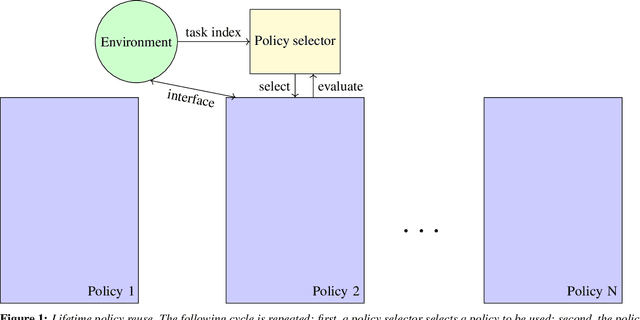
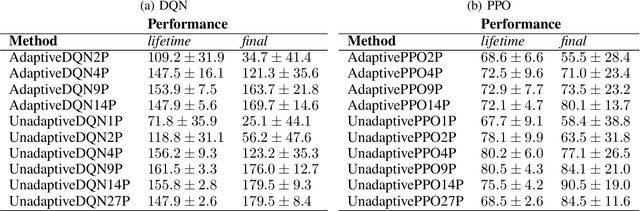
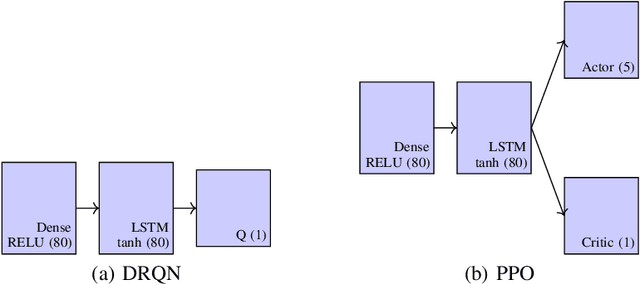
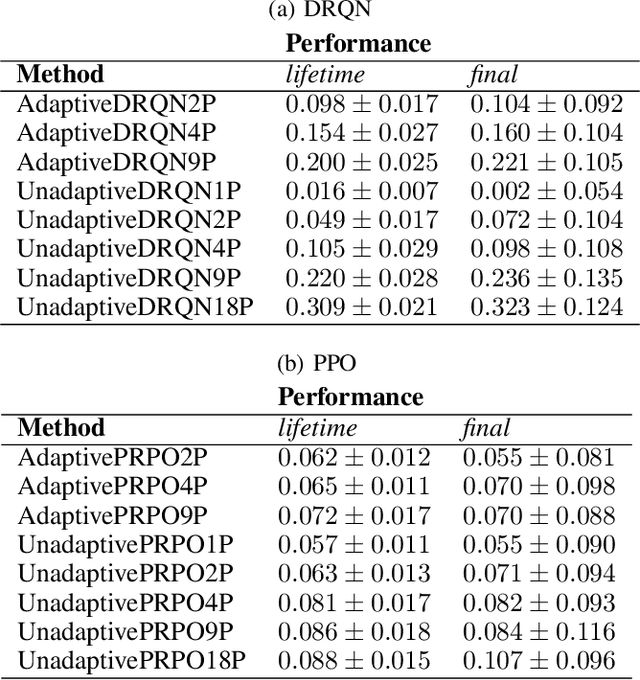
A long-standing challenge in artificial intelligence is lifelong learning. In lifelong learning, many tasks are presented in sequence and learners must efficiently transfer knowledge between tasks while avoiding catastrophic forgetting over long lifetimes. On these problems, policy reuse and other multi-policy reinforcement learning techniques can learn many tasks. However, they can generate many temporary or permanent policies, resulting in memory issues. Consequently, there is a need for lifetime-scalable methods that continually refine a policy library of a pre-defined size. This paper presents a first approach to lifetime-scalable policy reuse. To pre-select the number of policies, a notion of task capacity, the maximal number of tasks that a policy can accurately solve, is proposed. To evaluate lifetime policy reuse using this method, two state-of-the-art single-actor base-learners are compared: 1) a value-based reinforcement learner, Deep Q-Network (DQN) or Deep Recurrent Q-Network (DRQN); and 2) an actor-critic reinforcement learner, Proximal Policy Optimisation (PPO) with or without Long Short-Term Memory layer. By selecting the number of policies based on task capacity, D(R)QN achieves near-optimal performance with 6 policies in a 27-task MDP domain and 9 policies in an 18-task POMDP domain; with fewer policies, catastrophic forgetting and negative transfer are observed. Due to slow, monotonic improvement, PPO requires fewer policies, 1 policy for the 27-task domain and 4 policies for the 18-task domain, but it learns the tasks with lower accuracy than D(R)QN. These findings validate lifetime-scalable policy reuse and suggest using D(R)QN for larger and PPO for smaller library sizes.